1. 简单文本:
使用google加的tesseract,效果不错。
首先安装tesseract,在mac直接brew install即可。
python调用代码:
import pytesseract
from PIL import Image
img = Image.open('1.png')
pytesseract.image_to_string(img, lang='chi_sim+eng')
2. 结构化文本
使用百度家的paddleocr可以达成如下效果: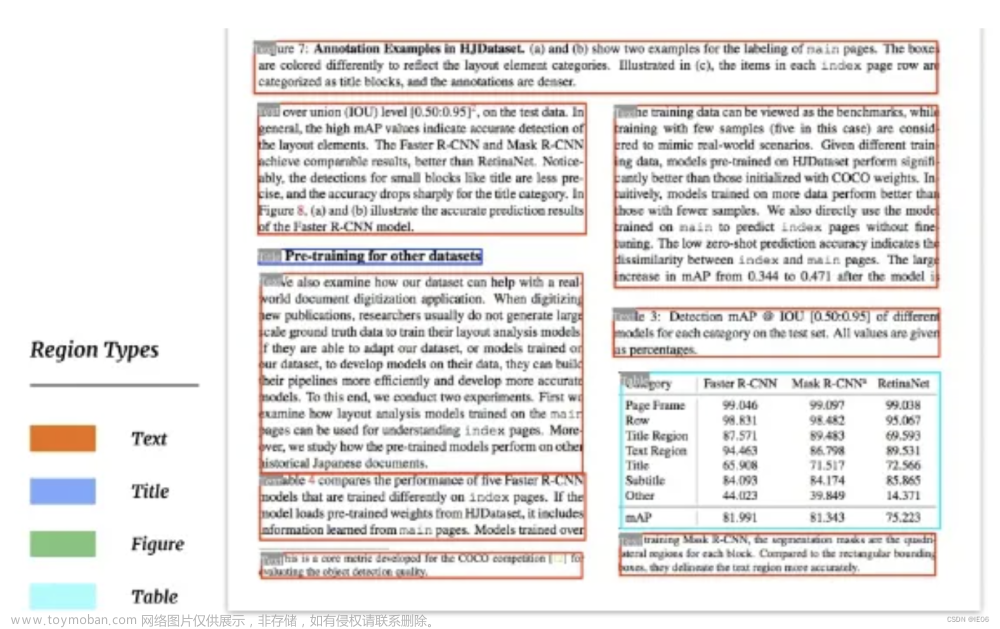 文章来源:https://www.toymoban.com/news/detail-836091.html
文章来源:https://www.toymoban.com/news/detail-836091.html
安装方法:pip install “paddleocr>=2.2”,调用代码。
其中画图的部分如果要用的话,需要下载字体库:!git clone https://gh.api.99988866.xyz/https://github.com/PaddlePaddle/PaddleOCR;不需要画图的话,注释掉即可。文章来源地址https://www.toymoban.com/news/detail-836091.html
import os
import cv2
from paddleocr import PPStructure, draw_structure_result, save_structure_res
from PIL import Image
def Structure_analysis(img_path):
table_engine = PPStructure(show_log=True)
save_folder = './output/table'
img = cv2.imread(img_path)
result = table_engine(img)1
save_structure_res(result, save_folder,os.path.basename(img_path).split('.')[0])
for line in result:
line.pop('img')
print(line)
font_path = '../PaddleOCR/doc/fonts/simfang.ttf' # PaddleOCR下提供字体包
image = Image.open(img_path).convert('RGB')
im_show = draw_structure_result(image, result, font_path=font_path)
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
pass
Structure_analysis('1.png')
到了这里,关于深度学习系列59:文字识别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!