一.Hive调优--存储和压缩方式
1.Hive压缩方式:
压缩方式类似于windows的压缩包, 可以降低传输, 提高磁盘利用率.
区分压缩协议好坏的参考维度:
1. 压缩比, 即: 压缩后文件大小.
2. 解压速度, 即: 读的速度.
3. 压缩速度, 即: 写的速度.
推荐使用:
GZIP: 压缩后文件相对较小, 压缩 和 解压速度相对较慢.
Snappy: 压缩后文件相对大一点, 压缩 和 解压速度非常快.2. Hive表存储方式
分为 行存储 和 列存储两种:
行存储: TextFile(默认), SequenceFile
列存储: ORC(推荐), Parquet
行存储:
优点: select * 效率高.
缺点: select 列 效率低, 每列数据类型不一致, 密集度较低, 占用资源较多(CPU, 磁盘, 内存)
列存储:
优点: select 列 效率高, 每列数据类型一致, 密集度较高, 占用资源较少(CPU, 磁盘, 内存)
缺点: select * 效率低.
二.Hive调优--Fetch抓取
核心点:
在执行HiveSQL的时候, 能不转MR, 就不转MR.
设置方式:
set hive.fetch.task.conversion=fetch抓取的模式;
Fetch抓取模式介绍:
more: 默认的, 全表扫描, 查询指定的列, limit分页查询, 简单查询不走MR, 其它的要转MR任务.
minimal: 全表扫描, 查询指定的列, limit分页查询不走MR, 其它的要转MR任务.
none: 所有的HiveSQL, 底层都要转MR.
三.Hive调优--本地模式
核心点:
如果HiveSQL必须要转成MR任务来执行, 则尽量在本机(本地)直接执行, 而不是交由Yarn来调度执行, 针对于数据量比较小的需求, 可以提高效率.
相关设置:
--开启本地mr
set hive.exec.mode.local.auto=true;
--设置local mr的最大输入数据量,当输入数据量小于这个值时采用local mr的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=134217728;
--设置local mr的最大输入文件个数,当输入文件个数小于这个值时采用local mr的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=4;
四.Hive调优--join优化
小表join大表:
开启Map段的join, 在内存中完成处理, 避免把join的动作交给ReduceTask段来处理, 出现数据倾斜的情况.
参考如下配置, 即: 设置map端join
set hive.auto.convert.join = true; -- 默认为true 开启mapJoin支持
set hive.mapjoin.smalltable.filesize= 25000000; --设置 小表的最大的数据量 20多M
大表join大表:
思路1: 空key过滤, 降低处理的数据量.
思路2: 空key转换, 必须大量的null值, 提高数据的处理数据.
五.Hive调优--SQL优化
A. 列裁剪.
能写 select 列1, 列2... 就不要写 select *
B. 分区裁剪
编写SQL的时候, 能使用分区条件, 建立一定要写分区字段.
C. 开启负载均衡.
如果key分布不均, 就可能导致数据倾斜的问题(Group by数据倾斜), 可以通过 开启负载均衡解决.
开启负载均衡之后, 如果遇到了GroupBy数据倾斜问题, 程序的底层会开启两个MR任务,
第1个MR负责将(发生数据倾斜的)数据随机打散, 交由不同的ReduceTask任务来处理, 获取结果.
第2个MR会将 第1个MR的结果当做数据源来处理, 进行最终的合并动作, 获取最终结果.
开启负载均衡的代码如下:
set hive.groupby.skewindata=true;
D.关于去重统计的问题.
如果数据量相对较小, 可以直接写: select count(distinct id列) from 表名; 去重统计, 底层会转成1个MR任务.
如果数据量相对较大, 上述的SQL语句, 可能会执行失败, 就可以通过 group by + count的思路来解决, 具体如下:
select count(id列) from (select id from 表名 group by id) t1; 底层会转2个MR任务.
E.关于笛卡尔积.
实际开发中, 尽量避免出现笛卡尔积的情况, 可以节约资源, 提高查询效率.
例如:
1. 写join连接的时候, 别忘记写关联条件, 且关联条件别写错.
2. 关联条件尽量写到on中, 而不是where中, 即: 尽量使用显式连接, 而不是隐式内连接.
3. 如果join的时候, 关联字段不清楚, 记得找 业务人员, 需求方, 数据库管理员对接.
六.Hive调优--动态分区
建议动态分区的时候, 关闭严格模式(默认开启), 严格模式要求: 动态分区的时候, 至少指定1个静态分区.
格式:
动态分区: partition(分区字段)
静态分区: partition(分区字段=值)
重点参数:
set hive.exec.dynamic.partition.mode=nonstrict; -- 开启非严格模式 默认为 strict(严格模式)
set hive.exec.dynamic.partition=true; -- 开启动态分区支持, 默认就是true
可选参数:
set hive.exec.max.dynamic.partitions=1000; -- 在所有执行MR的节点上,最大一共可以创建多少个动态分区。
set hive.exec.max.dynamic.partitions.pernode=100; -- 每个执行MR的节点上,最大可以创建多少个动态分区
set hive.exec.max.created.files=100000; -- 整个MR Job中,最大可以创建多少个HDFS文件七.Hive调优--并行度和并行执行机制
并行度解释:
即: 根据业务要求, 增大或者减少MapTask 和 ReduceTask的任务数.
例如: 大量的小文件, 就会有大量的Block块, 就有大量的MapTask任务, 针对于这种情况: 我们可以使用归档技术, 把多个小文件合并成1个大文件, 降低MapTask任务数.
例如: 1个Block块 = 1个MapTask任务, 但是业务逻辑较复杂, 1个MapTask处理速度肯定较慢, 可以增大MapTask任务数.
例如: 1个ReduceTask任务 = 1个最终的结果文件, 增大或者减少ReduceTask任务数, 可以调整最终落盘到磁盘上的结果文件数.
并行执行:
默认Hive同一时间只能执行1个阶段, 如果多个阶段之间的依赖度比较低, 就可以开启并行执行, 让多个阶段同时执行, 降低MR job任务的执行时间.
set hive.exec.parallel=true; -- 打开任务并行执行 默认false
set hive.exec.parallel.thread.number=16; -- 同一个sql允许最大并行度,默认为8。
八.Hive调优--严格模式
核心点:
禁用低效的SQL.
设置方式:
set hive.mapred.mode=strict | nonstrict;
细节:
1. 这个严格模式是禁用低效的SQL, 和动态分区的严格模式没有任何关系.
2. 严格模式是禁用低效的SQL, 例如, 如下的SQL是禁止执行的:
A. 分区表, 查询时, 没有写分区字段.
B. order by全局排序时, 没有写limit
C. 禁用笛卡尔积.
九.Hive调优--JVM重用
当MR任务执行结束后, Yarn创建的Container资源容器不会立即销毁, 而是可以重复使用.
原因:
如果遇到大量生命周期短的MR任务时, 频繁的创建和销毁Container资源容器是非常消耗资源的.文章来源:https://www.toymoban.com/news/detail-836859.html
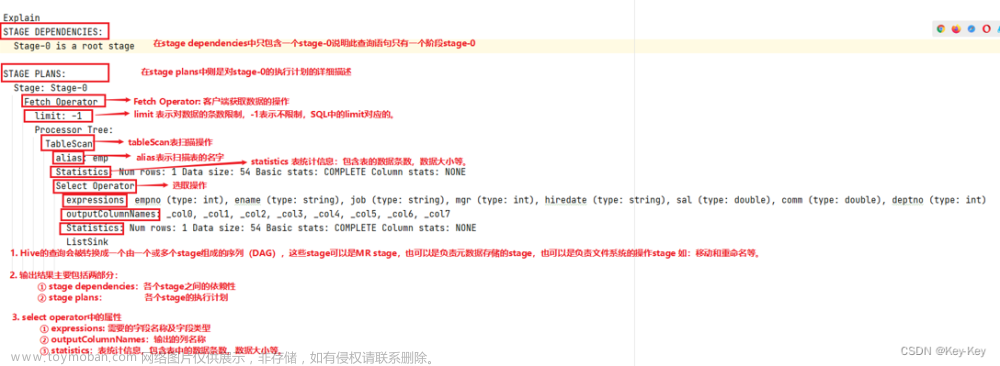
十.Hive调优--explain执行计划
格式:
explain HiveSQL语句
作用:
可以查看HiveSQL语句的执行计划, 即: 把该SQL分成了几个阶段来执行, 阶段越少, 相对执行速度越快.文章来源地址https://www.toymoban.com/news/detail-836859.html
到了这里,关于Hive调优的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!