1.背景介绍
HBase是一个分布式、可扩展、高性能的列式存储系统,基于Google的Bigtable设计。它是Hadoop生态系统的一部分,可以与HDFS、MapReduce、ZooKeeper等组件集成。HBase具有高可用性、高可扩展性和高性能等特点,适用于大规模数据存储和实时数据处理。
在大数据时代,数据的批量操作和事务处理成为了关键技术之一。HBase作为一种高性能的列式存储系统,具有很好的批量操作和事务处理能力。本文将从以下几个方面进行阐述:
- 背景介绍
- 核心概念与联系
- 核心算法原理和具体操作步骤以及数学模型公式详细讲解
- 具体代码实例和详细解释说明
- 未来发展趋势与挑战
- 附录常见问题与解答
1.1 HBase的优势
HBase具有以下优势:
- 分布式和可扩展:HBase可以在多个节点上分布式部署,支持水平扩展。
- 高性能:HBase采用MemStore和HFile结构,提供了高性能的读写操作。
- 强一致性:HBase支持事务处理,可以保证数据的一致性。
- 实时性:HBase支持实时数据访问,可以满足实时应用的需求。
1.2 HBase的应用场景
HBase适用于以下应用场景:
- 日志存储:例如Web访问日志、系统操作日志等。
- 实时数据处理:例如实时数据分析、实时报表、实时监控等。
- 数据挖掘:例如用户行为数据、商品数据、交易数据等。
2. 核心概念与联系
2.1 HBase的数据模型
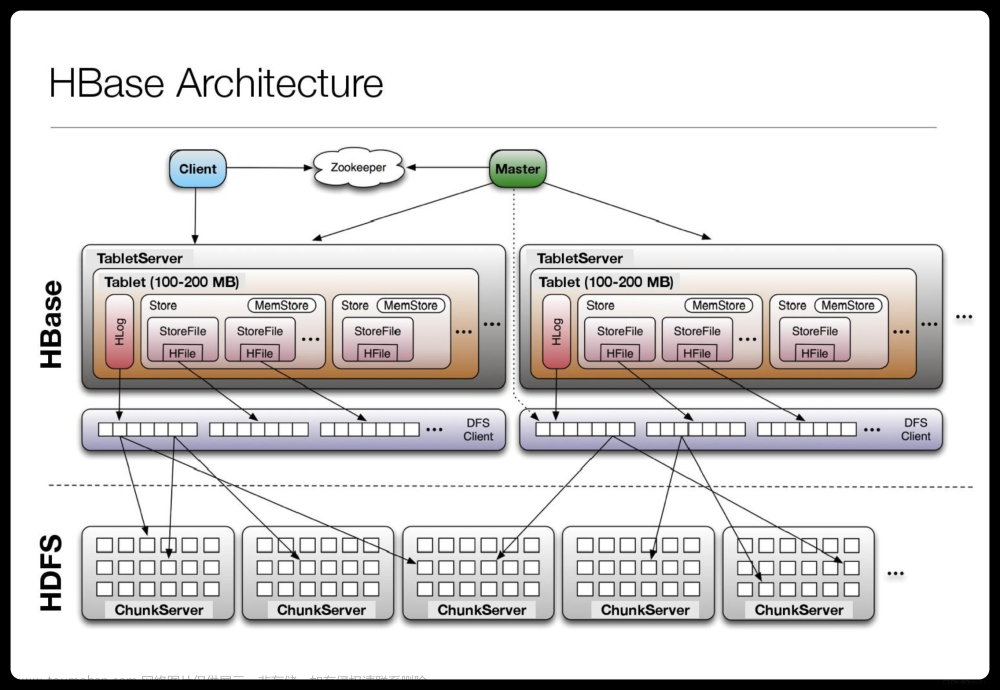
HBase的数据模型包括Region、Row、Column、Cell等。
- Region:Region是HBase中的基本存储单元,可以在多个RegionServer上分布式部署。一个Region包含一定范围的行数据。
- Row:Row是HBase中的一行数据,由一个唯一的行键(RowKey)组成。
- Column:Column是HBase中的一列数据,由一个唯一的列键(ColumnKey)组成。
- Cell:Cell是HBase中的一个数据单元,由Row、Column和值(Value)组成。
2.2 HBase的数据结构
HBase的数据结构包括MemStore、HFile、Store、RegionServer等。
- MemStore:MemStore是HBase中的内存缓存,用于暂存未提交的数据。当MemStore满了或者达到一定大小时,会触发刷新操作,将数据写入磁盘的HFile文件。
- HFile:HFile是HBase中的磁盘文件,用于存储已经刷新的数据。HFile是不可变的,当一个HFile满了或者达到一定大小时,会触发合并操作,将多个HFile合并成一个更大的HFile。
- Store:Store是HBase中的一个存储区域,对应一个Region。Store包含一定范围的Row数据。
- RegionServer:RegionServer是HBase中的一个节点,用于存储Region。RegionServer可以在多个节点上分布式部署。
2.3 HBase的数据操作
HBase支持以下数据操作:
- 读操作:HBase支持顺序读、随机读、扫描读等多种读操作。
- 写操作:HBase支持Put、Delete等写操作。
- 批量操作:HBase支持批量读写操作,可以提高效率。
- 事务处理:HBase支持事务处理,可以保证数据的一致性。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 批量读写操作
HBase支持批量读写操作,可以提高效率。以下是批量读写操作的具体实现:
3.1.1 批量读操作
HBase支持使用Scan器进行批量读操作。Scaner可以设置范围、过滤器等参数,实现高效的批量读操作。
java Scan scan = new Scan(); scan.setStartRow(Bytes.toBytes("001")); scan.setStopRow(Bytes.toBytes("010")); Result result = hbaseTemplate.query(Bytes.toBytes("myTable"), scan);
3.1.2 批量写操作
HBase支持使用Batch进行批量写操作。Batch可以添加多个Put、Delete操作,一次性写入多条数据。
java Batch batch = new Batch(1000); batch.add(new Put(Bytes.toBytes("myTable"), Bytes.toBytes("002"), Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("zhangsan"))); batch.add(new Put(Bytes.toBytes("myTable"), Bytes.toBytes("003"), Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes("20"))); batch.add(new Delete(Bytes.toBytes("myTable"), Bytes.toBytes("001"))); hbaseTemplate.execute(batch);
3.2 事务处理
HBase支持事务处理,可以保证数据的一致性。HBase事务处理使用Lock机制,实现了强一致性。
3.2.1 事务操作
HBase事务操作包括Put、Delete、Commit、Rollback等操作。
java Transaction txn = new Transaction(); txn.add(new Put(Bytes.toBytes("myTable"), Bytes.toBytes("004"), Bytes.toBytes("info"), Bytes.toBytes("gender"), Bytes.toBytes("male"))); txn.add(new Delete(Bytes.toBytes("myTable"), Bytes.toBytes("005"))); txn.add(new Commit()); hbaseTemplate.execute(txn);
3.2.2 事务隔离
HBase事务隔离使用Lock机制,实现了事务之间的隔离。
java Lock lock = new Lock(Bytes.toBytes("myTable"), Bytes.toBytes("006")); lock.lock(); try { // 事务操作 } finally { lock.unlock(); }
4. 具体代码实例和详细解释说明
4.1 批量读写操作
```java import org.apache.hadoop.hbase.client.Batch; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.util.Bytes;
// 批量读操作 Scan scan = new Scan(); scan.setStartRow(Bytes.toBytes("001")); scan.setStopRow(Bytes.toBytes("010")); Result result = hTable.getScanner(scan).next();
// 批量写操作 Batch batch = new Batch(1000); batch.add(new Put(Bytes.toBytes("myTable"), Bytes.toBytes("002"), Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes("zhangsan"))); batch.add(new Put(Bytes.toBytes("myTable"), Bytes.toBytes("003"), Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes("20"))); batch.add(new Delete(Bytes.toBytes("myTable"), Bytes.toBytes("001"))); hTable.execute(batch); ```
4.2 事务处理
```java import org.apache.hadoop.hbase.client.Transaction; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Commit; import org.apache.hadoop.hbase.client.HTable;
// 事务操作 Transaction txn = new Transaction(); txn.add(new Put(Bytes.toBytes("myTable"), Bytes.toBytes("004"), Bytes.toBytes("info"), Bytes.toBytes("gender"), Bytes.toBytes("male"))); txn.add(new Delete(Bytes.toBytes("myTable"), Bytes.toBytes("005"))); txn.add(new Commit()); hTable.execute(txn);
// 事务隔离 Lock lock = new Lock(Bytes.toBytes("myTable"), Bytes.toBytes("006")); lock.lock(); try { // 事务操作 } finally { lock.unlock(); } ```
5. 未来发展趋势与挑战
5.1 未来发展趋势
- 分布式存储:HBase将继续发展为分布式存储系统,支持大规模数据存储和实时数据处理。
- 高性能:HBase将继续优化算法和数据结构,提高读写性能。
- 多语言支持:HBase将支持更多编程语言,提高开发效率。
5.2 挑战
- 数据一致性:HBase需要解决分布式环境下的数据一致性问题,保证数据的准确性和一致性。
- 容错性:HBase需要提高容错性,处理故障和异常情况。
- 扩展性:HBase需要支持水平和垂直扩展,满足不同规模的应用需求。
6. 附录常见问题与解答
6.1 问题1:HBase如何实现数据的一致性?
答案:HBase使用Lock机制实现事务处理,可以保证数据的一致性。
6.2 问题2:HBase如何实现数据的分布式存储?
答案:HBase将数据分布在多个RegionServer上,通过Region和Store结构实现分布式存储。
6.3 问题3:HBase如何实现高性能的读写操作?
答案:HBase采用MemStore和HFile结构,提供了高性能的读写操作。MemStore是内存缓存,用于暂存未提交的数据。当MemStore满了或者达到一定大小时,会触发刷新操作,将数据写入磁盘的HFile文件。HFile是不可变的,当一个HFile满了或者达到一定大小时,会触发合并操作,将多个HFile合并成一个更大的HFile。
6.4 问题4:HBase如何支持批量操作?
答案:HBase支持使用Batch进行批量写操作。Batch可以添加多个Put、Delete操作,一次性写入多条数据。文章来源:https://www.toymoban.com/news/detail-834872.html
6.5 问题5:HBase如何处理故障和异常情况?
答案:HBase需要提高容错性,处理故障和异常情况。可以使用HBase的自动故障检测和恢复功能,以及配置合适的重试策略。文章来源地址https://www.toymoban.com/news/detail-834872.html
到了这里,关于HBase的数据批量操作与事务处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!