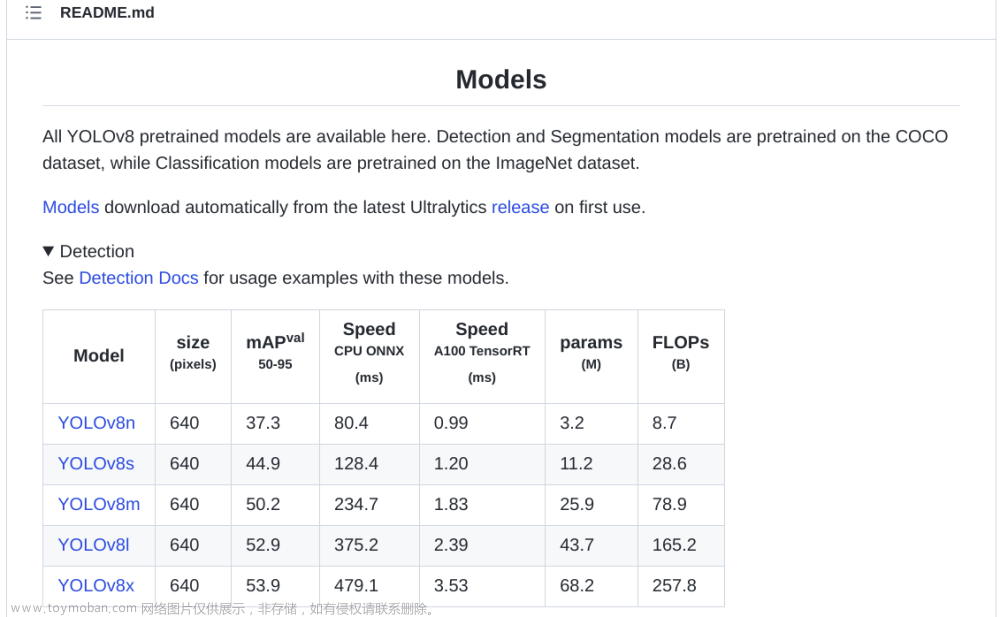
本次开源计划主要针对大学生无人机相关竞赛的视觉算法开发。
开源代码仓库链接:https://github.com/zzhmx/yolov5-tracking-xxxsort.git
先按照之前的博客配置好环境:
yolov5-tracking-xxxsort yolov5融合六种跟踪算法(一)–环境配置GPU版本
yolov5-tracking-xxxsort yolov5融合六种跟踪算法(一)–环境配置CPU版本
1.训练模型
在下载好的代码包中,如果要训练自己的检测模型,需要在程序包中的yolov5文件夹中操作,这个文件夹里面的程序其实就是yolov5的开源代码,想要训练自己模型可以看下面的流程:
这是yolov5文件夹里面的文件。
1)在yolov5-5.0创建一个新的文件夹,比如person_data,在此文件夹下创建
labels (存放labelimg生成的标注文件)
images (存放你采集好的用于标注的图片)
ImageSets (在此文件夹再创建一个Main文件夹)
用手机拍摄两段包含你的识别目标的视频,一段40秒左右,一段10秒左右,40秒的视频用于训练。拍摄完成上传至电脑
2)安装darklabel,https://download.csdn.net/download/weixin_45398265/88860850
3)
标注完所有图像之后就可以查看标记结果了,最终得到txt格式的标注数据
运行下面的代码生成训练集、验证集和测试集:
# coding:utf-8
import os
import random
import argparse
from os import getcwd
parser = argparse.ArgumentParser()
#txt文件的地址,根据自己的数据进行修改
parser.add_argument('--xml_path', default='labels', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.8
train_percent = 0.8
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
sets = ['train', 'val', 'test']
abs_path = os.getcwd()
print(abs_path)
for image_set in sets:
image_ids = open('//home//jcfh//Desktop//yolov5-5.0//map_gongxunsai//ImageSets//Main//%s.txt' % (image_set)).read().strip().split()# 改成你自己的Main路径
list_file = open('//home//jcfh//Desktop//yolov5-5.0//map_gongxunsai//%s.txt' % (image_set), 'w')# 改成你自己的ImageSets路径
for image_id in image_ids:
list_file.write(abs_path + '//images//%s.jpg\n' % (image_id))
list_file.close()
运行代码后,生成三个txt文件
3)在yolov5目录下的data文件夹下新建一个person.yaml文件(可以自定义命名)
按照这种格式,改上你自己的路径,nc为你训练的模型一共有几类,如果只是检测人那就是1,names是你的目标的名字,如person。
4)在yolov5-5.0目录下的model文件夹下是模型的配置文件,这边提供s、m、l、x版本,逐渐增大(随着架构的增大,训练时间也是逐渐增大),假设采用yolov5s.yaml,只用修改一个参数,把nc改成自己的类别数;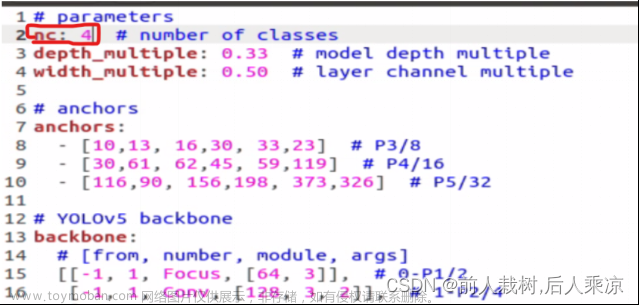
自定义数据集就算是创建完毕了,接下来就是训练模型了。
当然标注视频文件也可以使用基于大模型的自动标注的软件会省力一些,有兴趣的同学自己探索。数据集整理好,yaml配置文件改好,将train.py中的参数改好就可以跑起来进行训练了。
5)在跟踪那一层文件夹里面weights文件夹里面有三个预训练模型:yolov5s.pt、yolov5m.pt、yolov5l.pt,官方还有一个yolov5x.pt是最大的一个,可以自己去官方下载。s是最轻量化的,我们假设使用该模型。我们需要修改train.py程序里面的几个参数: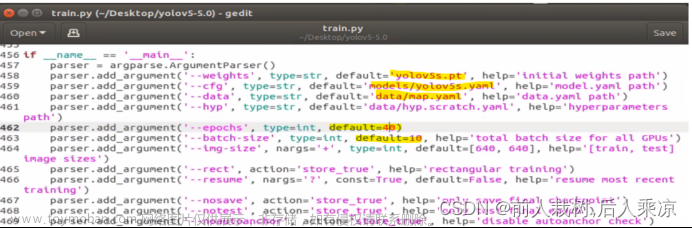
epochs:指的就是训练过程中整个数据集将被迭代多少次,也就是训练轮次。第一次可以先设成100,生成的文件在runs/train文件夹的exp文件下,每运行一次训练代码,exp的序列号就会加一,如exp1,exp2。。。。里面的weights文件夹保存的best.pt就是你训练生成的最优模型。
batch-size:一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点,尽量调到让GPU所有显存都被用满,可以在任务管理器查看gpu使用情况。
cfg:存储模型结构的配置文件
data:存储训练、测试数据的文件
img-size:输入图片宽高,显卡不行你就调小点。
rect:进行矩形训练
resume:恢复最近保存的模型开始训练
nosave:仅保存最终checkpoint
notest:仅测试最后的epoch
evolve:进化超参数
bucket:gsutil bucket
cache-images:缓存图像以加快训练速度
weights:权重文件路径
name: 重命名results.txt to results_name.txt
device:cuda device, i.e. 0 or 0,1,2,3 or cpu
adam:使用adam优化
multi-scale:多尺度训练,img-size +/- 50%
single-cls:单类别的训练集
如果有报错:ImportError: cannot import name ‘COMMON_SAFE_ASCII_CHARACTERS’ from ‘charset_normalizer.constant’
可以在你的虚拟环境中运行:
pip install chardet
6)运行detect.py程序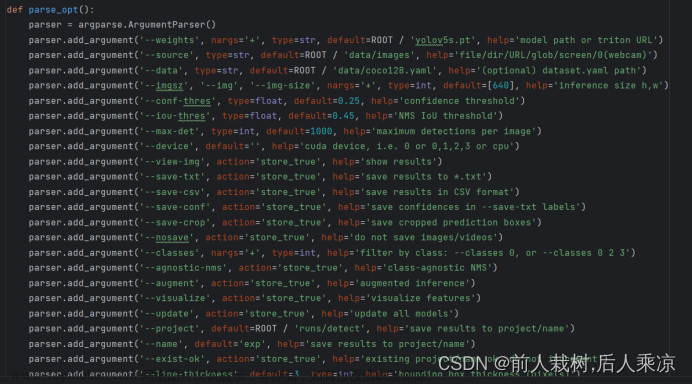 文章来源:https://www.toymoban.com/news/detail-835834.html
文章来源:https://www.toymoban.com/news/detail-835834.html
weights为你要使用的yolov5模型路径
source为你要推理的视频或者图像或者摄像头路径,摄像头的话填0即可。在这里可以放上那段10秒视频的路径。可以选中你的视频文件,右击鼠标,在属性里面看路径,但是别忘了路径要加上你的文件名,例如你的test.mp4文件在属性里看到的路径是F:\yolo_tracking-8.0但是填写的时候要写成:F:\yolo_tracking-8.0\test.mp4
data 改成你之前创建的person.yaml的路径
conf-thres 是检测的阈值,置信度超过这个数才会显示对象
view-img 是设置检测视频的时候是否实时展示结果,在view-img逗号后面可以加一个:文章来源地址https://www.toymoban.com/news/detail-835834.html
default=True,
到了这里,关于yolov5-tracking-xxxsort yolov5融合六种跟踪算法(二)--目标识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!