索引是啥
可以把Mysql的索引看做是一本书的目录,当你需要快速查找某个章节在哪的时候,就可以利用目录,快速的得到某个章节的具体的页码。Mysql的索引就是为了提高查询的速度,但是降低了增删改的操作效率,也提高了空间的开销。比如一本书很薄的时候,章节不多,对应的目录也就很少 ,可能才一两页,当书的章节很多时,对应的目录也就很多,需要更多的页码来存储目录,当数据库中表的数据很多时,对应的索引也就需要更多的空间来保存,因此说空间的开销会被增加。
-
查看索引
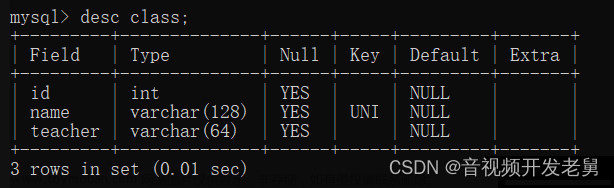
show index from 表名
key_name 是索引名,column_name是根据id这列创建了索引。当表里有primary key、unique和foreign key 时数据库会自动创建索引,每次进行操作表时,数据库会自动判断是否走索引,效率高不高。
- 创建索引
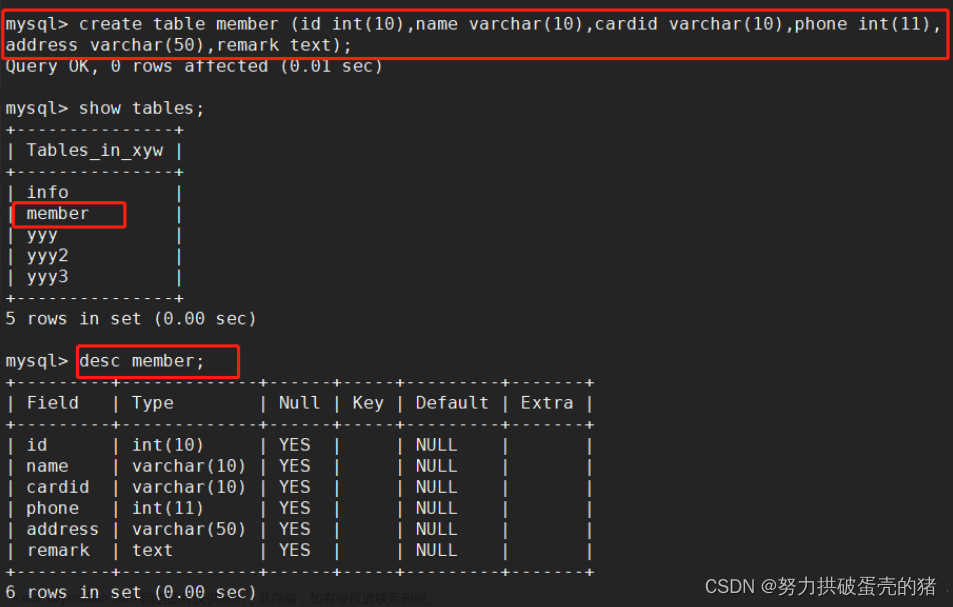
create index 索引名 on 表名(列名)


针对student里的name列创建一个名为inx_name的索引,当再次查看student里的索引时,可以发现多了一个名为inx_name的索引名。
- 删除索引
drop index 索引名 on 表名

索引的数据结构
MySQL创建索引的目的是为了加快查找速度,因此可以考虑查找速度较快的数据结构,比如哈希表,哈希表的查找时间复杂度是O(1),不过不能范围查询,但是MySQL经常查询时带有范围条件,因此哈希表是不适合做索引的数据结构。二叉搜索树适合范围查询,查询的速度也比较快,时间复杂度是O(N),但是二叉搜索树的高度决定了元素的比较次数,当树的高度较高时,比较次数也会增加,而比较操作又需要进行IO操作的,因此当比较次数增加时,IO操作的次数也增加了,IO操作是很费系统资源的,所以二叉搜索树也不适合索引的数据结构。针对二叉搜索树的高度问题,可以引入一个N叉搜索树,把高度降低。N叉搜索树的典型实现是B树,N叉搜索树每个节点有N个key,同时有多个分叉,因此这样就把高度降低了,不过比较次数并没有减少,一个节点上的元素可能涉及到多次比较,但是读写硬盘(IO)的次数减少了,因为每个节点都在硬盘上,读一次硬盘可以读到N个key,之前的二叉搜索树读一次硬盘只能获得一个key。但是B树还是不能做索引的数据结构。现在就针对比较次数进行优化,引入了一个B+树,B+树也是一个N叉搜索树,B+树每个节点上包含N个key,N个key可以划分N个区间,每个区间内的最后一个key是最大值,可以看下图发现叶子没有了80、90这种节点,父元素的key会以最大值的方式在子元素中重复出现,因此叶子节点就包含了整个数据的全集,最后再把叶子每个节点用类似于链表的方式连接起来。


B+树是很适合做MySQL的索引,它具有以下几个特点:
-
由于高度降低了,因此比较次数降低了,IO读写次数也减少了,叶子节点之间连接,更适合做范围查询,比如查询 3<id and id <10的元素,可以直接从叶子节点中取。
-
由于所有数据元素都落在了叶子节点,因此查询哪个元素,比较次数都是差不多的,查询操作相对均衡。而对于B树的查询可能有的快,有的慢,比如查询根节点的元素时就很快,查询叶子节点时就很慢。
-
由于所有的key都会在叶子节点体现,因此非叶子节点可以只存一个索引值,比如id,叶子结点存数据库里真实的数据(数据行),这样就导致非叶子节点占用的空间大大降低,有可能在读取硬盘时可以把非叶子节点的索引值全部读到内存中,更进一步的降低了IO次数。
 文章来源:https://www.toymoban.com/news/detail-835337.html
文章来源:https://www.toymoban.com/news/detail-835337.html
对于带有主键列的索引是按照这种B+树组织的,而对于不带主键列的数据创建了索引,是按另一种B+树实现的。比如非叶子节点存学生姓名name,叶子节点存放主键id,当使用主键列查询数据时,只需要去主键列创建的索引查询一遍即可,当使用非主键列创建的索引,需要去非主键列索引里查询到对应的主键id,再使用这个id去主键列索引里查询对应的数据,需要两次查询,这种操作称为”回表“。文章来源地址https://www.toymoban.com/news/detail-835337.html
到了这里,关于【面试题】谈谈MySQL的索引的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!