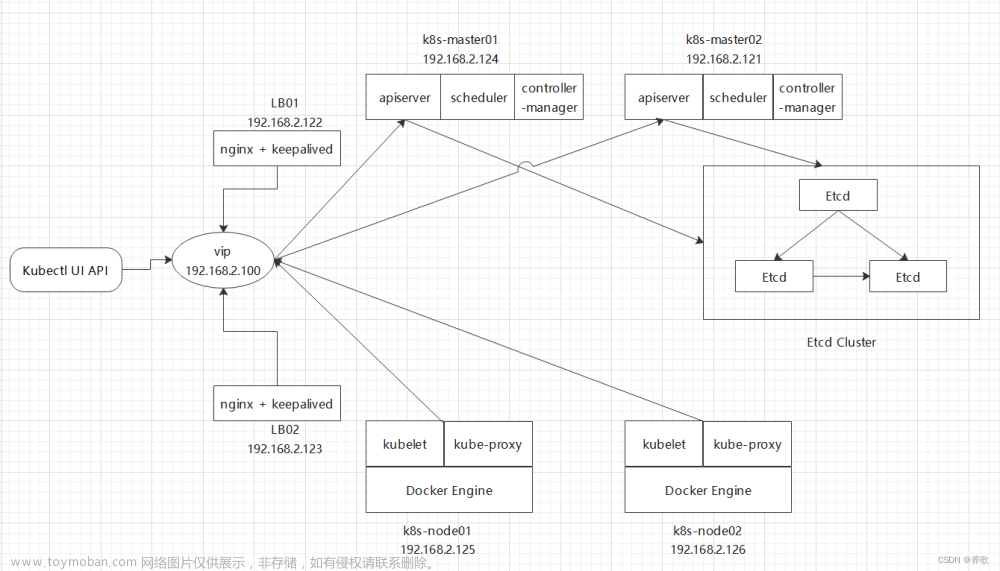
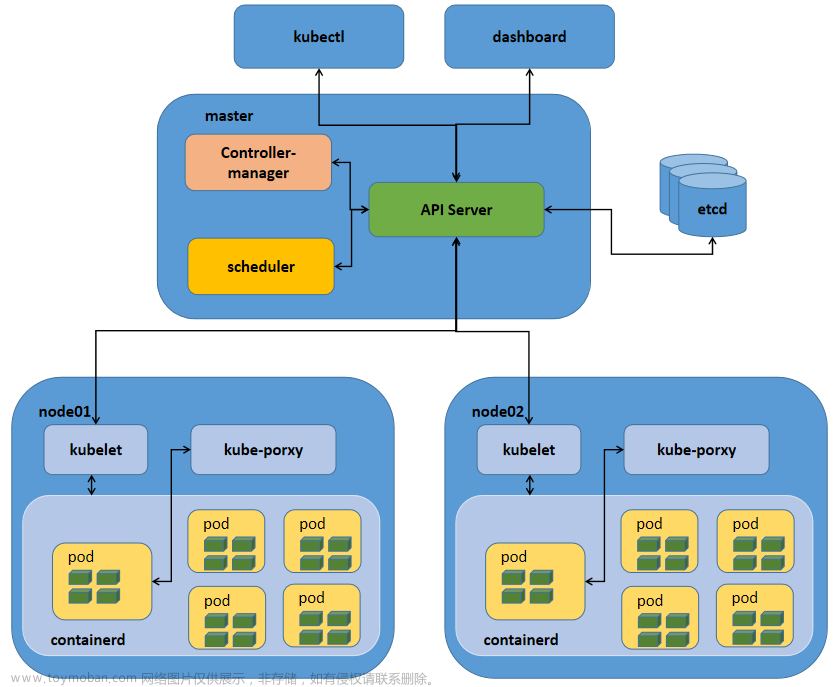
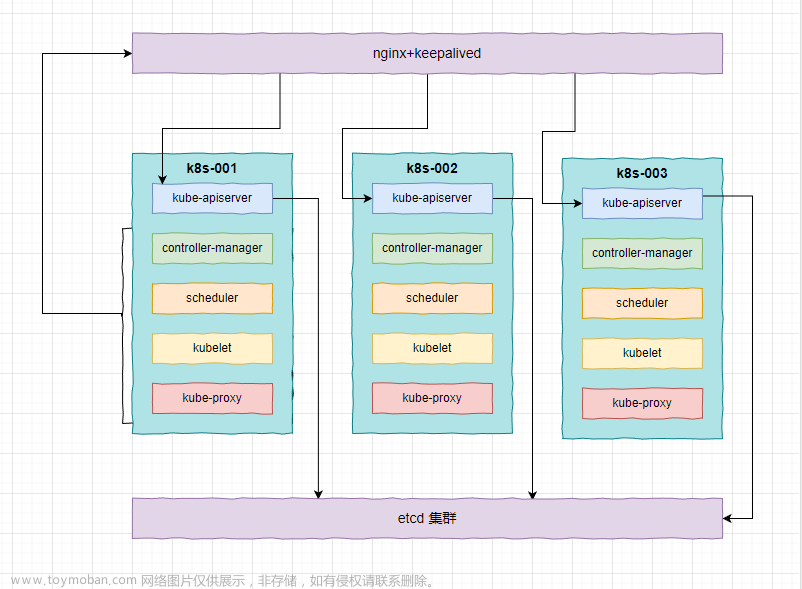
K8S、keepalived、haproxy 高可用集群实战
环境:Centos7.6、2个CPU、8G内存以上配置
Master1:172.20.26.24
Master2:172.20.26.86
Master3:172.20.26.89
Node1: 172.20.26.104
VIP :172.20.26.201
在master1、2、3、Node1上:关闭selinux、firewalld、安装net-tools、lrzsz、vim、epel-release、yum update
一、K8S所有节点(master1、2、3、Node1)Hosts及防火墙设置
Master1、Master2、Master3、node1节点进行如下配置:
#添加hosts解析;
cat >/etc/hosts<<EOF
127.0.0.1 localhost localhost.localdomain
172.20.26.34 master1
172.20.26.36 master2
172.20.26.38 master3
172.20.26.37 node1
EOF
#临时关闭selinux和防火墙;
vim /etc/selinux/config #将状态改为disabled
setenforce 0
systemctl stop firewalld.service
systemctl disable firewalld.service
#同步节点时间;
yum install ntpdate -y
ntpdate pool.ntp.org
#修改对应节点主机名;
hostname `cat /etc/hosts|grep $(ifconfig|grep broadcast|awk '{print $2}')|awk '{print $2}'`;su
#关闭swapoff(因交换分区读写速度无法与内存比,关闭交换分区,确保k8s性能);
swapoff -a # 临时关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab #永久关闭
二、Linux内核参数设置&优化(master1、2、3、Node1)
让k8s支持IP负载均衡技术:
cat > /etc/modules-load.d/ipvs.conf <<EOF
# Load IPVS at boot
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack_ipv4
EOF
systemctl enable --now systemd-modules-load.service #加载模块
#确认内核模块加载成功
lsmod | grep -e ip_vs -e nf_conntrack_ipv4
如果没有看到信息,可以把机器重启一下就可以了
#安装ipset、ipvsadm
yum install -y ipset ipvsadm
#配置内核参数;(加入桥接转发,让容器能够使用二层网络)
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
三、配置节点免秘钥登录:
Master1节点作为Master控制节点,执行如下指令创建公钥和私钥,然后将公钥拷贝至其余节点即可
ssh-keygen -t rsa -N '' -f /root/.ssh/id_rsa -q
ssh-copy-id -i /root/.ssh/id_rsa.pub root@master1
ssh-copy-id -i /root/.ssh/id_rsa.pub root@master2
ssh-copy-id -i /root/.ssh/id_rsa.pub root@master3
ssh-copy-id -i /root/.ssh/id_rsa.pub root@node1
四、所有节点安装Docker、kubeadm、kubelet、kubectl (master1、2、3、Node1)
1、安装Docker
# 安装依赖软件包
yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加Docker repository,这里使用国内阿里云yum源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 安装docker-ce,这里直接安装最新版本
yum install -y docker-ce
#修改docker配置文件
mkdir /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
],
"registry-mirrors": ["https://uyah70su.mirror.aliyuncs.com"]
}
EOF
# 注意,由于国内拉取镜像较慢,配置文件最后增加了registry-mirrors
mkdir -p /etc/systemd/system/docker.service.d
# 重启docker服务
systemctl daemon-reload
systemctl enable docker.service
systemctl start docker.service
ps -ef|grep -aiE docker
2、Kubernetes添加部署源
添加kubernetes源指令如下:
cat>>/etc/yum.repos.d/kubernetes.repo<<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
EOF
3、K8S Kubeadm
安装Kubeadm工具;
#安装Kubeadm;
yum install -y kubeadm-1.20.4 kubelet-1.20.4 kubectl-1.20.4
#启动kubelet服务(此时启动kubelet 会无法正常启动,可以忽略启动失败)
systemctl enable kubelet.service;systemctl start kubelet.service;systemctl status kubelet.service
Node1节点安装到这即可。
五、Haproxy安装配置(Master1、2、3)
Haproxy安装配置步骤相对比较简单,跟其他源码软件安装方法大致相同,如下为Haproxy配置方法及步骤:
(1)Haproxy编译及安装
#yum安装:
yum install haproxy* -y
#源码编译安装:
yum install wget gcc -y
cd /usr/src
wget -c https://www.haproxy.org/download/2.1/src/haproxy-2.1.12.tar.gz
tar xzf haproxy-2.1.12.tar.gz
cd haproxy-2.1.12
make TARGET=linux310 PREFIX=/usr/local/haproxy/
make install PREFIX=/usr/local/haproxy
(2)配置Haproxy服务
#yum 安装的配置:
cd /usr/local/haproxy
vim haproxy.cfg
#源码编译安装配置:
useradd -s /sbin/nologin haproxy -M
cd /usr/local/haproxy ;mkdir -p etc/
touch /usr/local/haproxy/etc/haproxy.cfg
cd /usr/local/haproxy/etc/
vim /usr/local/haproxy/etc/haproxy.cfg
(3)Haproxy.cfg配置文件内容如下:
global
log /dev/log local0
log /dev/log local1 notice
chroot /usr/local/haproxy
stats socket /usr/local/haproxy/haproxy-admin.sock mode 660 level admin
stats timeout 30s
user haproxy
group haproxy
daemon
nbproc 1
defaults
log global
timeout connect 5000
timeout client 10m
timeout server 10m
listen admin_stats
bind 0.0.0.0:10080
mode http
log 127.0.0.1 local0 err
stats refresh 30s
stats uri /status
stats realm welcome login\ Haproxy
stats auth admin:123456
stats hide-version
stats admin if TRUE
listen kube-master
bind 0.0.0.0:8443
mode tcp
option tcplog
balance source
server master1 172.20.26.24:6443 check inter 2000 fall 2 rise 2 weight 1
server master2 172.20.26.86:6443 check inter 2000 fall 2 rise 2 weight 1
server master3 172.20.26.89:6443 check inter 2000 fall 2 rise 2 weight 1
(4)启动Haproxy服务
/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/etc/haproxy.cfg #(源码编译安装)
/usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.cfg #(yum安装方式启动)
ps -ef | grep haproxy #查看haproxy服务状态
将haproxy.cfg 文件拷贝到master2、3,并启动haproxy服务
scp /usr/local/haproxy/etc/haproxy.cfg root@master2:/usr/local/haproxy/etc/
scp /usr/local/haproxy/etc/haproxy.cfg root@master3:/usr/local/haproxy/etc/
查看服务状态:
ps -ef |grep haproxy
systemctl daemon-reload
systemctl enable haproxy
systemctl start haproxy
六、配置Keepalived服务 (Master1、2、3)
yum install openssl-devel popt* -y
yum install keepalived* -y
1、配置Haproxy+keepalived
Haproxy+keealived Master1端keepalived.conf配置文件如下:
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
lqcbj@163.com
}
notification_email_from lqcbj@163.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MASTER1
}
vrrp_script chk_haproxy {
script "/data/sh/check_haproxy.sh"
interval 2
weight 2
}
# VIP1
vrrp_instance VI_1 {
state MASTER
interface ens192
virtual_router_id 133
priority 100
advert_int 5
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
172.20.26.201
}
track_script {
chk_haproxy
}
}
2、创建haproxy检查脚本
mkdir -p /data/sh
vim /data/sh/check_haproxy.sh
#check_haproxy.sh脚本内容如下:
#!/bin/bash
#auto check haprox process
#2021-6-24 lqc
NUM=$(ps -ef|grep haproxy|grep -aivcE "grep|check")
if
[[ $NUM -eq 0 ]];then
systemctl stop keepalived.service
fi
#设置可执行权限
chmod +x /data/sh/check_haproxy.sh
#在Master2、Master3上创建sh目录:
mkdir -p /data/sh
#在Master1上将check_haproxy.sh文件从拷贝到Master2、3上:
scp /data/sh/check_haproxy.sh root@master2:/data/sh/
scp /data/sh/check_haproxy.sh root@master3:/data/sh/
#在Master2、Master3上设置可执行权限:
chmod +x /data/sh/check_haproxy.sh
#将keepalived.conf 拷贝到Master2、3上,进行修改router_id、 priority:
scp /etc/keepalived/keepalived.conf root@master2:/etc/keepalived/
scp /etc/keepalived/keepalived.conf root@master3:/etc/keepalived/
#Haproxy+keealived Master2端keepalived.conf配置文件如下:
! Configuration File for keepalived
global_defs {
notification_email {
lqcbj@163.com
}
notification_email_from lqcbj@163.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MASTER2
}
vrrp_script chk_haproxy {
script "/data/sh/check_haproxy.sh"
interval 2
weight 2
}
# VIP1
vrrp_instance VI_1 {
state BACKUP
interface ens192
virtual_router_id 133
priority 90
advert_int 5
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
172.20.26.201
}
track_script {
chk_haproxy
}
}
Haproxy+keealived Master3端keepalived.conf配置文件如下:
! Configuration File for keepalived
global_defs {
notification_email {
lqcbj@163.com
}
notification_email_from lqcbj@163.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MASTER3
}
vrrp_script chk_haproxy {
script "/data/sh/check_haproxy.sh"
interval 2
weight 2
}
# VIP1
vrrp_instance VI_1 {
state BACKUP
interface ens192
virtual_router_id 133
priority 80
advert_int 5
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
172.20.26.201
}
track_script {
chk_haproxy
}
}
启动keepalived 服务
systemctl enable keepalived.service && systemctl start keepalived.service && systemctl status keepalived.service
ps -ef | grep keepalived 查看keepalived服务状态
haproxy先启动,keepalived 后启动
如有问题问题,进行排查:
journalctl -xeu kubelet | less 查看kubelet日志
systemctl restart kubelet.service;systemctl status kubelet.service
问题:Keepalived 的状态出现Netlink: filter function error
解决:重启网络服务、keepalived服务,重新查看keepalived状态,正常
systemctl restart keepalived.service
可以安装nginx ,进行验证
关闭所有交换分区,重启docker、kubelet、docker容器:
swapoff -a;service docker restart;service kubelet restart;docker ps -aq|xargs docker restart
七、 初始化Master集群
1、K8S集群引入Haproxy高可用集群,此时整个集群需要重新初始化,创建初始化kubeadmin-init.yaml配置文件。
#打印默认初始化配置信息至yaml文件中;
kubeadm config print init-defaults >kubeadmin-init.yaml
#将如下代码覆盖kubeadm-init.yaml文件,注意advertiseAddress、controlPlaneEndpoint的信息:
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 172.20.26.34
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "172.20.26.201:8443"
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.20.4
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16
serviceSubnet: 10.10.0.0/16
scheduler: {}
再次检查关闭防火墙、交换分区
systemctl stop firewalld
systemctl disable firewalld
swapoff -a
#然后执行如下命令初始化集群即可,在172.20.26.34master1上,操作指令如下:
kubeadm init --control-plane-endpoint=172.20.26.201:8443 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.20.4 --service-cidr=10.10.0.0/16 --pod-network-cidr=10.244.0.0/16 --upload-certs
#显示以下类似信息,表示成功:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 172.20.26.201:8443 --token 46prfc.ze6u2rqm3jazm955 \
--discovery-token-ca-cert-hash sha256:e59d020c3b99e8917c73d3291acc940562c163470f4884d61603b1371b48f131 \
--control-plane --certificate-key 5c40e73e6b3d2e0a62a9a8dd820b04f6e5bc5682c5b0ecbd50d2395ded4acb8a
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.20.26.201:8443 --token 46prfc.ze6u2rqm3jazm955 \
--discovery-token-ca-cert-hash sha256:e59d020c3b99e8917c73d3291acc940562c163470f4884d61603b1371b48f131
#如果执行初始化时出现这个报错:[ERROR FileContent--proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1
解决:sysctl -w net.ipv4.ip_forward=1
#删除旧数据,重新初始化;
kubeadm reset
rm -rf .kube/
#k8s集群默认不让在master节点创建pod,也就是说Master Node不参与工作负载,去除Master节点污点,使其可以分配Pod资源;
kubectl taint nodes --all node-role.kubernetes.io/master-
#如果想让 Pod 也能调度到在 Master(本样例即 localhost.localdomain)上,可以执行如下命令使其作为一个工作节点:
kubectl taint node localhost.localdomain node-role.kubernetes.io/master-
#将 Master 恢复成 Master Only 状态:
如果想禁止 Master 部署 pod,则可执行如下命令:(报错可忽略)
kubectl taint node --all node-role.kubernetes.io/master="":NoSchedule
2、 增加Master新节点(control-plane node)
1)如果是在需要添加为新master的服务器上执行如下指令,例如在172.20.26.36、172.20.26.38上执行;
kubeadm join 172.20.26.201:8443 --token 46prfc.ze6u2rqm3jazm955 \
--discovery-token-ca-cert-hash sha256:e59d020c3b99e8917c73d3291acc940562c163470f4884d61603b1371b48f131 \
--control-plane --certificate-key 5c40e73e6b3d2e0a62a9a8dd820b04f6e5bc5682c5b0ecbd50d2395ded4acb8a
2)根据提示,在172.20.26.36、172.20.26.38上执行如下指令即可;
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
3)自此K8S Master高可用集群构建成功,查看节点,可以看到两个master节点,同时通过VIP 172.20.26.201可以访问UI界面即可。
4)如果后期再增加master的话,需要在master1上生成新的token,打印加入K8S集群指令,操作命令如下:
kubeadm token create --print-join-command
根据生成的token信息,替换即可:
kubeadm join 172.20.26.201:8443 --token 0a3y38.qn1bvrehmkf9v4xd --discovery-token-ca-cert-hash sha256:e59d020c3b99e8917c73d3291acc940562c163470f4884d61603b1371b48f131
5)在master上生成用于新master2加入的证书,操作命令如下:
kubeadm init phase upload-certs --upload-certs
显示:
Using certificate key:
1d8ba4d09d93ee2760df4458e7d340679150d2feef6331c1eb3009f05cdf485d
6)如果是添加新的工作Node节点(worker nodes),需要执行如下指令;
kubeadm join 172.20.26.201:8443 --token 46prfc.ze6u2rqm3jazm955 \
--discovery-token-ca-cert-hash sha256:e59d020c3b99e8917c73d3291acc940562c163470f4884d61603b1371b48f131
#错误提示:
error execution phase preflight: couldn't validate the identity of the API Server: could not find a JWS signature in the cluster-info ConfigMap for token ID "0a3y38"
token 过期, 在master1上重新生成token:
kubeadm token generate
新token:vkkkxh.j9n3iyamoq9qvm1q
在node1上重新执行
kubeadm join 172.20.26.201:8443 --token vkkkxh.j9n3iyamoq9qvm1q \ --discovery-token-ca-cert-hash sha256:e59d020c3b99e8917c73d3291acc940562c163470f4884d61603b1371b48f131
#假设我们需要删除已加入集群的node1 这个节点,首先在 master 节点上依次执行以下两个命令:
kubectl drain node1 --delete-local-data --force --ignore-daemonsets
kubectl delete node node1
文章来源地址https://www.toymoban.com/news/detail-836444.html
八、 K8S节点网络配置
Kubernetes整个集群所有服务器(Master、Minions)配置Flanneld,操作方法和指令如下:
参考:https://github.com/containernetworking/cni
必须安装pod网络插件,以便pod之间可以相互通信,必须在任何应用程序之前部署网络,CoreDNS不会在安装网络插件之前启动。
1)安装Flanneld网络插件;
Fanneld定义POD的网段为: 10.244.0.0/16,POD容器的IP地址会自动分配10.244开头的网段IP。安装Flanneld网络插件指令如下:
#下载Fanneld插件YML文件;(也可以提前下载好上传kube-flannel.yml)
yum install wget -y
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
#提前下载Flanneld组建所需镜像;
for i in $(cat kube-flannel.yml |grep image|awk -F: '{print $2":"$3}'|uniq );do docker pull $i ;done
错误提示:
Error response from daemon: Get https://quay.io/v2/: read tcp 172.20.26.86:51430->50.16.140.223:443: read: connection reset by peer
#应用YML文件;
kubectl apply -f kube-flannel.yml
#查看Flanneld网络组建是否部署成功;
kubectl -n kube-system get pods|grep -aiE flannel
Kube-flannel.yaml配置文件代码如:(如果无法下载,可以直接vim Kube-flannel.yaml创建一个文件,将下面内容粘贴保存即可)
---
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: psp.flannel.unprivileged
annotations:
seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default
seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default
apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default
apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default
spec:
privileged: false
volumes:
- configMap
- secret
- emptyDir
- hostPath
allowedHostPaths:
- pathPrefix: "/etc/cni/net.d"
- pathPrefix: "/etc/kube-flannel"
- pathPrefix: "/run/flannel"
readOnlyRootFilesystem: false
# Users and groups
runAsUser:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
fsGroup:
rule: RunAsAny
# Privilege Escalation
allowPrivilegeEscalation: false
defaultAllowPrivilegeEscalation: false
# Capabilities
allowedCapabilities: ['NET_ADMIN', 'NET_RAW']
defaultAddCapabilities: []
requiredDropCapabilities: []
# Host namespaces
hostPID: false
hostIPC: false
hostNetwork: true
hostPorts:
- min: 0
max: 65535
# SELinux
seLinux:
# SELinux is unused in CaaSP
rule: 'RunAsAny'
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
rules:
- apiGroups: ['extensions']
resources: ['podsecuritypolicies']
verbs: ['use']
resourceNames: ['psp.flannel.unprivileged']
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-system
---
kind: ConfigMap
apiVersion: v1
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-flannel-ds
namespace: kube-system
labels:
tier: node
app: flannel
spec:
selector:
matchLabels:
app: flannel
template:
metadata:
labels:
tier: node
app: flannel
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/os
operator: In
values:
- linux
hostNetwork: true
priorityClassName: system-node-critical
tolerations:
- operator: Exists
effect: NoSchedule
serviceAccountName: flannel
initContainers:
- name: install-cni
image: quay.io/coreos/flannel:v0.13.1-rc2
command:
- cp
args:
- -f
- /etc/kube-flannel/cni-conf.json
- /etc/cni/net.d/10-flannel.conflist
volumeMounts:
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.13.1-rc2
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
securityContext:
privileged: false
capabilities:
add: ["NET_ADMIN", "NET_RAW"]
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: run
mountPath: /run/flannel
- name: flannel-cfg
mountPath: /etc/kube-flannel/
volumes:
- name: run
hostPath:
path: /run/flannel
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
如果安装flannel网络插件,必须通过kubeadm init配置–pod-network-cidr=10.10.0.0/16参数。
验证网络插件
安装了pod网络后,确认coredns以及其他pod全部运行正常,查看master节点状态为Ready
kubectl get nodes
kubectl -n kube-system get pods
#如果提示以下信息:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
需要添加环境变量:
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
source /etc/profile
至此,Kubernetes 的 Master 节点就部署完成了。如果只需要一个单节点的 Kubernetes,现在你就可以使用了。
九、 K8S开启IPVS模块(Master1、2、3上执行)
修改kube-proxy的configmap,在config.conf中找到mode参数,改为mode: "ipvs"然后保存:
kubectl -n kube-system get cm kube-proxy -o yaml | sed 's/mode: ""/mode: "ipvs"/g' | kubectl replace -f -
#或者手动修改
kubectl -n kube-system edit cm kube-proxy
kubectl -n kube-system get cm kube-proxy -o yaml | grep mode
mode: "ipvs"
#重启kube-proxy pod
kubectl -n kube-system delete pods -l k8s-app=kube-proxy
#确认ipvs模式开启成功
kubectl -n kube-system logs -f -l k8s-app=kube-proxy | grep ipvs
日志中打印出Using ipvs Proxier,说明ipvs模式已经开启。
十、 K8s Dashboard UI实战
Kubernetes实现的最重要的工作是对Docker容器集群统一的管理和调度,通常使用命令行来操作Kubernetes集群及各个节点,命令行操作非常不方便,如果使用UI界面来可视化操作,会更加方便的管理和维护。如下为配置kubernetes dashboard完整过程:
1、下载Dashboard配置文件;(也可以上传k8s_dashboard.yaml文件)
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc5/aio/deploy/recommended.yaml
\cp recommended.yaml recommended.yaml.bak
将recommended.yaml改名为 k8s_dashboard.yaml
2、修改文件k8s_dashboard.yaml的39行内容,#因为默认情况下,service的类型是cluster IP,需更改为NodePort的方式,便于访问,也可映射到指定的端口。
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
nodePort: 31001
selector:
k8s-app: kubernetes-dashboard
3、修改文件k8s_dashboard.yaml的195行内容,#因为默认情况下Dashboard为英文显示,可以设置为中文。
env:
- name: ACCEPT_LANGUAGE
value: zh
4、创建Dashboard服务,指令操作如下:
kubectl apply -f k8s_dashboard.yaml
5、查看Dashboard运行状态;
kubectl get pod -n kubernetes-dashboard
kubectl get svc -n kubernetes-dashboard
6、将Master节点也设置Node节点,可以运行Pod容器任务,命令如下;
kubectl taint nodes --all node-role.kubernetes.io/master-
7、基于Token的方式访问,设置和绑定Dashboard权限,命令如下;
#创建Dashboard的管理用户;
kubectl create serviceaccount dashboard-admin -n kube-system
#将创建的dashboard用户绑定为管理用户;
kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
#获取刚刚创建的用户对应的Token名称;
kubectl get secrets -n kube-system | grep dashboard
#查看Token的详细信息;
kubectl describe secrets -n kube-system $(kubectl get secrets -n kube-system | grep dashboard |awk '{print $1}')
8、通过浏览器访问Dashboard WEB,https://172.20.26.201:31001/,如图所示,输入Token登录即可。
#kubernetes-dashboard修改默认token认证过期时间
modify token-ttl#
默认900s/15分钟后认证token回话失效,需要重新登录认证,修改12h,方便使用
在线修改:
在命名空间里选择kubernetes-dashboard ,点击deployment中kubernetes-dashboard 后面的三个点,选择编辑,大概在YAML 下187行左右添加token-ttl=43200(43200为12小时)
- '--token-ttl=43200'
例如:
containers:
- name: kubernetes-dashboard
image: 'kubernetesui/dashboard:v2.0.0-rc5'
args:
- '--auto-generate-certificates'
- '--namespace=kubernetes-dashboard'
- '--token-ttl=43200'
命令行修改:
kubectl edit deployment kubernetes-dashboard -n kubernetes-dashboard
containers:
- args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
修改新增 --token-ttl=43200
containers:
- args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
- --token-ttl=43200文章来源:https://www.toymoban.com/news/detail-836444.html
到了这里,关于K8S、keepalived、haproxy 高可用集群实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!