一、前言
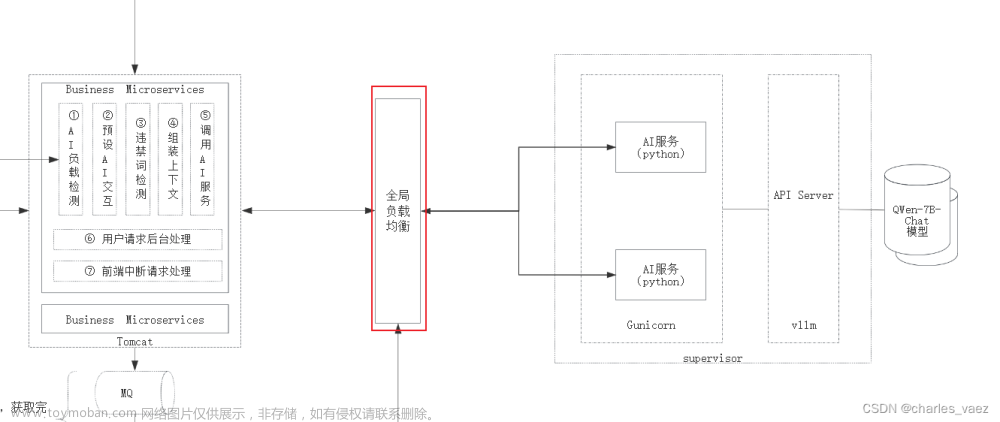
经过线程池优化、请求排队和服务实例水平扩容等措施,整个AI服务链路的性能得到了显著地提升。但是,作为追求卓越的大家,绝不会止步于此。我们的目标是在降低成本和提高效率方面不断努力,追求最佳结果。如果你们在实施AI项目方面有经验,那一定会对GPU服务器的高昂价格感到惋惜。一台基础的v100 24G的GPU云服务器就需要将近3,000元人民币/月。导致很多公司都希望尝试AI,但面对昂贵的服务器成本,只能退缩。接下来,让我们一起努力,对项目进行深度优化,探索更好的解决方案。
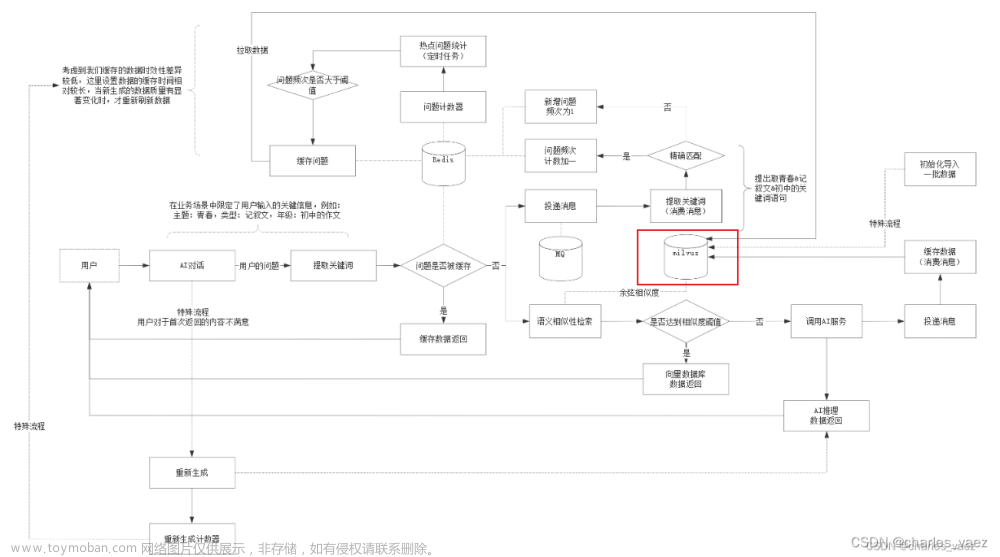
通过“开源模型应用落地-业务优化篇(五)”学习,我们已经搭建了基于Redis的第一级缓存,本篇将尝试使用向量数据库Miluvs作为AI服务的第二级缓存。
二、术语
2.1、向量数据库
向量数据库是一种专门用于存储和处理高维向量数据的数据库系统。与传统的关系型数据库或文档数据库不同,向量数据库的设计目标是高效地支持向量数据的索引和相似性搜索。
在传统数据库中,数据通常是以结构化的表格形式存储,每个记录都有预定义的字段。但是,对于包含大量高维向量的数据,如图像、音频、文本等,传统的数据库模型往往无法有效地处理。向量数据库通过引入特定的数据结构和索引算法,允许高效地存储和查询向量数据。文章来源:https://www.toymoban.com/news/detail-835878.html
向量数据库的核心概念是向量索引。它使用一种称为向量空间模型的方法,文章来源地址https://www.toymoban.com/news/detail-835878.html
到了这里,关于开源模型应用落地-业务优化篇(六)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!