目录
前言
Redis支持哪些数据类型
五种核心类型
Zset为什么用跳表不用红黑树 ?
Redis常见的应用场景?
如何检测Redis的连通性?
如何设置key的过期时间?
Redis为什么是单线程模型?
Redis里的IO多路复用是什么?
RDB的持久化机制有哪些?
AOF的重写机制是怎么样的?
Redis的过期删除策略是怎么样的?
Redis处理缓存雪崩的问题:
Redis的主从复制是怎么回事?
介绍一下Redis哨兵
Redis集群是干什么用的?
Redis的哈希槽是怎么回事?
Redis集群会有操作丢失吗?
如何理解Redis的事务?和MySQL的事务有什么区别?
什么是缓存穿透、缓存雪崩、缓存击穿
缓存穿透
缓存雪崩
缓存击穿
Redis和MySQL如何保证双写一致性?
Redis的“bigkey”问题
前言
Redis是一个高性能的key-value的内存数据库 ,在内存上的数据会随着掉电而通通消失,所以就有了不同的持久化的方式(搞到硬盘上)。Redis没有关系型数据库那种复杂查询的功能,而换来的是简单易用和高性能~~
Redis支持哪些数据类型
五种核心类型
- String
- Hashmap
- List
- Set
- Zset
后续新增了一些数据类型~
- Bitmap:通过二进制位表示某个数是否存在
- Bitfield:把字符串当作位图,进行位操作
- Hyperloglog:基于位图实现计数效果
- Geospatial:地理信息,存储经纬度,并可以进行一些空间计算
- Stream:消息队列
Zset为什么用跳表不用红黑树 ?
跳表的插入、删除、查询的时间复杂度一样是O(logN),与红黑树一样。但是跳表更简单,不需要重新平衡这种操作
Redis常见的应用场景?
- 缓存:用来保存常见的热点数据,减少数据库的压力
- 计数器:统计点击次数、收藏、点赞次数等
- 排行榜:可以基于Zset简单实现
- 分布式会话:使用Redis存储会话信息,可以让用户访问到系统的不同模块的时候都使用同一个公共会话
- 分布式锁:对于分布式的一种并发控制手段,可以基于Redis来实现,上篇文章有详细展开
- 消息队列:Redis自身支持Stream数据类型,可以作为简单的消息队列使用
如何检测Redis的连通性?
给服务端发送一个 "ping" ,通顺的话就会收到 "pong"
如何设置key的过期时间?
可以在set key的时候通过EX选项指定过期时间,也可以再使用expire对已存在的key设置过期时间
Redis为什么是单线程模型?
Redis内部逻辑较为简单,大部分的性能瓶颈都是出现在IO或内存上,很少是CPU。因此使用多线程还没多大收益,还容易引入线程安全问题
从Redis6.0开始,Redis引入多线程,此时它也只是使用多线程去处理网络请求+协议解析,真正执行Redis命令的仍然是单线程完成,这样可以提高IO处理效率
Redis里的IO多路复用是什么?
Redis主要是基于Linux提供的epoll机制来完成IO多路复用(之前文章详细讲述过)
所谓IO多路复用,其实就是一个线程来管理多个 socket ,并按需激活线程
| 假如在同一个单位时间内,有多个Redis客户端的请求到来了.....
| 使用传统的方式是给每一个客户端连接开一个线程,但是大部分的客户端不会频繁的给你 传输,即多数是空闲线程(不活跃) , 所以搞一堆线程不如就用一个线程来处理,反正并 发量不会太高而且处理速度又飞快
上述的操作被Linux封装好了,就是IO多路复用
在Linux中有三种实现方式:
- select
- poll
- epoll
epoll是最新,也是最高效的版本(之前文章有详细讲述)这里浅浅谈一下
epoll在内核维护了一个红黑树,来管理这些socket,并且每一个节点都关联了一个事件回调,当系统内核感知到网卡收到数据,进一步判定这个数据是给哪一个socket的,随之调用对应的回调函数,进一步唤醒用户线程,来处理这个数据
RDB的持久化机制有哪些?
RDB和AOF两种
RDB:
- RDB是一个紧凑的二进制文件,代表Redis某个时间的数据快照。适合备份,全量复制的场景。
- Redis加载RDB文件来恢复数据远快于AOF
- 但是RDB也没办法做到实时持久化。因为每次的bgsave都需要fork,全量复制对于cpu和硬盘的负荷大
- 此外,RDB文件使用特定的二进制格式保存,Redis版本演进过程中有多个RDB版本,兼容性可能有冲突
AOF:
- AOF记录所有写入Redis的命令(文本方式),因此AOF的实时性高,适合在Redis宕机的时候恢复
- AOF提供了重写功能,可以定期对AOF文件进行重写,取出冗余命令,减小AOF大小
- 由于每次的命令都要同步到AOF文件中,所以会有一定的写入延迟
- AOF文件是文本类型的数据比较大
- 如果AOF的文件过大就会导致恢复速度比较慢了
AOF的重写机制是怎么样的?
- Redis在后台启动一个AOF重写进程
- 在AOF重写过程中,Redis继续处理客户端请求,并将这份数据同时保存到旧AOF文件以及一个缓冲区
- 新的AOF文件会遍历内存中的数据状态,只保留数据的最后状态。并与缓冲区共同生成一份完整的AOF文件
- 用新的AOF文件来代替旧的AOF文件

Redis的过期删除策略是怎么样的?
惰性过期
只有当访问一个key的时候才能判断他是否过期,过期就清除。
这种策略方式可以节省CPU资源,但是会有可能出现大量过期的key未被再次访问,导致占用大量内存
定期过期
每个一段时间,会扫描一定数量的数据库expires字典中一定数量的key,并清除已过期的key。
expire字典中会保存所有设置了过期时间的key的过期时间数据,其中key是指向某个键的指针,value是该键的毫秒精度的UNIX时间戳表示过期时间
Redis中则是同时使用了这两种策略:
- 每隔100ms就随机抽取一定数量的key来检查和删除
- 在获取key的时候检查一下是否过期,过期就删除
Redis处理缓存雪崩的问题:
首先对于定期删除来说,Redis会注册一个定时器,每个一定时间就触发一次
在删除的时候会根据事先统计好的过期key的个数来决定后续策略
如果过期key的个数超过总key的25%,就会让Redis持续删除过期key直到最大删除时间(默认25ms),但即使如此,有些对性能要求高的常见仍然会因为阻塞25ms导致性能下降
解决方案:可以在过期时间上加上随机值,使过期时间分散一点,降低触发这个25%阈值
Redis的主从复制是怎么回事?
其实就是为了保证咱redis的高可用,减少单个节点的负载(具体流程之前文章讲述过)
Redis主从复制https://blog.csdn.net/Obto_/article/details/135946296
介绍一下Redis哨兵
之前文章有详细讲述,感兴趣的可以看看这篇文章
Redis哨兵https://blog.csdn.net/Obto_/article/details/135964383
Redis Sentinel是Redis的高可用的实现方案,在实际的生产环境中,对整个系统的高可用提升是非常有帮助的,当主从复制结构中某个节点宕机之后,哨兵能够自动发现故障并完成故障转移
如果是主节点故障,哨兵之中会互相协商(哨兵不只一个),当大多数哨兵节点达成主节点宕机的结果后,就会在哨兵之中推举出一个领导节点来自动完成故障转转移的工作,同时将这个变化通知给Redis客户端,这个过程是全自动的不需要人工介入
Redis集群是干什么用的?
之前的文章有详细讲述,感兴趣的可以看看这篇文章
Redis集群https://blog.csdn.net/Obto_/article/details/136176895
Redis集群引入多组Master/Slave,每一组Master/Slave存储数据全集的一部分,从而构成更大的整体,解决单个Master/Slave能够达到的性能上限,能够存储更多的数据
好比一个30T的资源放在一个硬盘放不下,就可以放在3个10T的硬盘上
Redis的哈希槽是怎么回事?
在Redis集群中要合理的分配各个主节点的资源,所以就有了不同的hash方式将数据映射到对应的分片中
第一种就是直接hash 一个 N ,N为分片的总数,这样能够保证数据随机分配,但是一旦出现数据扩容的情况,N发生了变化,此时之前的映射关系全部作废,扩容的代价很大
第二种就是一致性hash,统一hash一个数,这样能解决上述因扩容而导致的映射关系被破坏,但是会导致数据的不均匀
因此哈希槽分区算法就出来了
哈希槽分区算法:
将所有的key都映射到16284(2^14) 个槽位上,再把这些槽均匀的分配给每个分片,每个分片只需要记录自己拥有哪些槽位即可 (详细的连接在上面Redis集群链接中)
Redis集群会有操作丢失吗?
Redis并不能保证数据的强一致性,实际中集群在特定的条件下可能会丢失写操作
比如在成功写入一个key之后,正好主节点宕机,那么此时由于这个数据还未来得及同步到从节点,也没来得及写入AOF日志,就会丢失
如何理解Redis的事务?和MySQL的事务有什么区别?
区别:
- 弱原子性
- 不保证一致性
- 不需要隔离性
- 不需要持久化
Redis事务的本质就是在服务器搞了一个“事务队列”,每次客户端进行操作的时候,就先把命令保存在事务队列中,收到EXEC命令后才会一起执行
Redis事务和MySQL事务的概念上是一样的,都是把一系列的操作捆绑成一组,让一组批量执行
什么是缓存穿透、缓存雪崩、缓存击穿
缓存穿透
访问的key不存在客户端也不存在服务端,此时这样的key就不被缓存起来,而高频的访问这个不存在的key就会导致Redis失去他“保护盾”的作用
解决办法:
1.布隆过滤器
2.将不存在的key也存在redis并随便设置value为'.'
3.对需要查询的key进行严格的合法性校验,不合规的不让查
缓存雪崩
短时间内大量的key 在缓存上失效,导致数据库压力暴增
解决方法:
1.部署高可用的Redis集群
2.不给key设置时间,或设置时间的时候添加随机时间因子
缓存击穿
相当于缓存血崩的特殊情况,就是针对热点key过期了,导致大量的请求访问到了MySQL上
解决方法:
1.基于统计的方式发现热点key,并设置永不过期
2.进行必要的服务降级,访问数据的时候使用分布式锁,限制并发数
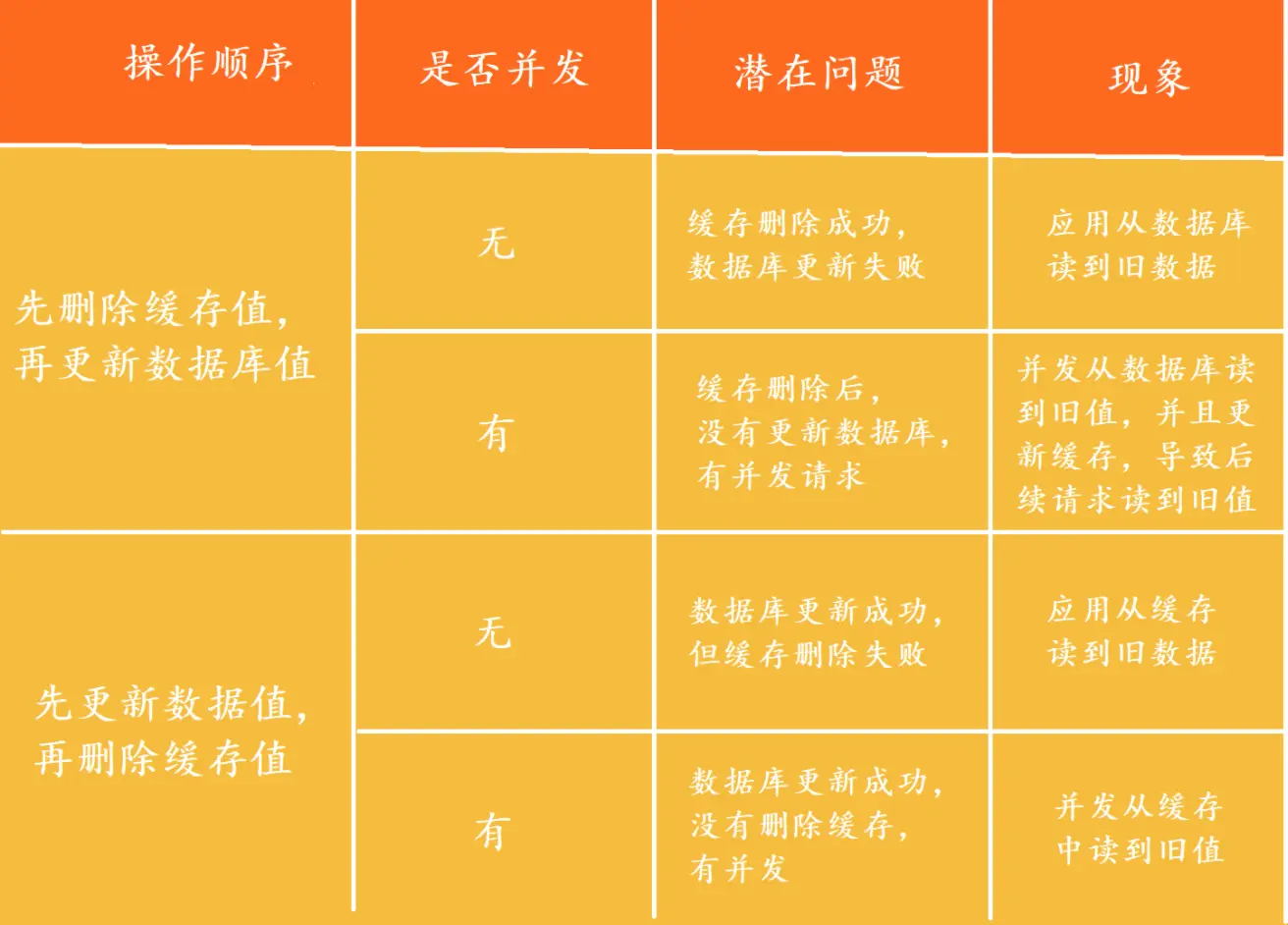
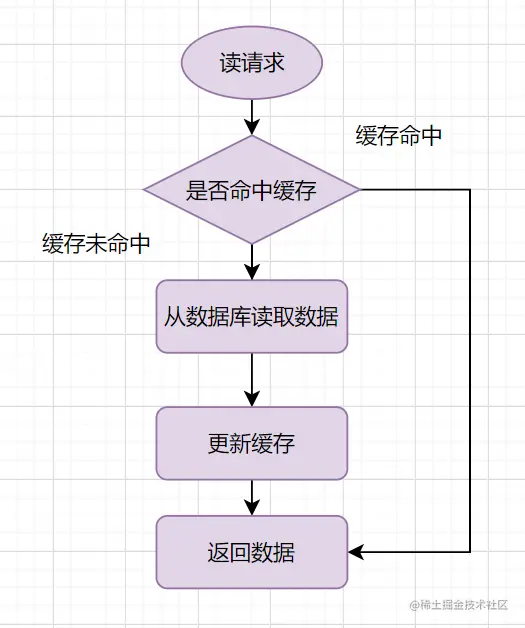
Redis和MySQL如何保证双写一致性?
什么是“双写一致性” ??
当用户修改数据的时候,需要修改数据库,同时也要更新缓存中的数据
如果直接写数据库并写Redis,此时万一有一方写入失败,就容易出现数据不一致情况
解决方法:
方案一:延迟双删
1.删除缓存数据
2.更新数据库
3.再删除缓存数据
方案二:删除缓存重试
1.先删除缓存数据,如果失败,就把失败的key放到一个mq中,稍后进行重试
Redis的“bigkey”问题
指的就是key对应的value很大占据较大的存储空间
可以使用redis-cli --bigkey查找bigkey,删除bigkey尽量不要用del,用unlink在后台删
这样的big可以会导致读写的时候性能下降,如果是集群分配部署,也会引起不同分片的数据倾斜
解决方案:文章来源:https://www.toymoban.com/news/detail-836130.html
核心思路就是拆分,将大key拆成多个小key,每个key对应value的一部分数据 文章来源地址https://www.toymoban.com/news/detail-836130.html
到了这里,关于Redis的常见面试题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!