系统的关键性能指标:吞吐量,延迟和TP。
吞吐量:反应单位时间内处理请求的能力。
延迟:从客户端发送请求到接收响应的时间。
延迟和吞吐量的曲线如下图所示: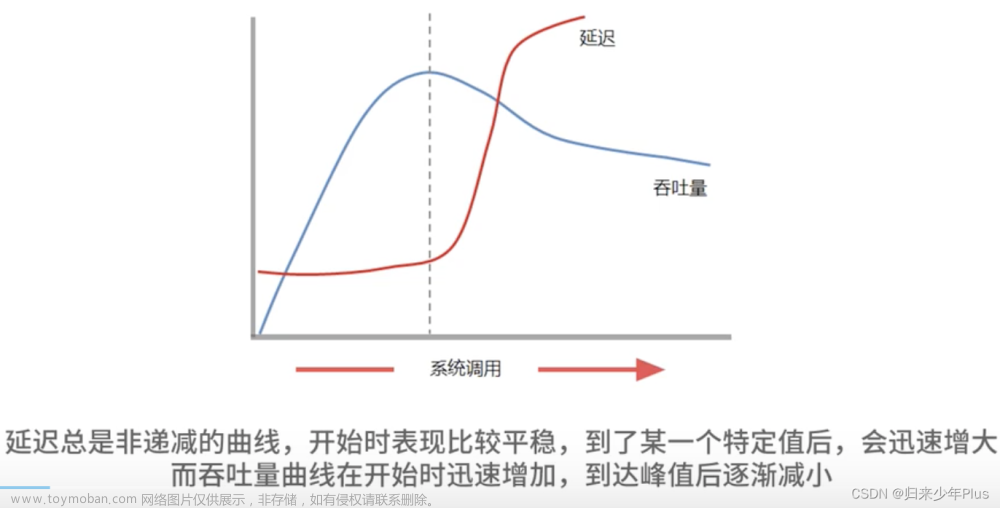
总体来看,随着压力增大,系统单位时间内被访问的次数增加。结合延迟和吞吐量观察的话,系统优化性能指标是找到延迟趋向最低和吞吐量趋向最高的点。
TP:99%的请求达到的一个时间值。
全链路视角分析系统性能指标:
- DNS解析
DNS缓存和DNS预解析提高DNS解析时间。 文章来源:https://www.toymoban.com/news/detail-836234.html
文章来源:https://www.toymoban.com/news/detail-836234.html
- 建立TCP链接

- 服务器响应

- 白屏时间

通过gzip压缩资源文件,调整用户的界面浏览行为。 - 首屏时间

三、如何分析系统的性能瓶颈
- 定位延迟问题

- 吞吐量问题的定位

 文章来源地址https://www.toymoban.com/news/detail-836234.html
文章来源地址https://www.toymoban.com/news/detail-836234.html
到了这里,关于如何评估和优化系统的高性能的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!