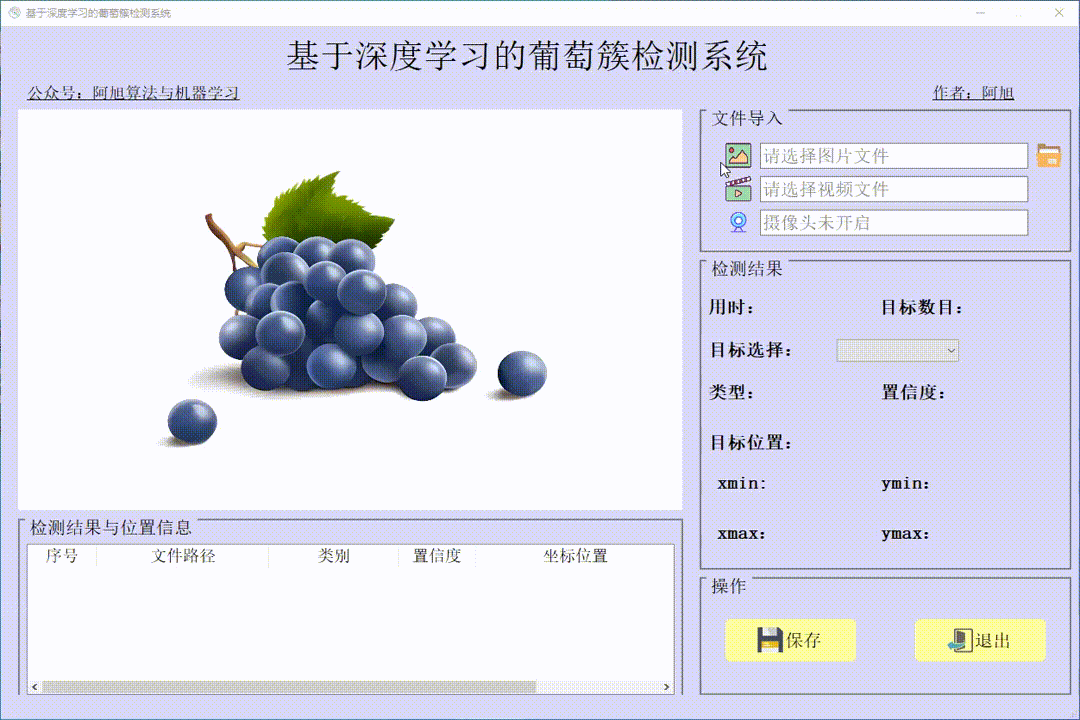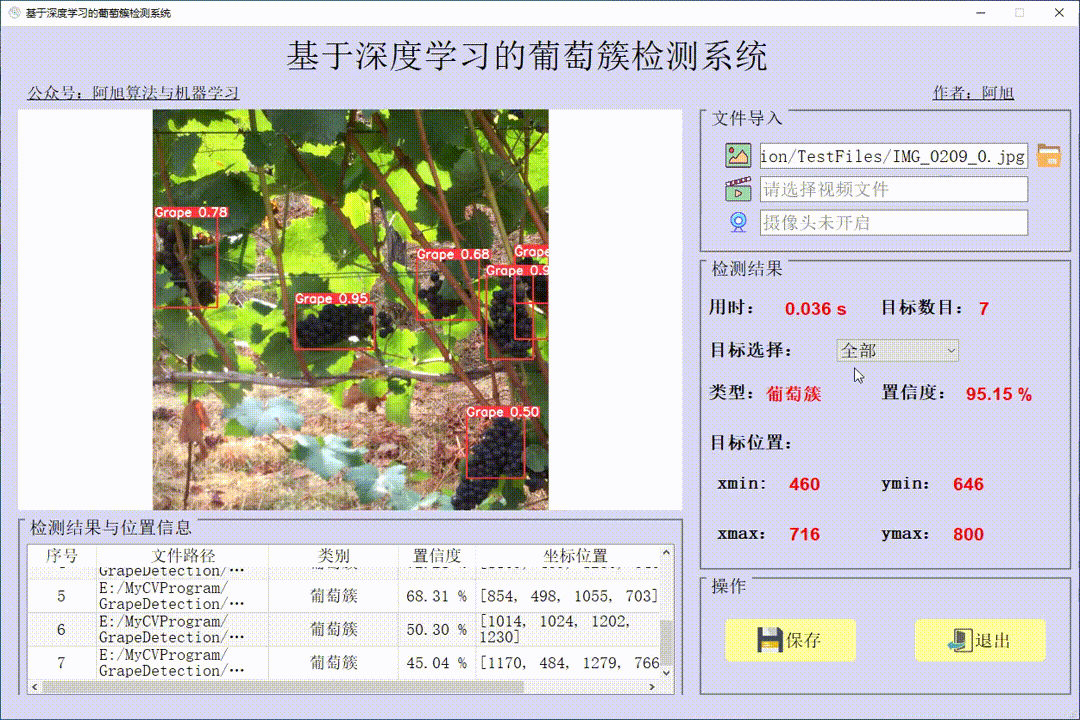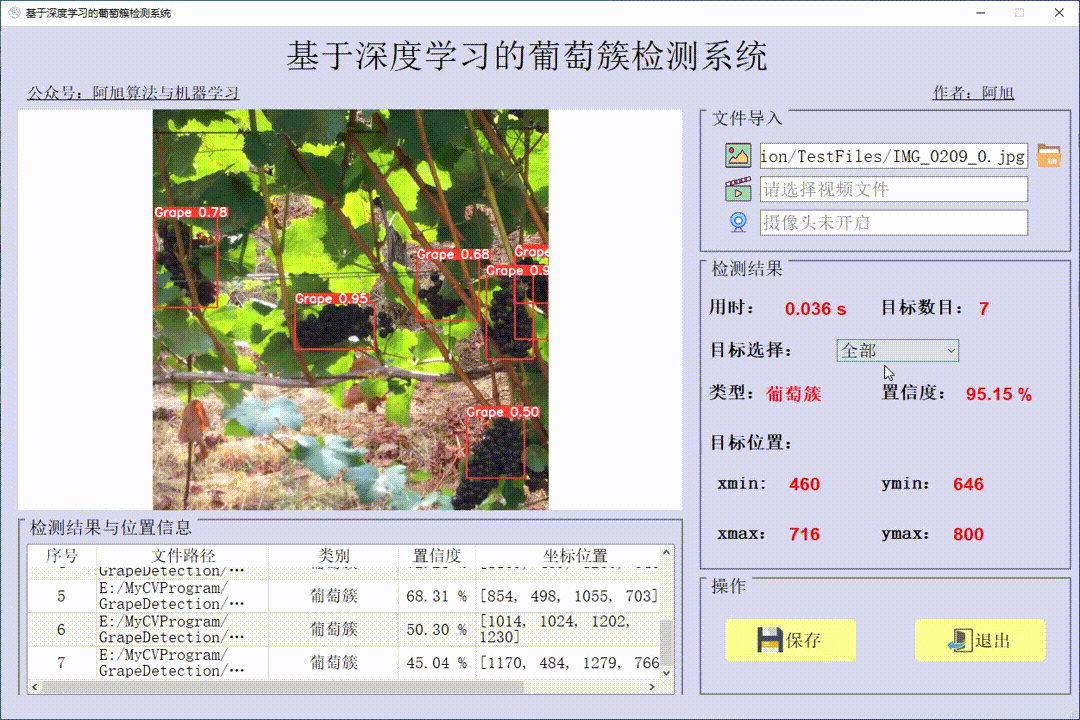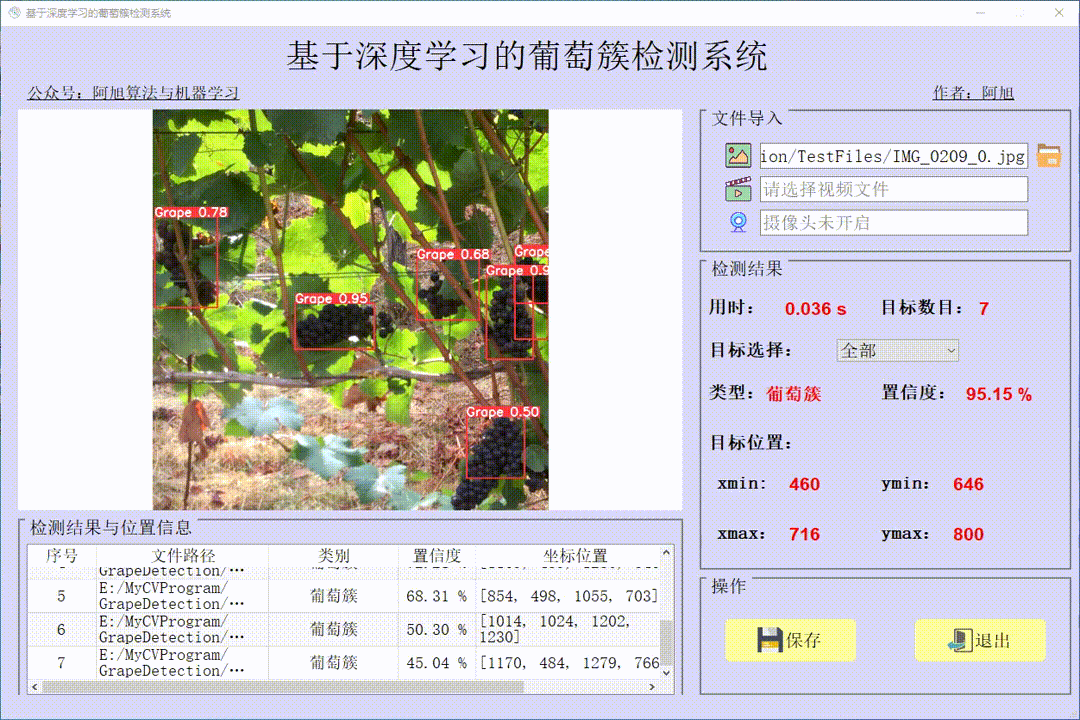
YOLOv8模型部署 (针对道路交通采用多样化场景数据训练的模型 来测试新的场景)
——包含yolov8导出onnx【input shape (1, 3, 544, 960) BCHW ,output shape(s) (1, 10710, 15)】
——包含使用trtexec生成engine文件
——包含使用engine文件部署推理的所有源码
参考:
(1)yolov8之导出onnx(二)_model.export(format=“onnx”)-CSDN博客
说明:
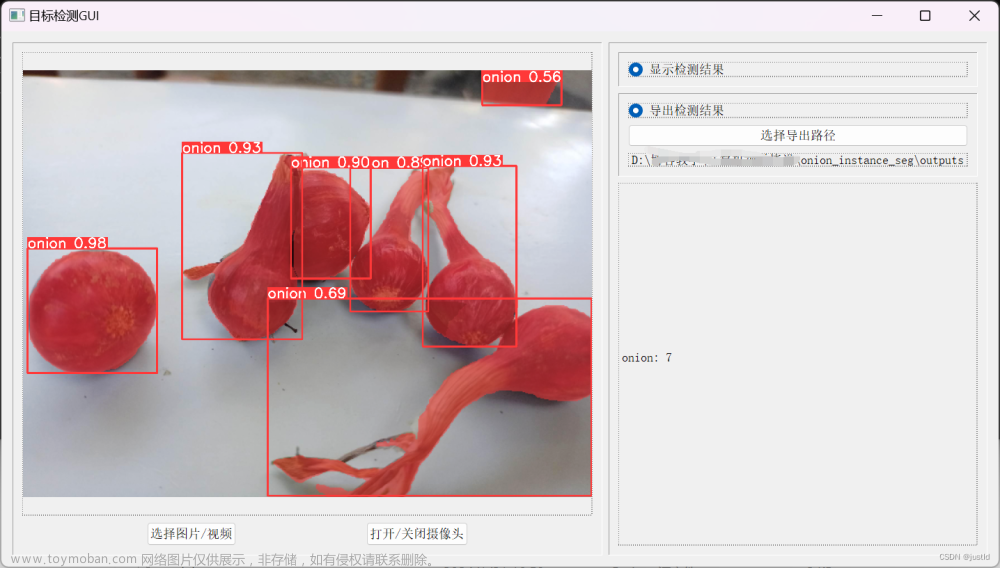
(1)本次针对多样化场景,不同场景取1000+张图片(1920*1080)。
(2)训练YOLOv8模型(包含n和s的模型)
1 训练得到的pt文件转onnx
模型是通过Rect=True, imgsz = 960训练的。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# yolo mode=export model=./weights/best.pt format=onnx imgsz=960,540
from ultralytics import YOLO
model = YOLO("./weights/best.pt")
# success = model.export(format="onnx")
success = model.export(format="onnx", imgsz=[544,960])
上述,若不改变其它源码,则转化过程是input shape (1, 3, 960, 544) BCHW and output shape(s) (1, 15, 10710) 。
为了“ input shape (1, 3, 960, 544) BCHW and output shape(s) (1, 10710, 15) ”
需作源码调整:改变/home/user/anaconda3/envs/yolov8/lib/python3.10/site-packages/ultralytics/nn/modules/head.py中的源码如下,return前增加’y = y.permute(0,2,1)'。
class Detect(nn.Module):
... ...
def forward(self, x):
... ...
y = y.permute(0,2,1)
return y if self.export else (y, x)
2 onnx转engine
# trtexec --onnx=*.onnx --workspace=1024 --best --saveEngine=*.engine --calib=*.calib
# 示例:
/usr/src/tensorrt/bin/trtexec --onnx=best.onnx --workspace=2048 --saveEngine=best_dqjjsy.engine --fp16
3 部署测试源码
目录
code
——testimages # 测试图片集
——testresult # 检测结果(YOLO格式)
——src
————include
src/include/cudaimgproc.cuh
src/include/streamproc.h
————lib
src/lib/cudaimgproc.cu
src/lib/cudaimgproc.o
src/lib/streamproc.cpp
src/lib/streamproc.o
————main.cpp
————main.o
——weight # 模型(engine格式)
——Makefile
Makefile
ifeq ($(VERBOSE), 1)
AT =
else
AT = @
endif
APP := main
CPP = $(AT) g++
NVCC = $(AT) /usr/local/cuda/bin/nvcc -ccbin $(filter-out $(AT), $(CPP))
NVCCFLAGS := -arch=compute_86 -code=sm_86
CPPFLAGS += -std=c++11 \
-I/usr/local/cuda/targets/x86_64-linux/include \
-I/usr/local/cuda/include \
-I/usr/local/include \
-I/usr/local/include/opencv4 \
-I./src/include
LDFLAGS += \
-lpthread -lcuda -lcudart -lnvinfer\
-L/usr/local/cuda/lib64 \
-L/usr/local/cuda/targets/x86_64-linux/lib \
-L/usr/local/lib \
-L./src/lib \
-L/home/dx/workspace/mylibs/hkv \
-lopencv_core -lopencv_imgproc \
-lopencv_videoio -lopencv_highgui -lopencv_imgcodecs
ALL_CPPFLAGS := $(NVCCFLAGS)
ALL_CPPFLAGS += $(addprefix -Xcompiler ,$(filter-out -std=c++11, $(CPPFLAGS)))
SRCS := \
./src/main.cpp \
./src/lib/streamproc.cpp
SCRCS_CU := \
./src/lib/cudaimgproc.cu \
OBJS := $(SRCS:.cpp=.o) $(SCRCS_CU:.cu=.o)
%.o: %.cpp
@echo "Compiling: $<"
$(CPP) $(CPPFLAGS) -o $@ -c $<
%.o: %.cu
@echo "Compiling: $<"
$(NVCC) $(ALL_CPPFLAGS) -o $@ -c $<
$(APP): $(OBJS)
@echo "Linking: $@"
$(CPP) -o $@ $(OBJS) $(CPPFLAGS) $(LDFLAGS)
clean:
rm -f $(APP) $(OBJS)
main.cpp
#include <iostream>
#include <stdio.h>
#include <string>
#include <pthread.h>
#include <chrono>
#include <cuda_runtime.h>
#include <fstream>
#include "streamproc.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
void* video_stream()
{
size_t width = 1920, height = 1080;
// objectdetecter detecter("model.engine");
objectdetecter detecter("/weight/best.engine");
unsigned char *original_image, *d_original_image;
cv::Mat picBGR(height, width, CV_8UC3);
std::vector<std::string> filesPath;
cv::glob("testimages/*", filesPath);
cudaMalloc(&d_original_image, width * height * 3 * sizeof(unsigned char));
std::cout << filesPath.size() << std::endl;
for (auto file : filesPath)
{
cv::Mat org_img = cv::imread(file);
cudaMemcpy(d_original_image, org_img.data, width * height * 3 * sizeof(unsigned char), cudaMemcpyHostToDevice);
std::vector<std::vector<double>> detect_result = detecter.detect(d_original_image, width, height);
std::ofstream txtfile;
file = file.substr(file.find("/") + 1);
txtfile.open("testresults/" + file.substr(0, file.size() - 4) + ".txt", std::ios::trunc | std::ios::in);
for (int i = 0; i < detect_result.size(); i++)
{
txtfile << detect_result[i][4] << " " << detect_result[i][0] / width << " " << detect_result[i][1] / height << " "
<< detect_result[i][2] / width << " " << detect_result[i][3] / height << " " << detect_result[i][5] << "\n";
}
txtfile.close();
}
cudaFree(d_original_image);
return 0;
}
int main()
{
video_stream();
return 0;
}
src/include/cudaimgproc.cuh
#ifndef __CUDAIMGPROC_CUH__
#define __CUDAIMGPROC_CUH__
void gpuConvertNV12touv420(unsigned char *UV, unsigned char *U, unsigned char *V,
size_t width, size_t height);
void gpuConvertBGR_HWCtoNV12(unsigned char *src, unsigned char *d_src_pad, unsigned char *Y, unsigned char *UV,
size_t width, size_t height, int linesize);
void gpuConvertNV12toBGR_HWC(unsigned char *Y, unsigned char *UV, unsigned char *BGR, unsigned char *d_BGR,
size_t width, size_t height, size_t linesize0, size_t linesize1, cudaStream_t stream);
void gpuPreproc(unsigned char *d_BGR, float *d_small,
size_t width, size_t swidth, size_t sheight, size_t pad, cudaStream_t stream);
void gpuinfinit(float *img, size_t width, size_t height);
#endif
src/include/streamproc.h文章来源:https://www.toymoban.com/news/detail-836582.html
#ifndef __HWSTREAMPROC_H__
#define __HWSTREAMPROC_H__
#include <iostream>
#include <string>
#include <vector>
extern "C"
{
#include "libavformat/avformat.h"
#include "libavutil/hwcontext.h"
#include "libavutil/opt.h"
#include "libavcodec/avcodec.h"
}
#include <cuda_runtime_api.h>
#include "NvInfer.h"
#include <chrono>
class objectdetecter
{
private:
cudaStream_t stream;
nvinfer1::IExecutionContext *trt_context;
float *d_input;
float *output;
float *trt_output;
float *trt_input;
size_t in_channel;
size_t in_width;
size_t in_height;
size_t out_col;
size_t out_row;
const char *in_name;
const char *out_name;
public:
objectdetecter(const char *engine_path);
~objectdetecter();
std::vector<std::vector<double>> detect(unsigned char *input, size_t width, size_t height);
};
#endif
src/lib/cudaimgproc.cu文章来源地址https://www.toymoban.com/news/detail-836582.html
#include <cuda_runtime.h>
#include "cudaimgproc.cuh"
__global__ void gpuPreproc_kernel(unsigned char *BGR, float *RGB, size_t width, size_t swidth, size_t sheight, size_t pad)
{
__shared__ float cache[1536];
int idx = blockIdx.x * blockDim.x + threadIdx.x;
float den = 255.0f * 4.0f;
int idx_div = (threadIdx.x / 32) * 192;
int idx_mod = threadIdx.x % 32;
int dimxBGRsize = blockDim.x * 3 * 2;
#pragma unroll
for (int i = 0; i < sheight - pad * 2; i += 4)
{
#pr到了这里,关于YOLOv8模型部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!