这篇文章相当长,您可以添加至收藏夹,以便在后续有空时候悠闲地阅读。
本章因太长所以分为上下篇来上传,文章末尾有下篇链接
很多⼈在处理分类变量时都会遇到很多困难,因此这值得⽤整整⼀章的篇幅来讨论。在本章中,我将 讲述不同类型的分类数据,以及如何处理分类变量问题。
什么是分类变量?
分类变量/特征是指任何特征类型,可分为两⼤类: ⽆序 ,有序
⽆序变量 是指有两个或两个以上类别的变量,这些类别没有任何相关顺序。例如,如果将性别分为两 组,即男性和⼥性,则可将其视为名义变量。
有序变量 则有 "等级 "或类别,并有特定的顺序。例如,⼀个顺序分类变量可以是⼀个具有低、中、⾼ 三个不同等级的特征。顺序很重要。
就定义⽽⾔,我们也可以将分类变量分为 ⼆元变量 ,即只有两个类别的分类变量。有些⼈甚⾄把分类变量称为 " 循环 "变量。周期变量以 "周期 "的形式存在,例如⼀周中的天数: 周⽇、周⼀、周⼆、周三、周四、周五和周六。周六过后,⼜是周⽇。这就是⼀个循环。另⼀个例⼦是⼀天中的⼩时数,如果我们将它们视为类别的话。
分类变量有很多不同的定义,很多⼈也谈到要根据分类变量的类型来处理不同的分类变量。不过,我认为没有必要这样做。所有涉及分类变量的问题都可以⽤同样的⽅法处理。开始之前,我们需要⼀个数据集(⼀如既往)。要了解分类变量,最好的免费数据集之⼀是 Kaggle 分类特征编码挑战赛中的 cat-in-the-dat 。共有两个挑战,我们将使⽤第⼆个挑战的数据,因为它⽐前⼀个版本有更多变量,难度也更⼤。
让我们来看看数据。
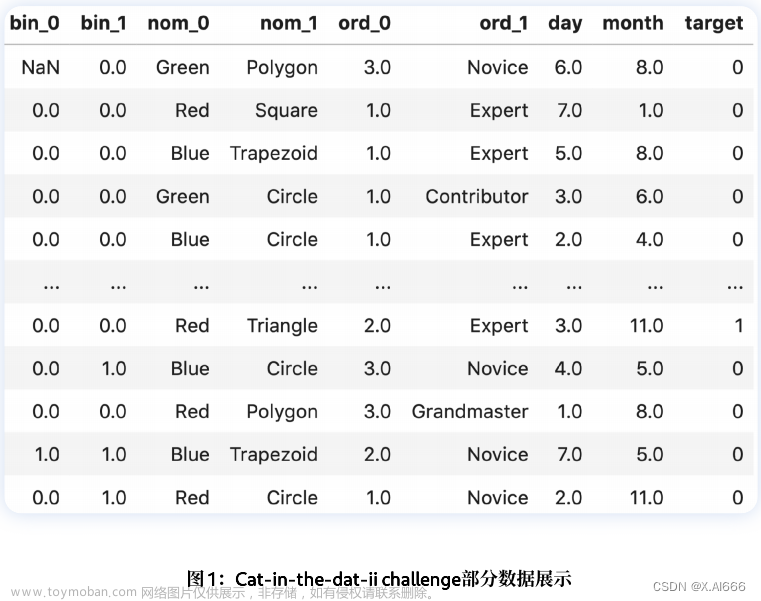
数据集由各种分类变量组成: ⽆序, 有序, 循环, ⼆元
在图 1 中,我们只看到所有存在的变量和⽬标变量的⼦集。
这是⼀个⼆元分类问题。
⽬标变量对于我们学习分类变量来说并不⼗分重要,但最终我们将建⽴⼀个端到端模型,因此让我们看看图 2 中的⽬标变量分布。我们看到⽬标是 偏斜 的,因此对于这个⼆元分类问题来说,最好的指标是 ROC 曲线下⾯积(AUC)。我们也可以使⽤精确度和召回率,但 AUC 结合了这两个指标。因此,我们将使⽤ AUC 来评估我们在该数据集上建⽴的模型。

总体⽽⾔,有:
5个⼆元变量
10个⽆序变量
6个有序变量
2个循环变量
1个⽬标变量
让我们来看看数据集中的 ord_2 特征。它包括6个不同的类别:
冰冻
温暖
寒冷
较热
热
⾮常热
我们必须知道,计算机⽆法理解⽂本数据,因此我们需要将这些类别转换为数字。⼀个简单的⽅法是创建⼀个字典,将这些值映射为从 0到 N-1 的数字,其中 N 是给定特征中类别的总数。
mapping = {
"Freezing" : 0 ,
"Warm" : 1 ,
"Cold" : 2 ,
"Boiling Hot" : 3 ,
"Hot" : 4 ,
"Lava Hot" : 5
}
现在,我们可以读取数据集,并轻松地将这些类别转换为数字。
import pandas as pd
df = pd.read_csv(" . /input/cat_train.csv")
df.loc[:, "*ord_2*"] = df.*ord_2*.map(mapping)映射前的数值计数:
df . * ord_2 * . value_counts ()
Freezing 142726
Warm 124239
Cold 97822
Boiling Hot 84790
Hot 67508
Lava Hot 64840
Name : * ord_2 * , dtype : int64
映射后的数值计数:
0.0 142726
1.0 124239
2.0 97822
3.0 84790
4.0 67508
5.0 64840
Name : * ord_2 * , dtype : int64
这种分类变量的编码⽅式被称为标签编码(Label Encoding)我们将每个类别编码为⼀个数字标签。我们也可以使⽤ scikit-learn 中的 LabelEncoder 进⾏编码。
import pandas as pd
from sklearn import preprocessing
df = pd.read_csv(" . /input/cat_train.csv")
df.loc[:, "*ord_2*"] = df.*ord_2*.fillna("NONE")
lbl_enc = preprocessing.LabelEncoder()
df.loc[:, "*ord_2*"] = lbl_enc.fit_transform(df.*ord_2*.values)你会看到我使⽤了 pandas 的 fillna。原因是 scikit-learn 的 LabelEncoder ⽆法处理 NaN 值,⽽
ord_2 列中有 NaN 值。
我们可以在许多基于树的模型中直接使⽤它:
决策树
随机森林
提升树
或任何⼀种提升树模型
XGBoost
GBM
LightGBM
这种编码⽅式不能⽤于线性模型、⽀持向量机或神经⽹络,因为它们希望数据是标准化的。
对于这些类型的模型,我们可以对数据进⾏⼆值化(binarize)处理。

这只是将类别转换为数字,然后再转换为⼆值化表⽰。这样,我们就把⼀个特征分成了三个(在本例中)特征(或列)。如果我们有更多的类别,最终可能会分成更多的列。
如果我们⽤稀疏格式存储⼤量⼆值化变量,就可以轻松地存储这些变量。稀疏格式不过是⼀种在内存中存储数据的表⽰或⽅式,在这种格式中,你并不存储所有的值,⽽只存储重要的值。在上述⼆进制变量的情况中,最重要的就是有 1 的地⽅。
很难想象这样的格式,但举个例⼦就会明⽩。
假设上⾯的数据帧中只有⼀个特征: ord_2 。


⽬前,我们只看到数据集中的三个样本。让我们将其转换为⼆值表⽰法,即每个样本有三个项⽬。
这三个项⽬就是三个特征。

因此,我们的特征存储在⼀个有 3 ⾏ 3 列(3x3)的矩阵中。矩阵的每个元素占⽤ 8 个字节。因此,这个数组的总内存需求为 8x3x3 = 72 字节。
我们还可以使⽤⼀个简单的 python 代码段来检查这⼀点。
import numpy as np example = np.array( [ [0, 0, 1], [1, 0, 0], [1, 0, 1] ] ) print(example.nbytes)
这段代码将打印出 72,就像我们之前计算的那样。但我们需要存储这个矩阵的所有元素吗?如前所述,我们只对 1 感兴趣。0并不重要,因为任何与 0相乘的元素都是 0,⽽ 0与任何元素相加或相减也没有任何区别。只⽤ 1 表⽰矩阵的⼀种⽅法是某种字典⽅法,其中键是⾏和列的索引,值是 1:

这样的符号占⽤的内存要少得多,因为它只需存储四个值(在本例中)。使⽤的总内存为 8x4 = 32 字节。任何 numpy 数组都可以通过简单的 python 代码转换为稀疏矩阵。
import numpy as np from scipy import sparse example = np.array( [ [0, 0, 1], [1, 0, 0], [1, 0, 1] ] ) sparse_example = sparse.csr_matrix(example) print(sparse_example.data.nbytes)
这将打印 32,⽐我们的密集数组少了这么多!稀疏 csr 矩阵的总⼤⼩是三个值的总和。
print( sparse_example.data.nbytes + sparse_example.indptr.nbytes + sparse_example.indices.nbytes )
这将打印出 64 个元素,仍然少于我们的密集数组。遗憾的是,我不会详细介绍这些元素。你可以在scipy ⽂档中了解更多。当我们拥有更⼤的数组时,⽐如说拥有数千个样本和数万个特征的数组,⼤⼩差异就会变得⾮常⼤。例如,我们使⽤基于计数特征的⽂本数据集。
import numpy as np
from scipy import sparse
n_rows = 10000
n_cols = 100000
example = np.random.binomial(1, p=0.05, size=(n_rows, n_cols))
print(f"Size of dense array: {example.nbytes}")
sparse_example = sparse.csr_matrix(example)
print(f"Size of sparse array: {sparse_example.data.nbytes}")
full_size = (
sparse_example.data.nbytes +
sparse_example.indptr.nbytes +
sparse_example.indices.nbytes
)
print(f"Full size of sparse array: {full_size}")这将打印:
Size of dense array : 8000000000
Size of sparse array : 399932496
Full size of sparse array : 599938748
因此,密集阵列需要 ~8000MB 或⼤约 8GB 内存。⽽稀疏阵列只占⽤ 399MB 内存。
这就是为什么当我们的特征中有⼤量零时,我们更喜欢稀疏阵列⽽不是密集阵列的原因。
请注意,稀疏矩阵有多种不同的表⽰⽅法。这⾥我只展⽰了其中⼀种(可能也是最常⽤的)⽅法。
尽管⼆值化特征的稀疏表⽰⽐其密集表⽰所占⽤的内存要少得多,但对于分类变量来说,还有⼀种转换所占⽤的内存更少。这就是所谓的 " 独热编码 "。
独热编码也是⼀种⼆值编码,因为只有 0 和 1 两个值。但必须注意的是,它并不是⼆值表⽰法。我们可以通过下⾯的例⼦来理解它的表⽰法。
假设我们⽤⼀个向量来表⽰ ord_2 变量的每个类别。这个向量的⼤⼩与 ord_2 变量的类别数相同。在这种特定情况下,每个向量的⼤⼩都是 6,并且除了⼀个位置外,其他位置都是 0。让我们来看看这个特殊的向量表。

我们看到向量的⼤⼩是 1x6,即向量中有6个元素。这个数字是怎么来的呢?如果你仔细观察,就会发现如前所述,有6个类别。在进⾏独热编码时,向量的⼤⼩必须与我们要查看的类别数相同。每个向量都有⼀个 1,其余所有值都是 0。现在,让我们⽤这些特征来代替之前的⼆值化特征,看看能节省多少内存。
如果你还记得以前的数据,它看起来如下:

每个样本有3个特征。但在这种情况下,独热向量的⼤⼩为 6。因此,我们有6个特征,⽽不是3个。 

因此,我们有 6 个特征,⽽在这个 3x6 数组中,只有 3 个1。使⽤ numpy 计算⼤⼩与⼆值化⼤⼩计算脚本⾮常相似。你需要改变的只是数组。让我们看看这段代码。
import numpy as np
from scipy import sparse
example = np.array(
[
[0, 0, 0, 0, 1, 0],
[0, 1, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0]
]
)
print(f"Size of dense array: {example.nbytes}")
sparse_example = sparse.csr_matrix(example)
print(f"Size of sparse array: {sparse_example.data.nbytes}")
full_size = (
sparse_example.data.nbytes +
sparse_example.indptr.nbytes +
sparse_example.indices.nbytes
)
print(f"Full size of sparse array: {full_size}")打印内存⼤⼩为:
Size of dense array : 144
Size of sparse array : 24
Full size of sparse array : 52
我们可以看到,密集矩阵的⼤⼩远远⼤于⼆值化矩阵的⼤⼩。不过,稀疏数组的⼤⼩要更⼩。让我们⽤更⼤的数组来试试。在本例中,我们将使⽤ scikit-learn 中的 OneHotEncoder 将包含 1001 个类别的特征数组转换为密集矩阵和稀疏矩阵。
import numpy as np
from sklearn import preprocessing
example = np.random.randint(1000, size=1000000)
ohe = preprocessing.OneHotEncoder(sparse=False)
ohe_example = ohe.fit_transform(example.reshape(-1, 1))
print(f"Size of dense array: {ohe_example.nbytes}")
ohe = preprocessing.OneHotEncoder(sparse=True)
ohe_example = ohe.fit_transform(example.reshape(-1, 1))
print(f"Size of sparse array: {ohe_example.data.nbytes}")
full_size = (
ohe_example.data.nbytes +
ohe_example.indptr.nbytes +
ohe_example.indices.nbytes
)
print(f"Full size of sparse array: {full_size}")上⾯代码打印的输出:
Size of dense array : 8000000000
Size of sparse array : 8000000
Full size of sparse array : 16000004
这⾥的密集阵列⼤⼩约为 8GB,稀疏阵列为 8MB。如果可以选择,你会选择哪个?在我看来,选择很简单,不是吗?
这三种⽅法(标签编码、稀疏矩阵、独热编码)是处理分类变量的最重要⽅法。不过,你还可以⽤很多其他不同的⽅法来处理分类变量。将分类变量转换为数值变量就是其中的⼀个例⼦。
假设我们回到之前的分类特征数据(原始数据中的 cat-in-the-dat-ii)。在数据中, ord_2 的值为“热
“的 id 有多少?
我们可以通过计算数据的形状(shape)轻松计算出这个值,其中 ord_2 列的值为 Boiling Hot 。
In [ X ]: df [ df . ord_2 = "Boiling Hot" ]. shape
Out [ X ]: ( 84790 , 25 )
我们可以看到,有 84790 条记录具有此值。我们还可以使⽤ pandas 中的 groupby 计算所有类别的该值。
In [ X ]: df . groupby ([ "ord_2" ])[ "id" ]. count ()
Out [ X ]:
ord_2
Boiling Hot 84790
Cold 97822
Freezing 142726
Hot 67508
Lava Hot 64840
Warm 124239
Name : id , dtype : int64
如果我们只是将 ord_2 列替换为其计数值,那么我们就将其转换为⼀种数值特征了。我们可以使⽤
pandas 的 transform 函数和 groupby 来创建新列或替换这⼀列。
In [ X ]: df . groupby ([ "ord_2" ])[ "id" ]. transform ( "count" )
Out [ X ]:
0 67508.0
1 124239.0
2 142726.0
3 64840.0
4 97822.0
.
599995 142726.0
599996 84790.0
599997 142726.0
599998 124239.0
599999 84790.0
Name : id , Length : 600000 , dtype : float64
你可以添加所有特征的计数,也可以替换它们,或者根据多个列及其计数进⾏分组。例如,以下代码 ,通过对 ord_1 和 ord_2 列分组进⾏计数。
In [ X ]: df . groupby (
. : [
. : "ord_1" ,
. : "ord_2"
. : ]
. : )[ "id" ]. count (). reset_index ( name = "count" )
Out [ X ]:
ord_1 ord_2 count
0 Contributor Boiling Hot 15634
1 Contributor Cold 17734
2 Contributor Freezing 26082
3 Contributor Hot 12428
4 Contributor Lava Hot 11919
5 Contributor Warm 22774
6 Expert Boiling Hot 19477
7 Expert Cold 22956
8 Expert Freezing 33249
9 Expert Hot 15792
10 Expert Lava Hot 15078
11 Expert Warm 28900
12 Grandmaster Boiling Hot 13623
13 Grandmaster Cold 15464
14 Grandmaster Freezing 22818
15 Grandmaster Hot 10805
16 Grandmaster Lava Hot 10363
17 Grandmaster Warm 19899
18 Master Boiling Hot 10800
.
请注意,我已经从输出中删除了⼀些⾏,以便在⼀⻚中容纳这些⾏。这是另⼀种可以作为功能添加的计数。您现在⼀定已经注意到,我使⽤ id 列进⾏计数。不过,你也可以通过对列的组合进⾏分组,对其他列进⾏计数。
还有⼀个⼩窍⻔,就是从这些分类变量中创建新特征。你可以从现有的特征中创建新的分类特征,⽽且可以毫不费⼒地做到这⼀点。
In [ X ]: df [ "new_feature" ] = (
. : df . ord_1 . astype ( str )
. : + "_"
. : + df . ord_2 . astype ( str )
. : )
In [ X ]: df . new_feature
Out [ X ]:
0 Contributor_Hot
1 Grandmaster_Warm
2 nan_Freezing
3 Novice_Lava Hot
4 Grandmaster_Cold
.
599999 Contributor_Boiling Hot
Name : new_feature , Length : 600000 , dtype : object
在这⾥,我们⽤下划线将 ord_1 和 ord_2 合并,然后将这些列转换为字符串类型。请注意,NaN 也会转换为字符串。不过没关系。我们也可以将 NaN 视为⼀个新的类别。这样,我们就有了⼀个由这两个特征组合⽽成的新特征。您还可以将三列以上或四列甚⾄更多列组合在⼀起。
In [ X ]: df [ "new_feature" ] = (
. : df . ord_1 . astype ( str )
. : + "_"
. : + df . ord_2 . astype ( str )
. : + "_"
. : + df . ord_3 . astype ( str )
. : )
In [ X ]: df . new_feature
Out [ X ]:
0 Contributor_Hot_c
1 Grandmaster_Warm_e
2 nan_Freezing_n
3 Novice_Lava Hot_a
4 Grandmaster_Cold_h
.
599999 Contributor_Boiling Hot_b
Name : new_feature , Length : 600000 , dtype : object
那么,我们应该把哪些类别结合起来呢?这并没有⼀个简单的答案。这取决于您的数据和特征类型。⼀些领域知识对于创建这样的特征可能很有⽤。但是,如果你不担⼼内存和 CPU 的使⽤,你可以采⽤⼀种贪婪的⽅法,即创建许多这样的组合,然后使⽤⼀个模型来决定哪些特征是有⽤的,并保留它们。我们将在本书稍后部分介绍这种⽅法。
⽆论何时获得分类变量,都要遵循以下简单步骤:
1,填充 NaN 值(这⼀点⾮常重要!)。
2,使⽤ scikit-learn 的 LabelEncoder 或映射字典进⾏标签编码,将它们转换为整数。如果没有填充NaN 值,可能需要在这⼀步中进⾏处理
3,创建独热编码。是的,你可以跳过⼆值化!
4,建模!我指的是机器学习。
在分类特征中处理 NaN 数据⾮常重要,否则您可能会从 scikit-learn 的 LabelEncoder 中得到臭名昭著的错误信息:
ValueError: y 包含以前未⻅过的标签: [Nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan, nan)
这仅仅意味着,在转换测试数据时,数据中出现了 NaN 值。这是因为你在训练时忘记了处理它们。 处理 NaN 值 的⼀个简单⽅法就是丢弃它们。虽然简单,但并不理想。NaN 值中可能包含很多信息,如果只是丢弃这些值,就会丢失这些信息。在很多情况下,⼤部分数据都是 NaN 值,因此不能丢弃NaN 值的⾏/样本。处理 NaN 值的另⼀种⽅法是将其作为⼀个全新的类别。这是处理 NaN 值最常⽤的⽅法。如果使⽤ pandas,还可以通过⾮常简单的⽅式实现。
请看我们之前查看过的数据的 ord_2 列。
In [ X ]: df . ord_2 . value_counts ()
Out [ X ]:
Freezing 142726
Warm 124239
Cold 97822
Boiling Hot 84790
Hot 67508
Lava Hot 64840
Name : ord_2 , dtype : int64
填⼊ NaN 值后,就变成了
In [ X ]: df . ord_2 . fillna ( "NONE" ). value_counts ()
Out [ X ]:
Freezing 142726
Warm 124239
Cold 97822
Boiling Hot 84790
Hot 67508
Lava Hot 64840
NONE 18075
Name : ord_2 , dtype : int64
哇!这⼀列中有 18075 个 NaN 值,⽽我们之前甚⾄都没有考虑使⽤它们。增加了这个新类别后,类别总数从 6 个增加到了 7 个。这没关系,因为现在我们在建⽴模型时,也会考虑 NaN。相关信息越多,模型就越好。
假设 ord_2 没有任何 NaN 值。我们可以看到,这⼀列中的所有类别都有显著的计数。其中没有 "罕⻅ "类别,即只在样本总数中占很⼩⽐例的类别。现在,让我们假设您在⽣产中部署了使⽤这⼀列的模型,当模型或项⽬上线时,您在 ord_2 列中得到了⼀个在训练中不存在的类别。在这种情况下,模型管道会抛出⼀个错误,您对此⽆能为⼒。如果出现这种情况,那么可能是⽣产中的管道出了问题。如果这是预料之中的,那么您就必须修改您的模型管道,并在这六个类别中加⼊⼀个新类别。这个新类别被称为 "罕⻅ "类别。罕⻅类别是⼀种不常⻅的类别,可以包括许多不同的类别。您也可以尝试使⽤近邻模型来 "预测 "未知类别。请记住,如果您预测了这个类别,它就会成为训练数据中的⼀个类别。

当我们有⼀个如图 3 所⽰的数据集时,我们可以建⽴⼀个简单的模型,对除 "f3 "之外的所有特征进⾏训练。这样,你将创建⼀个模型,在不知道或训练中没有 "f3 "时预测它。我不敢说这样的模型是否能带来出⾊的性能,但也许能处理测试集或实时数据中的缺失值,就像机器学习中的其他事情⼀样,不尝试⼀下是说不准的。
如果你有⼀个固定的测试集,你可以将测试数据添加到训练中,以了解给定特征中的类别。这与半监督学习⾮常相似,即使⽤⽆法⽤于训练的数据来改进模型。这也会照顾到在训练数据中出现次数极少但在测试数据中⼤量存在的稀有值。你的模型将更加稳健。
很多⼈认为这种想法会过度拟合。可能过拟合,也可能不过拟合。有⼀个简单的解决⽅法。如果你在设计交叉验证时,能够在测试数据上运⾏模型时复制预测过程,那么它就永远不会过拟合。这意味着第⼀步应该是分离折叠,在每个折叠中,你应该应⽤与测试数据相同的预处理。假设您想合并训练数据和测试数据,那么在每个折叠中,您必须合并训练数据和验证数据,并确保验证数据集复制了测试集。在这种特定情况下,您必须以这样⼀种⽅式设计验证集,使其包含训练集中 "未⻅ "的类别。
 只要看⼀下图 4 和下⾯的代码,就能很容易理解其⼯作原理。
只要看⼀下图 4 和下⾯的代码,就能很容易理解其⼯作原理。
import pandas as pd
from sklearn import preprocessing
train = pd.read_csv(" . /input/cat_train.csv")
test = pd.read_csv(" . /input/cat_test.csv")
test.loc[:, "target"] = -1
data = pd.concat([train, test]).reset_index(drop=True)
features = [x for x in train.columns if x not in ["id", "target"]]
for feat in features:
lbl_enc = preprocessing.LabelEncoder()
temp_col = data[feat].fillna("NONE").astype(str).values
data.loc[:, feat] = lbl_enc.fit_transform(temp_col)
train = data[data.target = -1].reset_index(drop=True)
test = data[data.target = -1].reset_index(drop=True)当您遇到已经有测试数据集的问题时,这个技巧就会起作⽤。必须注意的是,这⼀招在实时环境中不起作⽤。例如,假设您所在的公司提供实时竞价解决⽅案(RTB)。RTB 系统会对在线看到的每个⽤⼾进⾏竞价,以购买⼴告空间。这种模式可使⽤的功能可能包括⽹站中浏览的⻚⾯。我们假设这些特征是⽤⼾访问的最后五个类别/⻚⾯。在这种情况下,如果⽹站引⼊了新的类别,我们将⽆法再准确预测。在这种情况下,我们的模型就会失效。这种情况可以通过使⽤ " 未知 " 类别来避免 。
在我们的 cat-in-the-dat 数据集中, ord_2 列中已经有了未知类别
In [ X ]: df . ord_2 . fillna ( "NONE" ). value_counts ()
Out [ X ]:
Freezing 142726
Warm 124239
Cold 97822
Boiling Hot 84790
Hot 67508
Lava Hot 64840
NONE 18075
Name : ord_2 , dtype : int64
我们可以将 "NONE "视为未知。因此,如果在实时测试过程中,我们获得了以前从未⻅过的新类别,我们就会将其标记为 "NONE"。
这与⾃然语⾔处理问题⾮常相似。我们总是基于固定的词汇建⽴模型。增加词汇量就会增加模型的⼤⼩。像 BERT 这样的转换器模型是在 ~30000 个单词(英语)的基础上训练的。因此,当有新词输⼊时,我们会将其标记为 UNK(未知)。 文章来源:https://www.toymoban.com/news/detail-837061.html
因此,您可以假设测试数据与训练数据具有相同的类别,也可以在训练数据中引⼊罕⻅或未知类别,以处理测试数据中的新类别。文章来源地址https://www.toymoban.com/news/detail-837061.html
到了这里,关于解决分类变量问题的完整指南:处理方式及技巧的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!








