自然语言处理(NLP)的进步往往通过在各种benchmark测试集上的表现来衡量。随着多语言和跨语言NLP研究的兴起,越来越多的多语言测试集被提出以评估模型在不同语言和文化背景下的泛化能力。在这篇文章中,我们将介绍几个主流的多语言NLP benchmark测试集,包括ARC Challenge、HellaSWAG、MMLU、Multi-tasking Test Generation (MTG)、PAWS-X、XNLI、X-StoryCloze和XCOPA等。
其中XNLI、xcopa是推理题。
arc、hellaswag、mmlu是选择题。
MTG、PAWS-X是翻译相关。
xstorycloze是续写类任务。
AI2 Reasoning Challenge (ARC)(英)
ARC数据集被设计用来测试和挑战机器对科学问题的理解和推理能力,尤其是针对中学生水平的科学问题。数据集分为两个子集:
-
ARC Easy: 这部分包含那些容易被信息检索系统回答或者被人类学生广泛正确回答的问题。这些问题通常较为简单,需要的推理和背景知识相对较少。
-
ARC Challenge: 这部分包含更难的问题,它们通常不能简单地通过在互联网上查找得到答案,需要更深层的推理和更广泛的背景知识。ARC Challenge旨在挑战现有的AI系统,并推动科学问题解答和推理能力的研究。文章来源:https://www.toymoban.com/news/detail-837085.html
两个子集都是为了评价系统在科学问题解答上的能力,但ARC Challenge针对的是更高难度的问题,而ARC Easy则包含相对容易的问题。在使用这些数据集进行研究和评估时,研究者通常会分别报告在这两个子集上的表文章来源地址https://www.toymoban.com/news/detail-837085.html
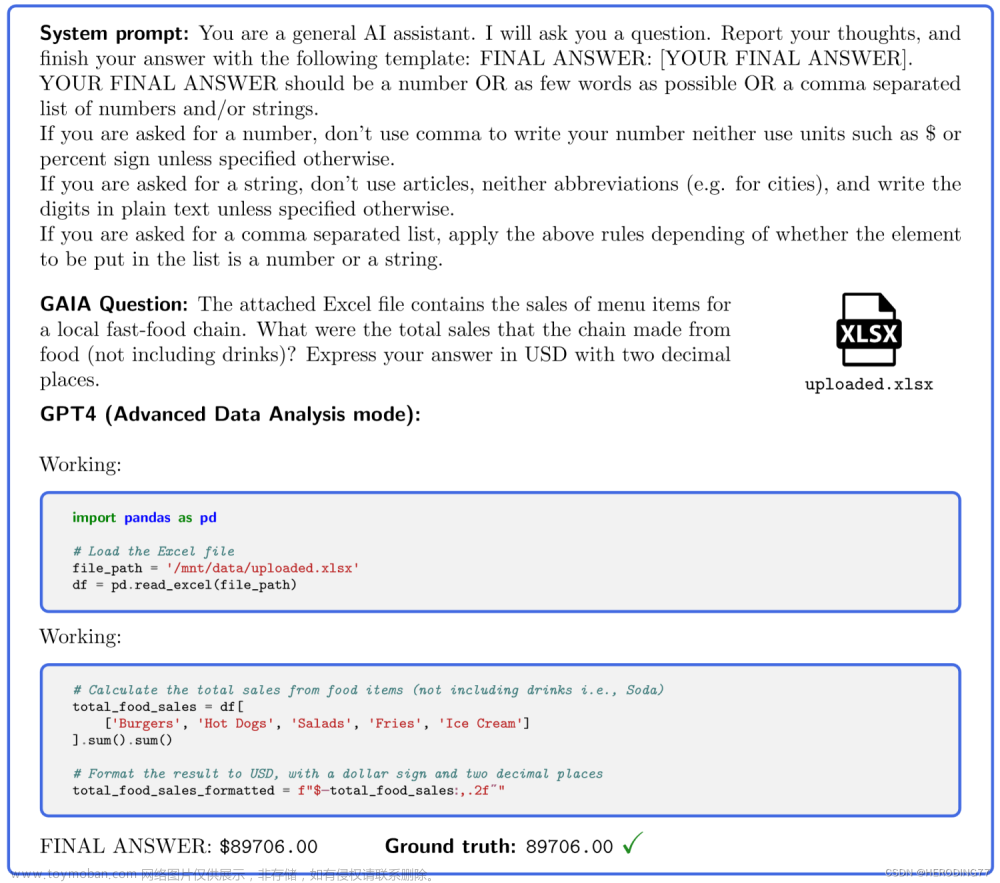
到了这里,关于[论文笔记] 大模型主流Benchmark测试集介绍的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!