1.RabbitMQ集群模式介绍
-
普通集群
- 默认的集群模式,比如有节点node1、node2和node3,三个节点是普通集群,但是他们仅有相同的元数据,即交换机、队列的结构
- 消息只存在其中的一个节点里面,假如消息A存储在node1节点,消费者连接node1节点消费消息时,可以直接取出来;但如果消费者是连接的其他节点,那RabbitMQ会把queue中的消息从存储它的节点中取出,并经过连接节点转发后再发送给消费者
- 假如node1故障,那node2无法获取node1存储未被消费的消息;如果node1持久化后故障,那需要等node1恢复后才可以正常消费;如果node1没做持久化后故障,那消息将会丢失
- 这个情况无法实现高可用性,且节点间会增加通讯获取消息,性能存在瓶颈;该模式更适合于消息无需持久化的场景,如日志传输的队列
- 注意:集群需要保证各个节点有相同的token令牌。erlang.cookie是erlang的分布式token文件,集群内各个节点的erlang.cookie需要相同,才可以互相通信
-
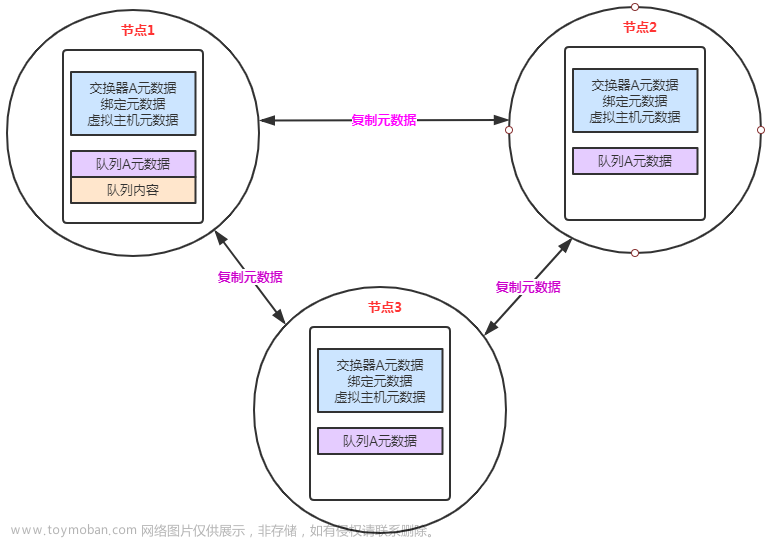
镜像集群(大厂基本使用这个方式)
- 队列做成镜像队列,让各队列存在于多个节点中
- 和普通集群比较大的区别就是【队列queue的消息message】会在集群各节点之间同步,且并不是consumer获取数据时临时拉取,而普通集群则是临时从存储的节点里面拉取对应的数据
- 实现了高可用性,部分节点挂掉后,不影响正常的消费,可以保证100%消息不丢失,推荐奇数个节点,结合LVS+Keepalive进行IP漂移,防止单点故障
- 缺点:由于镜像队列模式下,消息数量过多,大量的消息同步也会加大网络带宽开销,适合高可用要求比较高的项目,过多节点的话,性能则更加受影响
- 注意:集群需要保证各个节点有相同的token令牌。erlang.cookie是erlang的分布式token文件,集群内各个节点的erlang.cookie需要相同,才可以互相通信
-
还有其他通过插件形成的集群,比如Federation集群
2.普通集群docker搭建
-
Linux启动3个rabbitmq节点
# 节点一 docker run -d --hostname rabbit_host1 \ --name gen-rabbitmq1 \ -p 15672:15672 -p 5672:5672 \ -e RABBITMQ_NODENAME=rabbit \ -e RABBITMQ_DEFAULT_USER=admin \ -e RABBITMQ_DEFAULT_PASS=Gen123 \ -e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie' \ --privileged=true \ -v /usr/local/rabbitmq/1/lib:/var/lib/rabbitmq \ -v /usr/local/rabbitmq/1/log:/var/log/rabbitmq \ rabbitmq:management # 节点二 docker run -d --hostname rabbit_host2 \ --name gen-rabbitmq2 \ -p 15673:15672 -p 5673:5672 \ -e RABBITMQ_NODENAME=rabbit \ -e RABBITMQ_DEFAULT_USER=admin \ -e RABBITMQ_DEFAULT_PASS=Gen123 \ -e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie' \ --privileged=true \ -v /usr/local/rabbitmq/2/lib:/var/lib/rabbitmq \ -v /usr/local/rabbitmq/2/log:/var/log/rabbitmq \ --link gen-rabbitmq1:rabbit_host1 \ rabbitmq:management # 节点三 docker run -d --hostname rabbit_host3 \ --name gen-rabbitmq3 \ -p 15674:15672 -p 5674:5672 \ -e RABBITMQ_NODENAME=rabbit \ -e RABBITMQ_DEFAULT_USER=admin \ -e RABBITMQ_DEFAULT_PASS=Gen123 \ -e RABBITMQ_ERLANG_COOKIE='rabbitmq_cookie' \ --privileged=true \ -v /usr/local/rabbitmq/3/lib:/var/lib/rabbitmq \ -v /usr/local/rabbitmq/3/log:/var/log/rabbitmq \ --link gen-rabbitmq1:rabbit_host1 \ --link gen-rabbitmq2:rabbit_host2 \ rabbitmq:management -
参数说明
--hostname:自定义docker容器的主机名 --link:容器之间连接,link不可或缺,使得三个容器能互相通信 --privileged=true:使用该参数,容器内的root拥有真正的root权限,否则容器出现permission denied -v:宿主机和容器路径映射 -e RABBITMQ_NODENAME:缺省Unix*:rabbit@HOSTNAME -e RABBITMQ_DEFAULT_USER=admin:登录用户名 -e RABBITMQ_DEFAULT_PASS=Gen123:登录密码 -e RABBITMQ_ERLANG_COOKIE:值必须相同,也就是一个集群内,相当于不同节点之间通讯的密钥;erlang.cookie是erlang的分布式token文件,集群内各个节点的erlang.cookie需要相同,才可以互相通信 -
配置集群
# 节点一配置集群 docker exec -it gen-rabbitmq1 bash rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl start_app exit # 节点二加入集群,--ram是以内存方式加入,忽略该参数默认为磁盘节点 docker exec -it gen-rabbitmq2 bash rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster --ram rabbit@rabbit_host1 rabbitmqctl start_app exit # 节点三加入集群,--ram是以内存方式加入,忽略该参数默认为磁盘节点 docker exec -it gen-rabbitmq3 bash rabbitmqctl stop_app rabbitmqctl reset rabbitmqctl join_cluster --ram rabbit@rabbit_host1 rabbitmqctl start_app exit # 查看集群节点状态,配置启动了3个节点,1个磁盘节点和2个内存节点 rabbitmqctl cluster_status
-
测试
- node1主节点创建队列,发送消息(可以选择消息是否持久化),node2和node3通过节点自身的web管控台可以看到队列和消息
- 如果把node1节点停止,node2和node3会收不到消息
- 如果是在非主节点(非磁盘节点)创建队列和发送消息,则其他队列可以显示
-
springboot项目配置集群
spring: rabbitmq: virtual-host: / password: Gen123 username: admin addresses: 192.168.101.128:5672,192.168.101.128:5673,192.168.101.128:5674
3.mirror镜像集群配置
-
背景
- 前面搭建了普通集群,如果磁盘节点挂掉后,如果没开启持久化数据就丢失了,其他节点也无法获取消息,所以我们这个集群方案需要进一步改造为镜像模式集群
-
策略policy介绍
-
RabbitMQ的策略policy是用来控制和修改集群的vhost队列和Exchange复制行为,就是要设置哪些Exchange或者Queue的数据需要复制、同步,以及如何复制同步
-
策略会同步同一个VirtualHost中的交换机和队列数据
- Name:自定义策略名称
- Pattern:匹配符,^代表匹配所有
- Definition:ha-mode=all;ha-sync-mode=automatic
ha-mode:指明镜像队列的模式,可选下面的其中一个 all:表示在集群中所有的节点上进行镜像同步(一般使用这个参数) exactly:表示在指定个数的节点上进行镜像同步,节点的个数由ha-params指定 nodes:表示在指定的节点上进行镜像同步,节点名称通过ha-params指定 ha-sync-mode:镜像消息同步方式 manua:手动 automatic:自动 文章来源:https://www.toymoban.com/news/detail-835726.html
文章来源:https://www.toymoban.com/news/detail-835726.html
-
-
集群重启顺序文章来源地址https://www.toymoban.com/news/detail-835726.html
- 启动顺序:磁盘节点–>内存节点
- 关闭顺序:内存节点–>磁盘节点
- 最后关闭必须是磁盘节点,否则容易造成集群启动失败、数据丢失等异常情况
到了这里,关于RabbitMQ集群架构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!