YOLO系列算法属于基于回归的单阶段目标检测算法,它将定位与分类两个任务整合成一个任务,直接通过CNN网络提取全局信息并预测图片上的目标。给目标检测算法提供了新的解决方案,并且图片检测速度准确率与召回率达到实时检测的要求。其中YOLOv1、YOLO2、YOLOv3是著名学者Redmon 在2016~2018年分别提出的,网络深度逐渐增加的同时,检测速度与召回率准确率不断提升。YOLOv4是俄罗斯学者Alexey在2020年4月份提出该算法继承了YOLO3[1]的主干网络是Darknet-53并融合了各个目标检测算法中先进的结构与技巧,YOLOv4融入了新的主干网络CSPDarknet-53l以及数据增强技巧和余弦退火训练策略,是此前最先进的目标检测算法之一。
Yolov5是一系列在COCO数据集上预先训练的对象检测架构和模型,最早于2020年五月提出,代表了uUliayics公司对未来视觉A方法的开源研究,结合了数千小时的研究和开发过程中学到的经验教训和最佳实践。
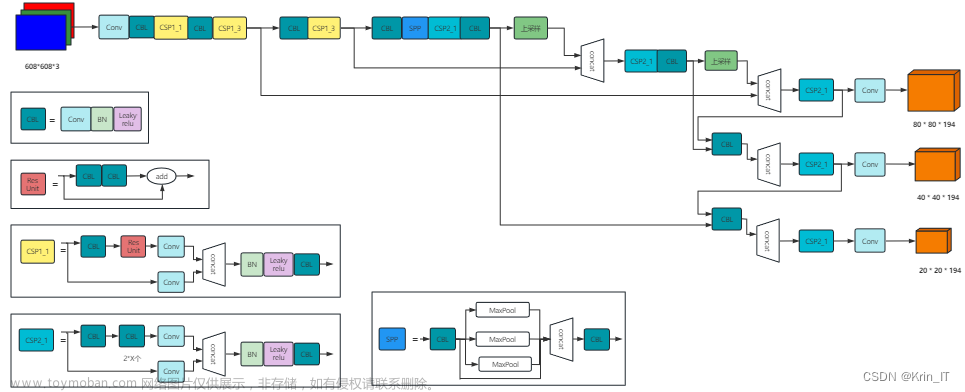
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolovsm、Yolov5l、Yolov5x四个模型。通过调节yaml文件中的depth_mutipe和width_multiple就能改变主干网络中卷积的宽度和深度,进而满足不同群体对于不同性能的需求。其中Yolov5s模型最小,运行最快,但检测结果相对较差,而Yolov5x模型最大,运行最慢,但检测效果最佳。Yolov5中的检测主干网络新增了Focus结构,SiLU激活函数,SPP结构等等。如下图所示。
网络结构
Yolov5的网络结构主要分为两个部分。首先是主干网络,用于特征提取;其次是检测网络,利用主干网络接取到的有效特征,进行特征的进一步增强提取,最后得出分类和定位结果。
网络构建
网络的整体构建主要分为Backbone,和Detect两个部分。其中Backbone负责提取图片的特征图,而Detect部分负责继续增强提炼特征并进行目标的分类和定位工作。
Backbone构建
Backbone可以被称作yolov5的主干特征提取网络,根据它的结构以及之前Yolo主干的叫法,我一般叫它CSPDarknet,输入的图片首先会在CSPDarknet里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了三个特征层进行下一步网络的构建,这三个特征层我称它为有效特征层。
Backbone的结构比较复杂,我们需要将其拆分讲解,这里面包括了Conw模块,Bottleneck模块,BottleneckCSP模块,SPP模块,Focus模块。
主干网络 (Backbone)
下图是主干网络,进行特征提取获得三个有效特征层。其中的核心组件是Conv模块和C3模块。C3模块又是用多个Bottleneck模块组成。Conv模块中包含标准化和激活。

主干网络结构图
Backbone的整体结构如上图所示,首先输入的图像数据经过focus模块进行切片操作降低图像的宽高,然后经过多轮conv和C3以及一个SPP模块进一步压缩特征图的宽高,最终backbone的第5,7,10个模块输出的有效特征图将被Detect部分利用到。
核心组件
BottleneckCSP
BottleneckCSP是网络的核心组件,它在两个分支里都利用Conv提取特征后,在其中一个分支继续使用n*个Botleneck模块进行特征抽象。之后将两个分支concat之后进行卷积。

C3模块结构图
Bottleneck模块
Bottleneck模块:标准Bottleneck模块先将特征通道数减小再扩大(默认减小到一半),若需要shortcut操作,则不改变特征通道数直接将输入和卷积层的输出进行相加。Botleneck是主干网络中的重要组件,是一种类似于resnet中的残差网络结构。这样做的目的是为了保留部分原始特征,以免一些有意义的特征再网络的特征提取阶段被忽略。

Bottleneck模块结构图
Conv模块
Conv模块:该模块定义了一个标准的卷积层,其中包含一个Conv2d,一个 BN层,以及一个SiLU(Swish)激活函数。Conv模块是网络的最基本组成部分,由于现阶段的目标检测网络深度大,为了防止梯度爆炸或者弥散现象的发生采取了各种措施,其中Yolov5中使用了Bn层和SiLu激活函数加以优化。其中算法的前期主干网络提取特征的部分,卷积的stride为2这样做的目的是减小特征图的大小,不断抽象出有意义的特征的同时减少后续网络的计算量。与之不同,网络后期detect的部分卷积的stride为1,不再减小特征图的尺寸。

Conv模块结构图
下图分别是Swish激活函数和SiLU激活函数,SiLU函数是Swish激活函数的一种特殊情况,这类激活函数具备无上界有下界、平滑、非单调的特性,在深层模型上效果优于ReLU。Swish激活函数的公式为f(x)=x *σ(βx ) ,SiLU激活函数的公式为f (x)=x * σ (x)


Swish激活函数 SiLU激活函数
Focus模块
Focus模块,将输出的每一个channel进行切片后Concat到一起再使用一个标准卷积模块进行输出。该模块减小特征图的长和宽,增加特征图的深度,以保留各个位置的特征信息,该模块可以取代步长为2的卷积操作来降低特征尺寸,减小模型计算量的同时,保留原始信息。

Focus模块结构图
SPP模块
SPP模块,包含两个标准卷积模块和3个最大池化层。先使用一个标准卷积模块将通道数减少,然后将其通过多个不同尺度最大池化层后,将其他与未池化的数据Concat到一起,再经过一个标准卷积模块将特征通道数进行修正。

SPP模块结构图
检测网络
主要包含两部分:
加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。用于利用backbone提取出的不同深度的特征图来在小中大三个尺度上对目标进行分类定位。
分类器与回归器,即Yolo Head。通过主干网络和加强特征提取网络,我们已经可以获得三个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每一个特征点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点中的特征进行分类和回归,与以往版本的yolo算法相同,分类和回归在一个1X1卷积里实现。
YOLO部分

这部分包含了backobone以及特征增强部分。其中特征增强网络结构如图所示。首先通过backbone网络提取出三种不同程度的特征图feature_map1, feature_map2,feature map3。然后不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。值得注意的是这里的下采样使用的是stride为2的conv模块进行代替,这样做的目的是可以最大程度保留特征图的语义信息。
DetectionBlock模块
DetectionBlock模块用于将预测结果进一步编码到0到1之间以便计算损失或进行结果预测,并按照需求进行封装。
损失函数
损失函数分为三个部分:
第一部分是CIOUloss,它将重叠面积、中心点距离、宽高比同时加入计算,反映正样本和对应真值框的位置关系和形状大小契合程度,该部分越小代表着预测框的位置信息越准确。
第二部分是置信度损失,计算所有正样本置信度和对应真值框的置信度标签的二值交叉嫡,以及所有负样本的置信度和0之间的二值交叉熵并求和,置信度本身代表预测框中含有某种目标物体并将其框准的置信程度,置信度损失结果越小代表预测框的置信度结果越准确。
第三部分是类别损失,计算正样本和对应真值框种类的二值交叉熵并求合,代表的是对于种类判断的准确程度,结果越小代表判断的越准确。


yolov5使用CIOU loss来衡量矩形框的损失。它将重叠面积、中心点距离、宽高比同时加入了计算。

损失函数计算
最终整个损失函数是将loss l, loss m, loss s三者加权相加得到整体的损朱函数后,再利用优化器对网络的模型参数进行更新。
解码过程
对于yolo系列算法来说,它的预测框都是根据anchor加上4个参数来映射到bounding box也就是预测框,那么具体的映射公式在每个版本的yolo算法都有些许变化,
对于给定的anchor而言,本身具有四个值来描述他的位置信息,c _x ,c y p _w p_h分别代表的是anchor默认的中心点的横纵坐标和宽高尺寸。而每一个anchor网络都会给四个值进行预测,分别是t _x ,t_y ,t _w ,t_h,用于调整anchor的横纵坐标和宽高。具体公式如下:


预测框解码示意图
下图对比了yolov3和yolov5对于边界框边长预测输出的解码效果。yolov5在默认放大系数为2的情况下最多能够将预测框的边长扩大到anchor的4倍,而采用yolov3的方式则能够预测到无穷大的边界框,但是这种效果并不是我们期望的,因为图像本身的尺寸有限,多余的值域并不会带来增益,反而会导致输入端轻微的噪声就能对输出带来巨大影响,不利于网络训练。

解码效果对比
YOLOv5总体实现
包含了网络的全部结构,其输出为预测值的编码结果。图像首先经过backoone网络提取到三个有效特征层,然后经过YOLO模块得到三个特征增强有效特征层。最后利用detectionblock得到分类、定位的编码结果。
模型训练
接下来进行模型训练,yolov5模型训练可以分为:定义损失函数、优化器以及加载预训练模型并进行训练。
损失函数
通过YoloLossBlock模块可以根据输入的's' , 'm','l'对三个尺度的预测结果分别定义不同的损失函数。首先定义IOU模块以及GIOU模块。IOU实际上就是预测框与真实框的交并比值。IOU损失函数就是1-IOU,用来反映预测框与真实框的重合程度。
GIOU是IOU的升级版,想要计算GIOU,要经过—下三个步骤:
(1)首先对于两个需要计算IOU的对象A和B,找到一个最小的集合C能囊括A和B
(2)然后按照常规先计算A和B的IOU
(3)使用IOU减去{ (集合C中既不属于A也不属于B的部分)/集合C的总面积}
也就是说,GIOU最大只能和IOU相等,不会大于IOU,同时,其最小值也不会小于-1,当且仅当两BOX a和b相隔很远且ICU为时才接近-1。由此可知,GiOU位于区间(-1,1]内。这样GIOU的大小就可以很好的衡量box的预测准确与否,同时也解决了IOU为零时的优化方向问题,使得GIOU尽可能大就好并且它也具有IOU原本的尺度不变性的优点。

 文章来源:https://www.toymoban.com/news/detail-836992.html
文章来源:https://www.toymoban.com/news/detail-836992.html
网络训练前的基本设置
·选择算法的版本包括s、m、l、x,这里使用s版本。
·定义优化器,这里使用nn.Momentum优化器,原理可以参考论文on the importance of initialization and momentum in deep learming
·对模型进行初始化。
·对模型进行预训练模型加载。
·完成数据集的加载。
文章来源地址https://www.toymoban.com/news/detail-836992.html
到了这里,关于深度学习基础——YOLOv5目标检测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!