1.背景介绍
在大数据处理领域,实时数据处理和搜索功能是非常重要的。Apache Flink 是一个流处理框架,它可以处理大量实时数据,提供高性能和低延迟的数据处理能力。Elasticsearch 是一个分布式搜索引擎,它可以索引和搜索大量文档,提供快速、准确的搜索结果。在实际应用中,Flink 和 Elasticsearch 可以相互整合,实现高效的实时数据处理和搜索功能。
在本文中,我们将从以下几个方面进行讨论:
- 背景介绍
- 核心概念与联系
- 核心算法原理和具体操作步骤以及数学模型公式详细讲解
- 具体最佳实践:代码实例和详细解释说明
- 实际应用场景
- 工具和资源推荐
- 总结:未来发展趋势与挑战
- 附录:常见问题与解答
1. 背景介绍
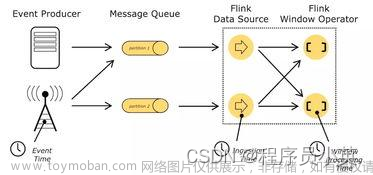
Apache Flink 是一个流处理框架,它可以处理大量实时数据,提供高性能和低延迟的数据处理能力。Flink 支持各种数据源和数据接口,如 Kafka、HDFS、TCP 等。Flink 提供了丰富的数据处理功能,如窗口操作、状态管理、事件时间语义等。
Elasticsearch 是一个分布式搜索引擎,它可以索引和搜索大量文档,提供快速、准确的搜索结果。Elasticsearch 基于 Lucene 库,支持全文搜索、分词、排序等功能。Elasticsearch 支持多种数据源,如 Kafka、Logstash、HTTP 等。
在实际应用中,Flink 和 Elasticsearch 可以相互整合,实现高效的实时数据处理和搜索功能。例如,可以将 Flink 处理的数据直接写入 Elasticsearch,实现实时搜索功能;可以将 Flink 处理的数据存储到 Elasticsearch,实现实时数据分析功能。
2. 核心概念与联系
在 Flink-Elasticsearch 整合中,主要涉及以下几个核心概念:
- Flink 流数据源:Flink 支持多种流数据源,如 Kafka、HDFS、TCP 等。在 Flink-Elasticsearch 整合中,可以将 Flink 流数据源写入 Elasticsearch。
- Flink 流数据接口:Flink 提供了多种流数据接口,如 FlinkKafkaConsumer、FlinkHDFSInputFormat、FlinkSocketSource 等。在 Flink-Elasticsearch 整合中,可以使用 FlinkKafkaConsumer 将 Kafka 中的数据发送到 Flink 流处理任务中。
- Flink 流处理任务:Flink 流处理任务包括数据源、数据接口、数据处理逻辑等。在 Flink-Elasticsearch 整合中,可以将 Flink 流处理任务与 Elasticsearch 整合,实现实时数据处理和搜索功能。
- Elasticsearch 索引:Elasticsearch 中的索引是一种数据结构,用于存储和搜索文档。在 Flink-Elasticsearch 整合中,可以将 Flink 处理的数据写入 Elasticsearch 索引,实现实时搜索功能。
- Elasticsearch 查询:Elasticsearch 提供了多种查询功能,如全文搜索、分词、排序等。在 Flink-Elasticsearch 整合中,可以使用 Elasticsearch 查询功能,实现实时数据分析功能。
在 Flink-Elasticsearch 整合中,Flink 流处理任务与 Elasticsearch 整合,实现高效的实时数据处理和搜索功能。Flink 处理的数据可以直接写入 Elasticsearch,实现实时搜索功能;Flink 处理的数据可以存储到 Elasticsearch,实现实时数据分析功能。
3. 核心算法原理和具体操作步骤以及数学模型公式详细讲解
在 Flink-Elasticsearch 整合中,主要涉及以下几个算法原理和操作步骤:
- Flink 流数据源与 Elasticsearch 整合:
Flink 流数据源可以将数据发送到 Elasticsearch 中,实现实时数据处理和搜索功能。Flink 支持多种流数据源,如 Kafka、HDFS、TCP 等。在 Flink-Elasticsearch 整合中,可以将 Flink 流数据源写入 Elasticsearch。
具体操作步骤如下:
- 创建 Flink 流数据源,如 FlinkKafkaConsumer、FlinkHDFSInputFormat、FlinkSocketSource 等。
- 创建 Flink 流数据接口,如 FlinkKafkaConsumer、FlinkHDFSInputFormat、FlinkSocketSource 等。
- 创建 Flink 流处理任务,包括数据源、数据接口、数据处理逻辑等。
- 将 Flink 流处理任务与 Elasticsearch 整合,实现实时数据处理和搜索功能。
- Flink 流处理任务与 Elasticsearch 整合:
Flink 流处理任务可以与 Elasticsearch 整合,实现高效的实时数据处理和搜索功能。Flink 处理的数据可以直接写入 Elasticsearch,实现实时搜索功能;Flink 处理的数据可以存储到 Elasticsearch,实现实时数据分析功能。
具体操作步骤如下:
- 创建 Flink 流处理任务,包括数据源、数据接口、数据处理逻辑等。
- 使用 Elasticsearch 查询功能,实现实时数据分析功能。
- Flink-Elasticsearch 整合的数学模型公式:
在 Flink-Elasticsearch 整合中,可以使用数学模型公式来描述 Flink 流处理任务与 Elasticsearch 整合的过程。例如,可以使用拓扑图模型来描述 Flink 流处理任务与 Elasticsearch 整合的过程。
具体数学模型公式如下:
- 数据源:$S = {s1, s2, ..., s_n}$
- 数据接口:$I = {i1, i2, ..., i_n}$
- 数据处理逻辑:$P = {p1, p2, ..., p_n}$
- 整合关系:$R = {r1, r2, ..., r_n}$
其中,$S$ 表示数据源,$I$ 表示数据接口,$P$ 表示数据处理逻辑,$R$ 表示整合关系。
4. 具体最佳实践:代码实例和详细解释说明
在 Flink-Elasticsearch 整合中,可以使用以下代码实例来实现实时数据处理和搜索功能:
```python from pyflink.datastream import StreamExecutionEnvironment from pyflink.table import StreamTableEnvironment, DataTypes from pyflink.table.descriptors import Schema, Kafka, Elasticsearch
创建 Flink 流处理环境
env = StreamExecutionEnvironment.getexecutionenvironment() env.set_parallelism(1)
创建 Flink 表处理环境
table_env = StreamTableEnvironment.create(env)
创建 FlinkKafkaConsumer 数据源
kafkasource = tableenv.addsource( Kafka() .version("universal") .topic("mytopic") .startfromlatest() .property("bootstrap.servers", "localhost:9092") .property("group.id", "test") .deserializer(DataTypes.STRING()) )
创建 Elasticsearch 数据接口
elasticsearchsink = tableenv.addsink( Elasticsearch() .version("7.10.1") .connect("localhost:9200") .tableschema(Schema() .field("id", DataTypes.STRING()) .field("value", DataTypes.STRING()) .primary_key("id")) .format(DataTypes.ROW([DataTypes.STRING(), DataTypes.STRING()])) )
创建 Flink 流处理任务
tableenv.executesql(""" CREATE TABLE mytable ( id STRING, value STRING ) WITH ( 'connector' = 'elasticsearch', 'connect.url' = 'localhost:9200', 'table.name' = 'mytable', 'format.type' = 'json' ) """)
将 FlinkKafkaConsumer 数据源写入 Elasticsearch
tableenv.executesql(""" INSERT INTO mytable SELECT id, value FROM mysource """) ```
在上述代码实例中,我们创建了一个 FlinkKafkaConsumer 数据源,将其写入 Elasticsearch。具体实现步骤如下:
- 创建 Flink 流处理环境:使用
StreamExecutionEnvironment.get_execution_environment()创建 Flink 流处理环境。 - 创建 Flink 表处理环境:使用
StreamTableEnvironment.create(env)创建 Flink 表处理环境。 - 创建 FlinkKafkaConsumer 数据源:使用
table_env.add_source()创建 FlinkKafkaConsumer 数据源,指定 Kafka 主题、启动位置、Kafka 服务器地址、分组 ID 等参数。 - 创建 Elasticsearch 数据接口:使用
table_env.add_sink()创建 Elasticsearch 数据接口,指定 Elasticsearch 版本、连接地址、表名、主键等参数。 - 创建 Flink 流处理任务:使用
table_env.execute_sql()创建 Flink 流处理任务,指定 SQL 语句。 - 将 FlinkKafkaConsumer 数据源写入 Elasticsearch:使用
table_env.execute_sql()将 FlinkKafkaConsumer 数据源写入 Elasticsearch。
通过以上代码实例,我们可以实现 Flink-Elasticsearch 整合,实现实时数据处理和搜索功能。
5. 实际应用场景
Flink-Elasticsearch 整合可以应用于以下场景:
- 实时数据分析:可以将 Flink 处理的数据存储到 Elasticsearch,实现实时数据分析功能。例如,可以将实时流数据分析,实现用户行为分析、事件分析等功能。
- 实时搜索:可以将 Flink 处理的数据直接写入 Elasticsearch,实现实时搜索功能。例如,可以将实时流数据索引,实现实时搜索、实时推荐等功能。
- 实时监控:可以将 Flink 处理的数据存储到 Elasticsearch,实现实时监控功能。例如,可以将实时流数据监控,实现系统性能监控、异常监控等功能。
6. 工具和资源推荐
在 Flink-Elasticsearch 整合中,可以使用以下工具和资源:
7. 总结:未来发展趋势与挑战
在 Flink-Elasticsearch 整合中,未来的发展趋势和挑战如下:
- 性能优化:未来,Flink-Elasticsearch 整合需要继续优化性能,提高处理能力和搜索速度。
- 扩展性:未来,Flink-Elasticsearch 整合需要支持更多数据源和数据接口,实现更广泛的应用场景。
- 易用性:未来,Flink-Elasticsearch 整合需要提高易用性,简化开发和部署过程。
- 安全性:未来,Flink-Elasticsearch 整合需要提高安全性,保障数据安全和系统稳定性。
8. 附录:常见问题与解答
在 Flink-Elasticsearch 整合中,可能会遇到以下常见问题:
Q1:Flink 流处理任务如何与 Elasticsearch 整合? A1:Flink 流处理任务可以使用 Elasticsearch 查询功能,实现实时数据分析功能。同时,Flink 流处理任务可以将处理结果直接写入 Elasticsearch,实现实时搜索功能。
Q2:Flink-Elasticsearch 整合如何实现高可用性? A2:Flink-Elasticsearch 整合可以使用分布式数据存储和负载均衡功能,实现高可用性。同时,可以使用 Flink 的容错机制,实现数据一致性和系统稳定性。
Q3:Flink-Elasticsearch 整合如何实现数据安全? A3:Flink-Elasticsearch 整合可以使用数据加密、访问控制、日志记录等功能,实现数据安全。同时,可以使用 Flink 的安全机制,保障数据安全和系统稳定性。
Q4:Flink-Elasticsearch 整合如何实现性能优化? A4:Flink-Elasticsearch 整合可以使用性能调优策略,如数据分区、流控制、缓存等,实现性能优化。同时,可以使用 Flink 的性能监控功能,实时监控系统性能。文章来源:https://www.toymoban.com/news/detail-835092.html
在 Flink-Elasticsearch 整合中,以上是一些常见问题及其解答。希望对您有所帮助。文章来源地址https://www.toymoban.com/news/detail-835092.html
到了这里,关于实时Flink与Elasticsearch的整合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!