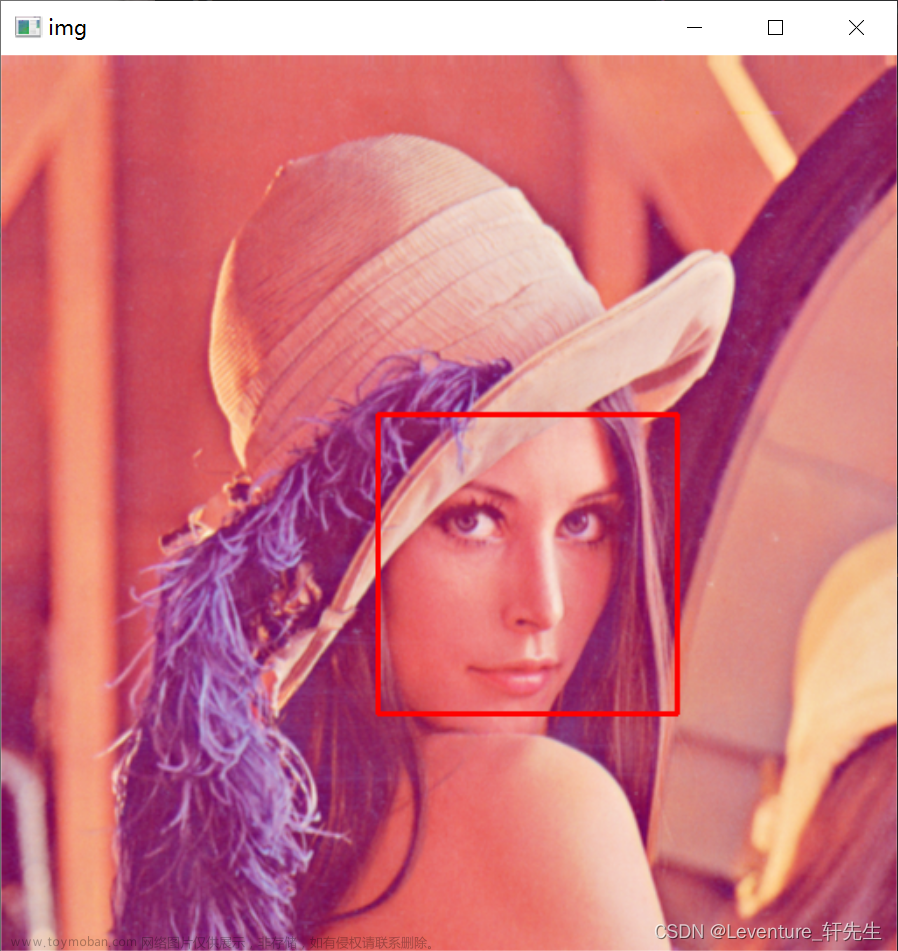
要划分训练集和测试集。
训练集也要分为训练集和验证集。
延伸学习:文章来源:https://www.toymoban.com/news/detail-836137.html
1. 数据集的划分比例
- 训练集:通常占据整个数据集的60%-80%,用于训练模型。
- 验证集:约占10%-20%,用于在训练过程中调整模型参数和超参数,以及进行早期停止训练等操作,防止过拟合。
- 测试集:约占10%-20%,用于评估模型的最终性能。测试集在整个训练过程中应保持未知状态,直到模型训练完成。
2. 随机划分与分层划分
- 随机划分:如果数据集中的类别分布相对均匀,可以使用随机划分来确保每个子集中的数据分布与原始数据集相似。
- 分层划分:如果数据集存在类别不平衡问题,应采用分层划分,确保每个子集中的类别比例与原始数据集一致。
3. 数据集的代表性
- 确保每个子集中的数据都具有代表性,能够反映整体数据的分布特点。
- 如果数据存在时序性或其他依赖关系,应确保划分后的子集保持这种关系。
4. 避免数据泄露
- 在划分数据集之前,不应进行任何可能影响数据分布的预处理操作。
- 确保测试集在模型训练和验证过程中始终保持未知状态,以避免信息泄露和过拟合。
5. 多次划分与交叉验证
- 为了获得更可靠的模型性能评估,可以多次划分数据集并训练模型,然后取平均性能作为最终结果。
- 交叉验证(如k-折交叉验证)是一种有效的方法,它通过将数据集划分为k个子集并轮流用作测试集来评估模型性能。
6. 考虑数据的动态变化
- 如果数据是随时间变化的(如时间序列数据),应确保训练集包含较早时期的数据,而测试集包含较晚时期的数据,以评估模型对未知数据的泛化能力。
7. 数据集的均衡性
- 对于类别不平衡的数据集,可以采用过采样少数类别或欠采样多数类别的方法来平衡数据集。但在划分训练集、验证集和测试集时,仍应保持相同的类别比例。
遵循这些规则和最佳实践可以确保机器学习模型在训练、验证和测试过程中获得可靠且有意义的结果。作为人工智能专家,理解并能够根据具体任务和数据特性灵活应用这些规则是至关重要的。文章来源地址https://www.toymoban.com/news/detail-836137.html
到了这里,关于【大厂AI课学习笔记】【2.2机器学习开发任务实例】(4)制作数据集的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!