大家好,我是邵奈一,一个不务正业的程序猿、正儿八经的斜杠青年。
1、世人称我为:被代码耽误的诗人、没天赋的书法家、五音不全的歌手、专业跑龙套演员、不合格的运动员…
2、这几年,我整理了很多IT技术相关的教程给大家,爱生活、爱分享。
3、如果您觉得文章有用,请收藏,转发,评论,并关注我,谢谢!
博客导航跳转(请收藏):邵奈一的技术博客导航
| 公众号 | 微信 | CSDN | 掘金 | 51CTO | 简书 | 微博 |
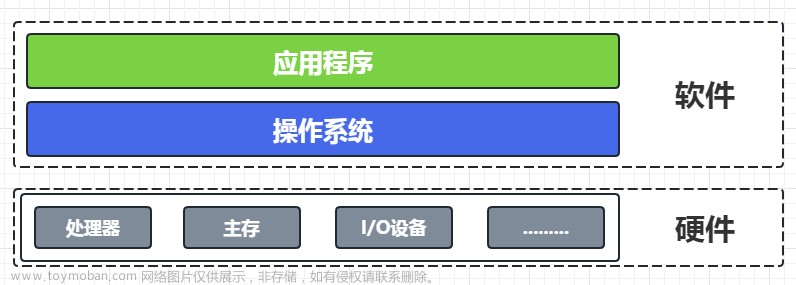
一、关键实操操作
- 打开提供的虚拟机
(遇到问题见: 虚拟机-常见问题总结.doc )
提示:如果没有获得虚拟机与文档,请call me获取。
job虚拟机(IP地址: 192.168.128.250 )
用户名:root
密码:hadoop
- ping通baidu.com(配置网络)
图1:右击job虚拟机,点击“设置”,设置成NAT网络
图2:点击左上角的“编辑”,选择“虚拟网络编辑器”,设置VMnet8的子网地址为128网段
图3:设置Win上VMnet8属性配置,添加DNS服务器地址
ping 百度步骤:登录job虚拟机后,直接输入:
ping baidu.com

- 使用MobaXterm远程连接上job虚拟机
输入ip地址,回车之后输入job虚拟机的密码即可。 - 启动HDFS
start-dfs.sh
PS:停止 stop-dfs.sh
查看进程:jps
查看HDFS的WebUI页面:
192.168.128.250:9870

- 使用Shell命令查看HDFS根路径下的目录列表
hdfs dfs -ls /
- 常用Shell命令实操
操作1:新建一个HDFS目录(目录路径为根路径,目录名称为aaa)
hdfs dfs -mkdir /aaa
操作2:新建一个本地文本文件hello.txt,内容为:
hello,world

vim编辑步骤:输入i进入编辑模式,然后输入hello,world,然后按ESC退出编辑模式,接着按冒号,再按wq(:wq),最后按回车。
PS:如果没有Linux基础,需要学习一下vi/vim编辑器。参考教程:
操作3:上传 hello.txt 文件到HDFS集群的 /aaa 路径
hdfs dfs -put hello.txt /aaa

操作4:查看HDFS集群的hello.txt文件的内容
hdfs dfs -cat /aaa/hello.txt

操作5:下载HDFS集群的/aaa路径的hello.txt文件到job虚拟机本地的/opt路径
hdfs dfs -get /aaa/hello.txt /opt

操作6:删除HDFS集群上的/aaa/hello.txt文件
hdfs dfs -rm /aaa/hello.txt

提示:命令是“hdfs dfs -”开头
二、提供的虚拟机做了哪些操作?
提示:如果没有获得,请call me获取。
- 安装JDK(解压+配置环境变量)
- 配置域名映射(当然,主机名也已经改成了master)
- 配置免密码登录
- 解压Hadoop安装包(包含了HDFS、YARN、MapReduce)
- 配置Hadoop的配置文件(包含了HDFS、YARN、MapReduce的配置文件),并且配置了环境变量
PS:环境变量主要是追加两个路径(bin和sbin)
bin=>hdfs
sbin=>start-dfs.sh、stop-dfs.sh等 - 格式化HDFS
- 安装好了MySQL
用户名:root
密码:123456
8.安装好了Hive
三、虚拟机说明与配置
- job虚拟机设置
如果自己本身电脑的内存就只有4个G,可以尝试调小内存,比如调小到2G:

移除USB、声卡、打印机。
2.集群环境设置文章来源:https://www.toymoban.com/news/detail-834871.html
如果电脑是8G=>1.5G、1G、1G
如果电脑是16G=>3G、2G、2G
平时可以选择用1台或者3台、4台。
装虚拟机尽量不要装 桌面版 。文章来源地址https://www.toymoban.com/news/detail-834871.html
到了这里,关于大数据环境准备与配置说明文档的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!