原文:
Houston, Ben, Mark Wiebe, and Chris Batty. “RLE sparse level sets.” ACM SIGGRAPH 2004 Sketches. 2004. 137.
只有一页,这就是技术草案的含金量吗
RLE 稀疏水平集
run-length encoded, RLE 游程编码
为什么 run-length 会被翻译为游程
我理解它把连续的重复出现的数字编码成 值+出现次数 的思想
但是还是理解不了这个翻译
只能把 run 理解为 值 - 出现次数 的 pair
或许这个 pair 就被称为游程
RLE 稀疏水平集表示具有许多有益的特性:
(1)高度可扩展,
(2)快速随机访问,
(3)窄带的顺序遍历是最佳的,
(4)在整个包围体中提供近似距离值,
(5)易于适应大多数为常规网格结构开发的现有水平集方法。
这些优点并不都是八叉树、稀疏域方法或稀疏块网格可扩展水平集表示所共有的(在 [Bridson 2003] 中进行了评论)。
随机访问
实现:
-
在每行开始时重新启动 RLE
-
将两个表添加到 RLE 结构中
run-start table 游程起点表 将每个游程与其沿压缩轴的起始体素坐标相关联
第二个表将其他两个轴的体素坐标与相应游程长度编码行的第一游程相关联
那么随机访问的过程是
-
使用上述第二个表查找与感兴趣的行相对应的 run-start table 中的段
-
如果这个游程已经被定义的话,对 run-start table 的已识别段使用二分搜索来查找感兴趣的游程
-
使用游程数据起始偏移量来确定体素值的数据索引。因此,随机访问时间减少到 O(log r) 而不是 O®,其中 r 是单行中的平均运行次数,R 是运行总数。
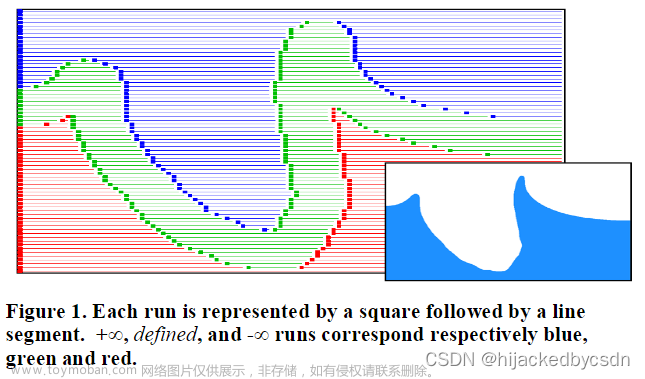
水平集游程类型
定义三种类型,有定义、正无穷、负无穷
如果是窄带水平集,有定义对应窄带之内,正无穷对应 SDF 值大于宽度,负无穷对应 SDF 值小于宽度的负数
需要注意的是,定义的运行类型与所有其他运行类型的不同之处在于,此类表示的单元格的值显式存储在关联的平面值数组中。
他这句话的意思应该就是,”有定义“就是表示有实际对应的值?
编码
构建 RLE 稀疏场结构的空间和时间复杂度均为 O(n^2 +R+D),其中 n 是包围体的边长,D 是定义的体素总数。
假设在任何 O(n^3 ) 网格中,只有 O(n^2 ) 个单元靠近表面,就像足够光滑的几何形状的情况一样,RLE 稀疏场结构的缩放比例接近最优的,O(n^2 + R)的,空间和时间成本
不确定他是不是说的”最优的,O(n^2 + R)的成本“
CSG 操作
当输入 RLE 稀疏水平集的编码轴匹配时,仅使用 O(R_a+D_a+R_b+D_b) 操作即可非常高效地执行常见水平集 CSG 操作(例如并集、交集和减法)
增强水平集
与许多稀疏结构不同,RLE 稀疏字段与定义值的存储分离。因此,对于用辅助数据增强的水平集,例如 [Houston et al 2003] 中引入的全局遮挡表示形式,单个 RLE 稀疏字段结构可以与多个定义的平面值数组相关联,每个值对应一个所需的辅助字段
这个 Augmented 与其翻译为增强,不如翻译为拓展?
表现动画角色
转换为 RLE 形式

网格面到 RLE 水平集
在 [Houston et al. 2003] 中介绍的,将网格转换为密集水平集的结构化射线投射方法,可以适用于 RLE 稀疏水平集,这样既不需要 O(n^3) 中间存储,也不需要 O(n^3) 操作。这种效率源于射线投射算子能够同时为体积的大型线性部分提供 SDF 的上界。
虽然结构化低密度射线投射本身并不能产生精确的距离场解,但可以使用较慢但精确的方法作为后处理,将已识别窄带的水平集值提高到亚体素精度
自相交
为了处理传统动画角色中经常出现的自相交问题,我们采用以下消歧方案:与网格点相交的每个光线投射都会产生内部或外部投票以及相应的带符号距离值。经过多个通道 pass 后,得票最多的符号对应的距离将被解析为最终的水平集的值
时间抗锯齿
动画角色通常具有子体素特征,例如尖锐的折叠或边缘,当在规则的网格结构上进行动画处理时,可能会导致视觉上令人不快的锯齿伪影。为了消除这些伪影,无需美术师干预或调节,可以将网格转换为所需分辨率两倍的 RLE 稀疏水平集,然后使用低通滤波器下采样至所需分辨率
总结
看上去核心就是那个随机访问的过程文章来源:https://www.toymoban.com/news/detail-834852.html
但是我理解不了他是怎么做到的文章来源地址https://www.toymoban.com/news/detail-834852.html
到了这里,关于RLE 稀疏水平集 RLE sparse level sets 论文阅读笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



![[论文阅读] Explicit Visual Prompting for Low-Level Structure Segmentations](https://imgs.yssmx.com/Uploads/2024/02/608289-1.png)