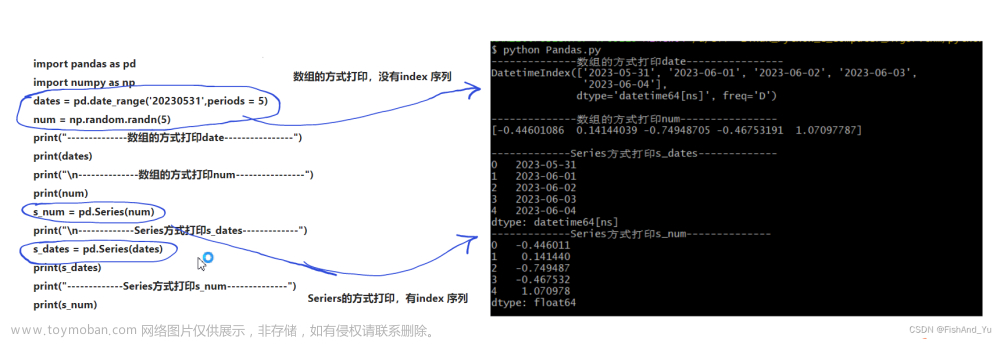
1. 高并发场景
[高并发] - 1. 高并发架构综述
上面文章提到的数据都存在高并发场景。
2. 解决方案
2.1 权限
权限数据的特点是数据量少(一千万),占用的空间大小大概在2G左右,但是性能要求极高。权限数据还有个特点,那就是不读多写少,而且在金融交易系统中,权限的变更一般在非交易时间段做好,例如,每天交易开始前,交易负责人将权限转授权给具体的交易执行人。
基于上述的特点,权限数据采用 “本地缓存 + 数据库” 模式进行存储,本地缓存全量缓存权限数据,且不设置过期时间;写操作采用read/write through的模式,可以保证数据的一致性。权限服务启动时,即刻加载权限数据,预热模式可以保证缓存的命中率为100%,所有的权限数据完全从缓存中获取。
资源的定义通常采用点分式,如何快速的查询用户是否具有某个资源的权限呢?最好的办法是对资源的匹配采用前缀匹配树。这种数据结构的缓存需要我们自研。
对于消息类型的权限,例如某类topic的订阅权限,发布权限,只需要采用caffine等key/value形式的缓存即可。
为了进一步提高性能,权限的校验结果可以缓存到需要进行权限验证的服务中,而且也同样可以根据服务的业务逻辑,预先进行缓存加载。
通过以上所描述的:本地缓存,全量数据缓存,前缀匹配树缓存,本地二级缓存,缓存预加载,可以将单节点的权限并发量达到2-3万/s。再通过多节点间的负载均衡,3节点的权限系统完全能够满足当前的业务需求。
2.2 实时行情
市场行情的特点是数据量大,并发性高,不同场景对实时行情的性能要求截然不同。所以在处理市场行情时,需要分门别类,做好架构设计。实时市场行情由于对延时性的而严格要求,在架构设计上需要特别注意。
设计的业务包括:报价引擎,手动交易,量化交易,风控计算,下单策略(下单到哪个交易所,是否拆单...)
2.2.1 行情接入服务
交易所按照通道将行情进行拆分,一个对接服务通常QPS最高在1万/s,延时能够保证小于10ms。那我们怎么保证行情服务的高并发呢?【高可用:热备(只能一个账号登录),连通性检查】
(1)只做必要的事
只进行反序列化和必要字段校验(非当前交易产品校验省略)。
(2)分流
当前不进行交易的情接收到之后直接路发送到kafka,由spark任务进行参考数据填充,或者与其他行情聚合后,存入hdfs。
当前会进行交易的行情发布到高并发组件Disruptor中[但注意,需要顺序处理的行情需要交给同一线程处理(这里的处理方式我们单独写文章阐述)],然后交给多个消费者并行处理,包含参考数据的填充,行情的聚合,通过高性能的分布式ID系统填充ID...
2.2.2 行情分发
经过上面的分流后,需要真正进行分发的市场行情数据在数据量上有巨大的减小,通过统计,可以降低1/3左右的数据量。但是行情的总体并发量还是非常大,高峰时仍能达到3万/s。
行情的分发是通过消息中间件来实现的,采用实现了AMQP的消息中间件,通过高可扩展的集群模式,能够将处理能力达到10万/s,满足当前的业务需求。
消息中间件需要非常好的处理慢消费者问题,以免影响其他的正常消费者。例如踢出慢消费者,将慢消费者对应队列的消息进行覆盖、丢弃,甚至直接删除对应的队列,进行队列重建。
2.2.3 行情订阅
根据业务逻辑尽量缩小订阅的行情范围,需要考虑流量的突发,做好限流和降级的兜底方案。如果订阅范围已经最小化了,业务逻辑也很单一了,由于行情有需要顺序处理,这种情况下,节点基本不能通过横向扩展来进行负载均衡,这种情况下:
(1)提高硬件配置:提高内存,增加CPU核数...
(2)冷备:高可用还需需要做的,但是如果多个节点同时去订阅,会增加消息中间件的负载,一般采用冷备;
(3)行情的主动丢弃:消费能力实在跟不上的时候,需求主动丢弃一些行情,丢弃的逻辑可以根据业务需求进行定制化,例如同一产品的行情,使用最新的行情覆盖之前未被消费的行情。
2.2.4 行情stale
还有一种导致行情并发性极高的场景,那就是每天闭市后,需要将行情支撑stale,如果不加以限流,会导致QPS达到10万/s以上。但是这种场景比较好处理,因为已经闭市,不再影响交易,直接对其进行限流,保证QPS在1万/s以下,慢慢消费处理。
2.3 历史行情
历史行情的数据量大,并发性高,但是由于对延时性的要求不高,可以采用的架构比较多。
2.3.1 存档,报表
本着数据就是石油的观点,我们需要尽可能的将接入的行情进行保存,毕竟买市场行情也是花了很多钱的。
采用吞吐量高的消息中间件kafka进行行情转发,并且尽可能的不丢失行情(在实时行情中,可以适当丢弃)。为了提高吞吐量,可以放宽延时性能。
2.3.2 算法分析和策略回归
为了验证量化算法和策略,需要使用历史行情。这些场景不会,也不该对交易产生影响。对延时要求不是特别高,但是由于涉及到的数据量大,而且延时也不能太高,否则策略可能要花很长的时间才能跑完。因此,我们将这部分需要进行验证的行情进行缓存,采用的是分布式缓存ignite。
2.3.3 curve计算
这个的业务场景设计到绝大部分行情,缓存放不下,而且对延时性要求介于缓存和hdfs之间,我们采用列式存储db cassandra进行存储,也可以作为hdfs的一种数据备份。
通过上面的分析,我们直到行情根据数据量,延时要求,是否进行交易,进行了不同的设计来满足架构要求。cassandra和ignite的集群模式能够达到并发性的要求。
2.4 交易
交易的特点是每天的量不算大,在百万级别,但是由于量化交易和做市交易的存在,导致QPS在高峰时能够达到1万/s,而且需要保证数据不丢失。 【高可用,DB和file同时存储】
2.4.1 价格填充
报价引擎。
2.4.2 权限校验
2.1已经阐述过。
2.4.3 风控检查
为了提高性能,风控检查是内部计算的,准确度不高,但效率高。
2.4.4 订单下发
到此之后,订单对延时性的要求已经没有了,只需要关系每次交易所下发的成交信息来更新订单状态即可。
就近机房下方到交易所。
2.4.5 订单状态维护
接收到下发的交易信息后,更新订单状态。
2.5 监控
监控的特点是数据量大,写并发性高,读并发性低,而且数据的丢失容忍度大,延时可以接收分钟级别。因此采用spark进行统计,采样,计算,输出。
2.6 报价
报价的数据量大,并发性高,而且消息体特别大,对延时性要求也比较高。我们采用snapshot与delta并行的架构来达到要求。
通常交易员会维护多个产品的报价,维护的产品越多,会导致封装的对象越大,而且字段也很多,如果其中任何一个产品的一个字段变动都触发一次整体消息传输,对导致带宽,延时,吞吐量都受到极大的影响,因此,我们维护一个时间点的snashot,然后每个字段变更,只发送这个字段的变更delta数据,可以极大的提高吞吐量,还能降低延时。当delta的变动超过一定比例时,更新一次snapshot。
2.7 风控
风控的主要特点是结算特定截面的数据,计算完毕之后同一推送消息,所以导致间隔式的高并发场景。我们的解决方案是,每隔计算界面使用version区分,计算完一部分指标就推送一部分指标,展示的时候等到需要展示的指标全部有最新version数据后同一使用最新version同一展示给交易员查询。文章来源:https://www.toymoban.com/news/detail-836678.html
这个不会导致内存由于存储了两个version的风控指标数据而剧增,因此风控一天的数据量也就500万左右,每个切面的数据总量占内存也就在几百兆。文章来源地址https://www.toymoban.com/news/detail-836678.html
到了这里,关于[高并发] - 2. 金融交易系统高并发架构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!