前言
终于开写本CV多模态系列的核心主题:stable diffusion相关的了,为何执着于想写这个stable diffusion呢,源于三点
- 去年stable diffusion和midjourney很火的时候,就想写,因为经常被刷屏,但那会时间错不开
- 去年11月底ChatGPT出来后,我今年1月初开始写ChatGPT背后的技术原理,而今年2月份的时候,一读者“天之骄子呃”在我这篇ChatGPT原理文章下面留言:“点赞,十年前看你的svm懂了,但感觉之后好多年没写了,还有最近的AI绘画 stable diffusion 相关也可以写一下以及相关的采样加速算法
我当时回复到:哈,十年之前了啊,欢迎回来,感谢老读者、老朋友
确实非常非常多的朋友都看过我那篇SVM笔记,影响力巨大,但SVM笔记之后,也还是写了很多新的博客/文章滴,包括但不限于:xgboost、CNN、RNN、LSTM、BERT等
今后基本每季度都有更新的计划,欢迎常来
关于Stable Diffusion,可以先看下这篇图解Stable Diffusion的文章”(此篇文章也是本文的参考之一) - 今年3月中旬,当OpenAI宣称GPT4具备了CV多模态的能力之后,让我对AI绘画和CV多模态有了更强的动力去研究探索,并把背后的技术细节写出来
其实当时就想写了,但当时因为写各种开源平替模型的原理、部署、微调去了,所以一直没来得及写,包括之前计划的100篇论文也因此耽搁
4.23,我所讲的ChatGPT原理课开课之后,终于有时间开写这篇多模态博客,然想写清楚stable diffusion和midjourney背后的技术细节,不得不先从扩散模型开始,于此便有了上一篇《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/MAE/Swin transformer》「且如果你此前不了解何谓扩散模型、何谓DDPM,务必先看该文,不然没法看懂本文」
援引上一篇文章的这段话“AI绘画随着去年stable diffusion和Midjourney的推出,使得文生图火爆异常,各种游戏的角色设计、网上店铺的商品/页面设计都用上了AI绘画这样的工具,更有不少朋友利用AI绘画取得了不少的创收,省时省力还能赚钱,真香”,此外,包括我司LLM项目团队开发的AIGC模特生成系统也用到了这方面的技术:基于SD二次开发
沿着上文之后,本文将写清楚下面表格中带下划线的模型
| 1月 | 3月 | 4月 | 5月 | 6月 | 8月 | 9月 | 10月 | 11月 | |
| 20年 | DETR | DDPM | DDIM VisionTransf.. |
||||||
| 21年 | CLIP DALL·E |
SwinTransformer | MAE SwinTransf..V2 |
||||||
| 22年 | BLIP | DALL·E 2 | StableDiffusion BEiT-3 Midjourney V3 |
||||||
| 23年 | BLIP2 | VisualChatGPT GPT4 Midjourney V5 |
SAM(Segment Anything Model) | FastSAM (中科院版SAM) MobileSAM |
DALLE3 |
且过程中会顺带介绍MiniGPT-4、VisualGPT到HuggingGPT、AutoGPT这几个模型
第一部分 从CLIP到BLIP1、BLIP2
1.1 CLIP:基于对比文本-图像对的预训练方法
我第一次见识到CLIP这个论文的时候,当时的第一反应是,特么也太强悍了..
CLIP由OpenAI在2021年1月发布
- 通过超大规模模型预训练提取视觉特征,进行图片和文本之间的对比学习 (简单粗暴理解就是发微博/朋友圈时,人喜欢发一段文字然后再配一张或几张图,CLIP便是学习这种对应关系)
- 且预训练好之后不微调直接推理 (即zero-shot,用见过的图片特征去判断没见过的图片的类别,而不用下游任务训练集进行微调)
使得在ImageNet数据集上,CLIP模型在不使用ImageNet数据集的任何一张图片进行训练的的情况下,最终模型精度能跟一个有监督的训练好的ResNet-50打成平手 (在ImageNet上zero-shot精度为76.2%,这在之前一度被认为是不可能的)
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对,论文称之为WIT(Web Image Text,WIT质量很高,而且清理的非常好,其规模相当于JFT-300M,这也是CLIP如此强大的原因之一,后续在WIT上还孕育出了DALL-E模型)
其训练过程如下图所示:

- 如下图的第一步所示,CLIP的输入是一对对配对好的的图片-文本对(比如输入是一张狗的图片,对应文本也表示这是一只狗),这些文本和图片分别通过Text Encoder和Image Encoder输出对应的特征。然后在这些输出的文字特征和图片特征上进行对比学习
假如模型输入的是对图片-文本对,那么这对互相配对的图像–文本对是正样本(上图输出特征矩阵对角线上标识蓝色的部位),其它对样本都是负样本,这样模型的训练过程就是最大化个正样本的相似度,同时最小化个负样本的相似度
Text Encoder可以采用NLP中常用的text transformer模型
而Image Encoder可以采用常用CNN模型或者vision transformer等模型
相似度是计算文本特征和图像特征的余弦相似性cosine similarity
之后,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练和微调,其实现zero-shot分类只需要简单的两步,如下第2、3点所示 - 根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为n,那么将得到n个文本特征
- 将要预测的图像送入Image Encoder得到图像特征,然后与n个文本特征计算缩放的余弦相似度(和训练过程保持一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果
进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率
以下是对应的伪代码
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - 输入图片维度
# T[n, l] - 输入文本维度,l表示序列长度
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征d_e,并进行l2归一化,保持数据尺度的一致性
# 多模态embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0) # image loss
loss_t = cross_entropy_loss(logits, labels, axis=1) # text loss
loss = (loss_i + loss_t)/2 # 对称式的目标函数2021年10月,Accomplice发布的disco diffusion,便是第一个结合CLIP模型和diffusion模型的AI开源绘画工具,其内核便是采用的CLIP引导扩散模型(CLIP-Guided diffusion model)
且后续有很多基于CLIP的一系列改进模型,比如Lseg、GroupViT、ViLD、GLIP
1.2 从BLIP1、BLIP2到miniGPT4
1.2.1 BLIP1:ViT + BERT ——通过encoder-decoder统一理解与生成任务
随着AI的迅速发展,多模态日渐成为一种趋势,而「Vision-Language Pre-training (VLP) + Fine-tuning => Zero Shot / Few Shot」的模式是快速解决多下游任务的一个好的模式,VLP 是这个模式的开端,所以对于 VLP 的相关研究也很多。BLIP 是一个新的 VLP 架构,可以灵活、快速的应用到下游任务,如:图像-文本检索、图像翻译、以及 VQA 等
简单来讲,BLIP的主要特点是结合了encoder和decoder,形成了统一的理解和生成多模态模型。再利用BLIP进行后续工作的时候,既可以使用其理解的能力(encoder),又可以利用其生成的能力(decoder),拓展了多模态模型的应用
1.2.1.1 BLIP的模型结构
CLIP 采用了 image-encoder (ViT / ResNet) & text-encoder (transformer),然后直接拿 图片特征 和 文本特征 做余弦相似度对比,得到结果,而BLIP 的做法要复杂挺多
如下图所示,为了预训练一个同时具有理解和生成能力的统一模型,BLIP模型主要由4个部分组成,从左至右分别是

-
上图第1部分:视觉编码器Image Encoder(ViT)——提取图片特征
视觉编码器本质就是 ViT 的架构:将输入图像分割成一个个的 Patch 并将它们编码为一系列 Image Embedding,并使用额外的 [CLS] token 来表示全局的图像特征 -
上图第2部分:文本编码器Text Encoder(BERT)——提取文本特征
文本编码器就是 BERT 的架构,其中 [CLS] token 附加到文本输入的开头以总结句子,作用是提取文本特征与第1部分的图像特征做对比学习
在这个过程中会训练一个对比学习目标函数 (Image-Text Contrastive Loss, ITC)
ITC 作用于第1部分的视觉编码器(ViT)和第2部分的文本编码器(BERT),目标是对齐视觉和文本的特征空间,方法是使得正样本图文对的相似性更大,负样本图文对的相似性更低,在 ALBEF 里面也有使用到。作者在这里依然使用了 ALBEF 中的动量编码器,它的目的是产生一些伪标签,辅助模型的训练
为方便对比,把BLIP的模型结构图再贴一遍
-
上图第3部分:视觉文本编码器Image-grounded Text Encoder(变种 BERT)——BERT中插入交叉注意层,从而针对图片特征和文本特征做二分类
视觉文本编码器的具体做法是在文本编码器比如BERT的每个transformer block的自注意(Bi Self-Att)层和前馈网络(Feed Forward)之间额外插入一个交叉注意(Cross-Attention),以引入视觉特征,作用是根据 ViT 给的图片特征和文本输入做二分类,所以使用的是编码器,且注意力部分是双向的 Self-Attention,且添加一个额外的 [Encode] token,作为图像文本的联合表征
在这个过程中则训练一个图文匹配目标函数 (Image-Text Matching Loss, ITM)
ITM 作用于第1部分的视觉编码器和第3部分的视觉文本编码器,是一个二分类任务,目标是学习图像文本的联合表征,使用一个分类头来预测 image-text pair 的 正匹配 还是 负匹配,目的是学习 image-text 的多模态表示,调整视觉和语言之间的细粒度对齐,作者在这里依然使用了 ALBEF 中的 hard negative mining 技术
-
上图第4部分:视觉文本解码器Image-grounded Text Decoder(变种 BERT)——根据图片特征和文本特征做文本生成
视觉文本解码器使用 Cross-Attention,作用是根据 ViT 给的图片特征和文本输入做文本生成的任务,所以使用的是解码器,且将 上图第3部分的 Image-grounded Text Encoder 结构中的 Bi Self-Att 替换为 Causal Self-Att,目标是预测下一个 token,且添加一个额外的 [Decode] token 和结束 token,作为生成结果的起点和终点
一个需要注意的点是:相同颜色的部分是参数共享的,即视觉文本编码器和视觉文本解码器共享除 Self-Attention 层之外的所有参数。每个 image-text 在输入时,image 部分只需要过一个 ViT 模型,text 部分需要过3次文本模型
过程中训练一个语言模型目标函数 (Language Modeling Loss, LM)
毕竟由于BLIP 包含解码器,用于生成任务。既然有这个任务需求,那就意味着需要一个针对于生成任务的语言模型目标函数,LM 作用于第1部分的视觉编码器和第4部分的视觉文本解码器,目标是根据给定的图像以自回归方式来生成关于文本的描述。与 VLP 中广泛使用的 MLM 损失(完形填空)相比,LM 使模型能够将视觉信息转换为连贯的字幕
1.2.1.2 BLIP的字幕与过滤器方法CapFiltg
上述整个过程中,有一个不可忽略的问题,即高质量的人工注释图像-文本对(例如,COCO) 因为成本高昂所以数量不多
- CLIP 的数据来源于 Web 上爬来的 图像-文本对,所以数据集很容易扩充的很大,而且采用 对比学习的方式,基本属于自监督了,不太需要做数据标注;
- BLIP 改进了 CLIP 直接从 Web 取数据 噪声大 的缺点,提出了 Captioning and Filtering (CapFilt) 模块,这个模块就是用来 减小噪声、丰富数据的,主要包括两个模块:即字幕与过滤器方法CapFilt (Captioning and Filtering)
如下图所示

CapFilt 方法包含两个模块:
- 字幕器 Captioner:相当于给一张网络图片,生成字幕。它是一个视觉文本解码器(对应于上述BLIP模型结构的第4部分),在 COCO数据集上使用 LM 目标函数微调,对给定图像的文本进行解码,从而实现给定网络图片,Captioner 生成字幕的效果
-
过滤器 Filter:过滤掉噪声图文对image-text pair,它是一个视觉文本编码器(对应于上述BLIP模型结构的第3部分),看文本是否与图像匹配,在 COCO 数据集上使用 ITC 和 ITM 目标函数微调
Filter 删除原始 Web 文本和合成文本 中的嘈杂文本,如果 ITM 头将其预测为与图像不匹配,则认为文本有噪声
最后,将过滤后的图像-文本对与人工注释对相结合,形成一个新的数据集,作者用它来预训练一个新的模型
下图展示了被过滤器接受和拒绝的文本可视化(绿色 文本是被 filter 认可的,而 红色 文本是被 filter 拒绝的)

1.2.2 BLIP2:CLIP ViT-G/14 + Q-Former + FLAN-T5
下图是BLIP-2的模型结构 (论文地址:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models),其中视觉侧和文本侧分别使用预训练的CLIP ViT-G/14模型和FLAN-T5模型,仅中间的起桥接作用的Q-Former参与训练,训练需要的成本和数据量进一步降低,BLIP-2的训练数据量仅129M,16卡A100训练9天

- 后来的LLAVA工作更是将这一思路简化到极致,仅通过一个projection layer将CLIP ViT-L/14和Vicuna语言模型缝合在一起,训练数据仅用了595K图文对以及158K指令微调数据
- miniGPT4则是在复用BLIP-2的vision encoder + Q-Former的基础上,通过一层project layer缝合了Vicuna语言模型,训练数据仅用了5M的图文对数据+3.5K的指令微调数据
1.2.3 MiniGPT4:基于LLaMA微调的Vicuna + BLIP2 + 线性投影层
MiniGPT-4具有许多类似于GPT-4所展示的功能,如详细的图像描述生成和从手写草稿创建网站,以及根据给定图像编写灵感的故事和诗歌,为图像中显示的问题提供解决方案,比如教用户如何根据食物照片烹饪等
模型结构
miniGPT4的模型架构由一个语言模型拼接一个视觉模型,最后加一个线性投影层来对齐,具体而言

-
它先是使用基于LLaMA微调的小羊驼Vicuna,作为语言解码器
-
在视觉感知方面,采用了与BLIP-2相同的预训练视觉组件(该组件由EVA-CLIP[13]的ViT- G/14和Q-Former组成)
-
再之后,增加了一个单一的投影层,将编码的视觉特征与语言模型小羊驼对齐,并冻结所有其他视觉和语言组件
模型训练:预训练(500万图像文本对)-微调
训练上,还是经典的预训练-微调模式
- 在整个预训练过程中,无论是预训练的视觉编码器还是LLM都保持冻结状态,只有线性投影层被预训练。具体是使用Conceptual Caption、SBU和LAION的组合数据集来训练我们的模型,历经2万个训练步骤,批大小为256,覆盖了大约500万对图像-文本,整个过程花费大约10小时,且使用的4个A100 (80GB) gpu
- 然而,简单地将视觉特征与LLM对齐不足以训练出像聊天机器人那样具有视觉会话能力的高性能模型,并且原始图像-文本对背后的噪声可能导致语言输出不连贯。因此,我们收集了另外3500个高质量对齐的图像-文本对,用设计好的会话模板进一步微调模型(只需要400个训练步骤,批量大小为12,使用单个A100 GPU最终7分钟即可完成),以提高生成语言的自然度及其可用性
第二部分 从DALLE到DALLE 2、DALLE 3
2.1 DALL-E:Zero-Shot Text-to-Image Generation
有趣的是,DALL-E和CLIP一样,也是21年年初发布的,对应论文为《Zero-Shot Text-to-Image Generation》,其参数大小有着12B,其数据集是2.5 亿个图像文本对
- 通过上一篇文章可知,VQ-VAE的生成模式是pixcl-CNN +codebook,其中pixcl-CNN就是一个自回归模型
- OpenAI 将pixcl-CNN换成GPT,再加上那会多模态相关工作的火热进展,可以考虑使用文本引导图像生成,所以就有了DALL·E

DALL·E和VQ-VAE-2一样,也是一个两阶段模型:
-
Stage1:Learning the Visual Codebook
先是输入:一对图像-文本对(训练时),之后编码特征,具体编码时涉及到两个步骤
首先,文本经过BPE编码得到256维的特征
其次,256×256的图像经过VQ-VAE(将训练好的VQ-VAE的codebook直接拿来用),得到32×32的图片特征
We train a discrete variational autoencoder (dVAE) to compress each 256×256 RGB image into a 32 × 32 grid of image tokens -
Stage2:Learning the Prior
重构原图
将拉直为1024维的tokens,然后连上256维的文本特征,这样就得到了1280维的token序列,然后直接送入GPT(masked decoder)重构原图
推理时,输入文本经过编码得到文本特征,再将文本通过GPT利用自回归的方式生成图片,生成的多张图片会通过CLIP模型和输入的文本进行相似度计算,然后调出最相似(描述最贴切)的图像
2.2 DALLE 2:Hierarchical Text-Conditional Image Generation with CLIP Latents
对于DALL·E2而言,基本就是整合了CLIP和基于扩散模型的GLIDE,而后者则采用了两阶段的训练方式:文本 → 文本特征 → 图片特征 → 图片

-
CLIP训练过程:学习文字与图片的对应关系
如上图所示,CLIP的输入是一对对配对好的的图片-文本对(根据对应文本一条狗,去匹配一条狗的图片),这些文本和图片分别通过Text Encoder和Image Encoder输出对应的特征,然后在这些输出的文字特征和图片特征上进行对比学习 -
DALL·E2:prior + decoder
上面的CLIP训练好之后,就将其冻住了,不再参与任何训练和微调,DALL·E2训练时,输入也是文本-图像对,下面就是DALL·E2的两阶段训练:
阶段一 prior的训练:根据文本特征(即CLIP text encoder编码后得到的文本特征),预测图像特征(CLIP image encoder编码后得到的图片特征)
换言之,prior模型的输入就是上面CLIP编码的文本特征,然后利用文本特征预测图片特征(说明白点,即图中右侧下半部分预测的图片特征的ground truth,就是图中右侧上半部分经过CLIP编码的图片特征),就完成了prior的训练
推理时,文本还是通过CLIP text encoder得到文本特征,然后根据训练好的prior得到类似CLIP生成的图片特征,此时图片特征应该训练的非常好,不仅可以用来生成图像,而且和文本联系的非常紧(包含丰富的语义信息)
阶段二 decoder生成图:常规的扩散模型解码器,解码生成图像
这里的decoder就是升级版的GLIDE(GLIDE基于扩散模型),所以说DALL·E2 = CLIP + GLIDE
2.3 DALLE 3:Improving Image Generation with Better Captions
我司LLM项目团队于23年11月份在给一些B端客户做文生图的应用时,对比了各种同类工具,发现DALLE 3确实强,加之也要在论文100课上讲DALLE三代的三篇论文,故接下来,咱们结合DALLE 3和相关paper好好看下DALLE 3的训练细节
2.3.1 为提高文本图像配对数据集的质量:基于谷歌的CoCa微调出图像字幕生成器
目前文生图模型的一个很大的问题是模型的文本理解能力,这个文本理解能力指的是生成的图像是否能和文本保持一致,也就是论文里面所说的prompt following能力
如论文中所说
-
论文提出来字幕改进(caption improvement)的方法
毕竟现在text-to-image模型现存的一个基本问题便是:这些模型训练所用的文本-图像配对数据的质量较差
We hypothesize that a fundamental issue with existing text-to-image models is the poor quality of the text and image pairing of the datasets they were trained on -
故论文提出可以通过改进「文本-图像配对数据集中的针对图像的文本描述的质量」来解决这个问题(We propose to address this by generating improved captions for the images in our dataset)
为实现这个目标,首先训练一个强大的图像字幕生成器(image captioner),以生成详细、准确的图像描述,然后我们便可以把这个图像字幕生成器应用到已有的文本-图像配对数据集中,以为各个图像生成更详细、准确的图像描述或字幕,最后在改进的数据集上训练text-to-image模型
We do this by first learning a robust image captioner which produces detailed, accurate descriptions of images. We then apply this captioner to our dataset to produce more detailed captions. We finally train text-to-image models on our improved dataset.
总之,对于稍微复杂的文本,目前的文生图模型生成的图像往往会容易忽略部分文本描述,甚至无法生成文本所描述的图像。这个问题主要还是由于训练数据集本身所造成的,更具体的是说是图像caption不够准确
- 一方面,图像常规的文本描述往往过于简单(比如COCO数据集),它们大部分只描述图像中的主体而忽略图像中其它的很多信息,比如背景,物体的位置和数量,图像中的文字等
- 另外一方面,目前训练文生图的图像文本对数据集(比如LAION数据集)都是从网页上爬取的,图像的文本描述其实就是alt-text,但是这种文本描述很多是一些不太相关的东西,比如广告。训练数据的caption不行,训练的模型也就自然而然无法充分学习到文本和图像的对应关系,那么prompt following能力必然存在问题
2.3.1.1 什么是谷歌的CoCa
OpenAI最终基于谷歌的CoCa来训练这个image captioner来合成图像的caption,CoCa构建在encoder-decoder的基础上,其中Image Encoder和Text Decoder均采用Transformer模型,其中Image Encoder的参数量为1B,而Text Decoder的参数量达到1.1B,这样整个CoCa模型的参数量为2.1B(对于图像,其输入大小为288×288,而patch size为18x18,这样总共有256个image tokens。同时,这里也设计了两个更小模型:CoCa-Base和CoCa-Large)

不过这里将text decoder均分成两个部分:一个单模态解码器unimodal text decoder和一个多模态解码器multimodal text decoder,然后增加一个cls token在文本的最后(CoCa相比CLIP额外增加了一个Multimodel Text Encoder来生成caption,如此,它训练的损失包含了CLIP的对比损失和captioing的交叉熵损失,所以CoCa不仅可以像CLIP那样进行多模态检索,也可以用于caption生成)
具体而言,如下图的左半部分所示

- unimodal text decoder不参与对图像特征的cross-attention(We omit cross-attention in unimodal decoder layers to encode text-only representations,相当于把 Transformer Decoder 中的cross attention去掉,只保留 masked self-attention 和 FFNN)
这样cls token经过unimodal text decoder之后就能够得到整个句子的全局特征
同时采用attention pooling对image encoder得到特征提取图像的全局特征(这里的attention pooling其实就是一个multi-head attention,只不过key和value是image encoder得到的特征,而query是预先定义的一个可训练的embedding,由于我们只需要提取一个全局特征,所以只需要定义一个query就好了)
两个全局特征就可以实现图像-文本的对比学习「相当于image encoder和unimodal text decoder的两个[CLS]向量作为图片和文本的表示,进行batch 内对比学习,同 CLIP」 - multimodal text decoder将用来执行生成任务,这里也通过一个attention pooling对image encoder得到的特征进行提取,不过这里query数量定义为256,这样attention pooling可以得到256个特征,它作为multimodal text decoder的cross-attention的输入(cascademultimodal decoder layers cross-attending to image encoder outputs to learn multimodal image-textrepresentations)
相当于就是正常的Transformer Decoder,包含masked self-attention、cross-attention、FFNN,用于融合图片和文本信息,实现双模态,最后做文本生成 - 所以,CoCa将同时执行对比学习和文本生成任务,它的训练损失也包括两个部分:
顺带说一句,这个CoCa和如下图所示的ALBEF(这是其论文)还挺像的,所以有人评论它两的关系就像BERT和RoBERTa(可以简单理解为是对BERT的精调)
- 但CoCa 与 ALBEF 最大的不同在于:CoCa 右侧处理文本和进行多模态融合的网络是一个 decoder,而非ALBEF那里是 encoder
- 再说一句,其实下图的下半部分不就是类似一个CLIP么?^_^

2.1.1.2 分别通过短caption、长caption微调预训练好的image captioner
为了提升模型生成caption的质量,OpenAI对预训练好的image captioner进行了进一步微调,这个微调包括两个不同的方案,两个方案构建的微调数据集不同
- 第一个方案的微调数据集是只描述图像主体的短caption(类似COCO风格的caption)
- 而第二个方案的微调数据集是详细描述图像内容的长caption
相应地,两个微调模型分别可以生成:短caption(short synthetic captions,简称SSC)、长caption(descriptive synthetic captions,简称DSC)
下图展示了三个样例图像各自的原始caption(ground-truth),以及生成的短caption、长caption

- 每个样例图像的原始caption是从网页上得到的alt-text,其质量较差
- 每个样例图像的合成的短caption简洁地描述了图像的主体内容
- 每个样例图像的合成的长caption详细描述了图像的很多内容,细节比较丰富
2.1.1.3 为提高合成caption对文生图模型的性能:采用描述详细的长caption,训练的混合比例高达95%
接下来要解决两个问题
- 通过实验来分析合成caption对文生图模型性能的影响
- 另外一点是探讨训练过程中合成caption和原始caption的最佳混合比例
这里之所以要混合合成caption和原始caption(opted to blend synthetic captions with ground truth captions),主要是为了防止模型过拟合到合成caption的某些范式
比如最常见的例子是合成的caption往往以"a"和"an"开头,解决这个问题最好的方法便是:通过接近the style and formatting that humans might use,以regularize our inputs to a distribution of text
所以,我们在训练过程中,在合成caption中混入原始caption(human-written text),相当于一种模型正则化
首先是合成caption对模型性能的影响,这里共训练了三个模型,它们的差异是采用不同类型的caption,分别是
- 只用原始caption
- 5%的原始caption + 95%的合成短caption
- 5%的原始caption + 95%的合成长caption
通过上一节对DALLE 2的分析,我们得知最后的文生图decoder模型是基于扩散模型的
而DALLE 3的论文中训练的文生图是latent diffusion模型
- 其VAE和SD一样都是8x下采样
- 而text encoder采用T5-XXL,之所以用T5-XXL,可能主要有两个原因,一方面T5-XXL可以编码更长的文本,另外一方面是T5-XXL的文本编码能力也更强
- 这里训练的图像尺寸为256x256(这只是实验,所以低分辨率训练就足够了),采用batch size为2048共训练50W步,这相当于采样了1B样本
论文中并没有说明UNet模型的具体架构,只是说它包含3个stages,应该和SDXL类似(SDXL包含3个stage,只下采样了2次,第一个stage是纯卷积,而后面两个stages包含attention)
这里只是想验证模型的prompt following能力,所以采用了CLIP score来评价模型,这里的CLIP score是基于以下两者的相似度,即
- CLIP ViT-B/32来计算生成图像的image embedding即
- 和text prompt对应的text embedding即的余弦相似度(这里是生成了50000个图像并取平均值,并乘以100)
下图展示了采用三种caption训练的模型在CLIP score上的差异:

- 左图在计算CLIP score时,text采用原始caption(ground truth caption),从整体上来看,无论是采用合成的长caption还是短caption,其CLIP score比只采用原始caption要好一点,但是波动比较大
- 右图计算CLIP score时,text采用合成的长caption,这里就可以明显看到:合成长caption > 合成短caption > 原始caption,而且CLIP score要比左图要高很多
这说明采用长caption来计算CLIP score是比较合理的,因为图像的image embedding信息很大,而短文本信息少,所以两者的相似度就会低一些,而且还可能存在一定的波动
总之,从上面的实验来看,采用合成的长caption对模型的prompt following能力是有比较大的提升的。
接下来的问题就是通过实验来找到最佳的数据混合比例。所以又增加了混合比例为65%、80%、90%的实验,下图展示了不同混合比例训练出来的模型其CLIP score的差异,可以看到采用95%的合成caption训练的模型在效果上要明显高于采用更低比例的caption训练的模型。

所以最终的结论是采用合成的caption对模型提升帮助比较大,而且要采用描述详细的长caption,训练的混合比例高达95%,这也是后面DALL-E 3的数据训练策略。
不过采用95%的合成长caption来训练,得到的模型也会“过拟合”到长caption上,如果采用常规的短caption来生成图像,效果可能就会变差
为了解决这个问题,OpenAI采用GPT-4来“upsample”用户的caption,下面展示了如何用GPT-4来进行这个优化,不论用户输入什么样的caption,经过GPT-4优化后就得到了长caption:

下图展示了三个具体的例子,可以看到使用优化后的长caption(图中第二排)其生成图像效果要优于原来的短caption(图中第一排):

所以,DALL-E 3接入ChatGPT其实是不得已而为之的事情,因为这样才能保证DALL-E 3的输入不偏离训练的分布
2.3.2 训练细节总结:原始caption和合成长caption混合训练 + T5 + latent decoder
DALLE 3的论文提到,DALL-E 3的具体实现有两个关键点:
- 首先,DALL-E 3也采用95%的合成长caption和5%的原始caption混合训练,这也应该是DALL-E 3性能提升的关键
- 另外,DALL-E 3的模型是上述实验中所采用的模型的一个更大版本(基于T5-XXL的latent diffusion模型),同时加上其它的改进(但论文中并没有说是具体的哪些改进,只说DALL-E 3也不应简单地归功于在合成caption的数据集上训练,所以DALL-E 3的其它改进应该也会比较重要)
目前DALL-E 3生成的图像的分辨率都是在1024x1024以上,所以DALL-E 3的模型应该类似于SDXL,采用递进式的训练策略(256 -> 512 -> 1024),而且最后也是采用了多尺度训练策略来使模型能够输出各种长宽比的图像
另外如小小将所说,附录里面给出了一个细节是
- DALL-E 3额外训练了一个latent decoder来提升图像的细节,特别是文字和人脸方面,这个应该是为了解决VAE所产生的图像畸变。这里采用的扩散模型是基于DDPM中的架构,所以是pixel diffusion
从直观上来看,这个latent decoder就是替换原始的VAE decoder,因此这个扩散模型的condition是VAE的latent
但是具体是怎么嵌入到扩散模型的UNet中,这里没有说明,最简单的方式应该是通过上采样或者一个可学习的网络将latent转变为和噪音图像一样的维度,然后与噪音图像拼接在一起- 同时为了加速,基于Consistency Models中提出的蒸馏策略将去噪步数降低为2步,所以推理是相当高效的
This diffusion decoder is a convolutional U-Net identical to the one described in Ho et al. (2020). Once trained, we used the consistency distillation process described in Song et al. (2023) to bring it down to two denoising steps

2.3.3 DALL-E 3的评测结果
对于DALL-E 3的评测,论文是选取了DALL-E 2和SDXL(加上refiner模块)来进行对比。模型评测包括自动评测和人工评测。
2.3.3.1 针对DALLE 3的自动评测
自动评测主要有3个指标
- 首先是计算CLIP score,评测数据集是从COCO 2014数据集中选择4096个captions
这里的评测数据集是Imagen中所提出的DrawBench评测集(共包括200个包含不同类型的prompts) - 然后是采用GPT-4V来进行评测
这里的评测是将生成的图像和对应的text输入到GPT-4V,然后让模型判断生成的图像是否和text一致,如果一致就输出正确,否则就输出不正确 - 最后是采用T2I-CompBench来评测
这个评测集包含6000个组合类型的text prompts,它包括多个方面,这里只选择color binding、shape binding和texture binding三个方面进行评测,评测是通过BLIP-VQA model来得到评分
下表给出了DALL-E 3与其它模型的对比结果,可以看到DALL-E 3还是明显优于DALL-E 2和SDXL。不过自动评测所选择的三个指标都是评测模型的prompt following能力,并不涉及到图像质量

2.3.3.2 针对DALLE 3的人工评测
人工评测主要包括三个方面
- 第一个是prompt following,给出两张不同的模型生成的图像,让人来选择哪个图像和文本更一致
- 第二个是style,这里不给文本,只给两张图像,让人选择更喜欢的那个图像
- 第三个是coherence,这里也不给文本,让人从两张图像中选择包含更多真实物体的图像
可以看到后面的两个方面其实就是评测模型生成图像的质量,对于prompt following和style,这里使用的评测集是DALL-E 3 Eval,它共包含170个captions,是从用户应用场景收集得到的。而coherence方面的评测集是从COCO数据集抽样的250个captions,因为coherence是评测真实性,所以采用更偏真实场景的COCO数据集
另外,之前DrawBench评测集是采用GPT-4V来自动评测的,但是GPT-4V也会犯错,比如在计数方面,所以这里也额外增加了DrawBench评测集的人工评测。
所有人工评测的对比结果如表所示,可以看到DALL-E 3具有明显优势:

这里的ELO score是GLIDE中所提出的来计算胜率的指标:

尽管DALL-E 3在prompt following方面有很大的提升,但是它依然有一定的局限性
- 首先是模型在空间位置关系上还是会比较容易出错,当prompt包含一些位置关系描述如"to the left of",模型生成的图像并不一定会符合这样的位置关系,这主要是因为合成的caption在这方面也并不可靠
- 另外就是文字生成能力,虽然DALL-E 3在生成文字方面很强,但是还是会出现多词或者少词的情况,一个可能的原因T5-XXL的tokenizer并不是字符级的
- 还有一个比较大的问题是合成的caption会幻想图像中的重要细节,比如给一幅植物的绘图,image captioner可能会虚构出一个植物并体现在合成的caption上。这就意味着模型可能会学到错误的绑定关系,也导致模型在生成特定种类的东西并不可靠
- 最后一点是模型的安全性和偏见,这个是所有大模型所面临的问题,也是由于训练集所导致的,对于这点,DALL·E 3 system card有更多的评测
// 待更文章来源地址https://www.toymoban.com/news/detail-837150.html
第三部分 通俗理解stable diffusion:文本到图像的潜在扩散模型(改进版DDPM)
3.1 SD与DDPM的对比
我们在上篇博客《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/MAE/Swin transformer》中,已经详细介绍了扩散模型DDPM,为方便对后续内容的理解,特再回顾下DDPM相关的内容(至于详细的请看上篇博客):
前向过程加噪
逆向过程去噪,由于反向扩散过程不可直接计算,因此训练神经网络来近似它,训练目标(损失函数)如下
所以,DDPM的关键是训练噪声估计模型,使其预测的噪声 与真实用于破坏的噪声 相近,具体怎么个训练过程呢?
- 比如可以选择选择一个训练图像,例如海边沙滩的照片,然后生成随机噪声图像,通过将此噪声图像添加到一定数量的步骤来损坏训练图像
- 然后通过一个噪声估计器U-Net 预测添加的噪声,使其与实际噪声做差异对比,从而建立损失函数做反向传播,最后更新噪声估计器的参数
说白了,就是通过告诉U-Net 我们在每一步添加了多少噪声,从而手把手一步步教U-Net 怎么去估计噪声
- U-Net训练好了之后(意味着其对噪声的估计比较准确了),我们便可以基于训练好的 U-Net 来生成图像
原理很简单,通过噪声估计器预测出噪声后,不模糊的图片便减去每一步添加的噪声以清晰化 不就ok了么
而如果用一句话介绍stable diffusion,可以理解为:改进版的DDPM,Stable Diffusion原来的名字叫“Latent Diffusion Model”(LDM),很明显就是扩散过程发生隐空间中(即latent space,下文或其他地方也有说潜在空间或压缩空间之类的,都一个意思),其实就是对图片做了压缩

不过,为何要弄这么个隐空间或潜在空间呢?
原因很简单,为了使扩散模型在有限的计算资源上训练,并且保留它们的质量和灵活性,故首先训练了一个强大的预训练自编码器,这个自编码器所学习到的是一个潜在的空间,这个潜在的空间要比像素空间要小的多,把扩散模型在这个潜在的空间去训练,大大的降低了对算力的要求,这也是Stable Diffusion比原装Diffusion速度快的原因
总之,Stable Diffusion会先训练一个自编码器,来学习将图像压缩成低维表示
- 通过训练好的编码器,可以将原始大小的图像压缩成低维的latent data(图像压缩)
- 通过训练好的解码器,可以将latent data还原为原始大小的图像
在将图像压缩成latent data后,便可以在latent space中完成扩散过程,对比下和Diffusion扩散过程的区别,如下图所示:

可以看到Diffusion扩散模型就是在原图 上进行的操作,而Stale Diffusion是在压缩后的图像 上进行操作
3.2 理解stable diffusion的三层境界
3.2.1 第一层境界:不看公式只看意图整体理解SD
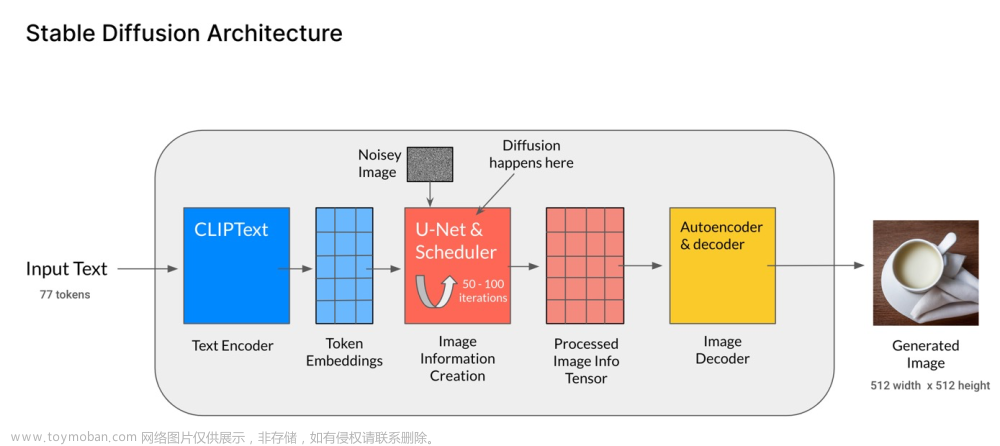
SD的整体框架流程图
stable diffusion和上面DALL E2的原理其实差不多,具体而言,会先后经历以下几个步骤「左边红色是像素空间 pixel space(含编码器和解码器)、中间绿色区域是潜在空间latent space、右边灰色的是条件condition」

-
将图像从像素空间(Pixel Space)压缩到潜在空间(Latent Space)
具体而言,图像编码器将图像从515✖️512的像素空间,压缩到更小维度4✖️64✖️64的潜在空间 -
针对潜在空间的图片做扩散(Diffusion Process):添加噪声
对潜在空间Latent Space中的图片添加噪声,进行扩散过程 -
根据用户的输入text/prompt 获取去噪条件(Conditioning)
通过 CLIP的文本编码器 将输入的描述语(text/prompt)转换为去噪过程的条件 -
噪声估计器U-Net 预测噪声,然后依据「去噪条件」去噪:生成图片的潜在表示
首先,噪声估计器 U-Net 将潜在噪声图像和文本提示作为输入,并预测噪声「该过程也在潜在空间(4x64x64 张量)中」
之后,基于上面第3步的条件对图像通过 噪声估计器U-NET 进行去噪(Denoising),以获得生成图片的潜在表示
当然了,去噪步骤可以灵活地以文本、图像和其他形式为条件,比如以文本为条件即text2img、以图像为条件即 img2img -
潜在空间转换成最终图像
图像解码器通过将图像从潜在空间转换回像素空间来生成最终图
问题1:怎么理解潜在空间
如何理解 “潜在空间” 呢?
- 大家都有自己的身份证号码,前 6 位代表地区、中间 8 位代表生日、后 4 位代表个人其他信息。放到空间上如图所示,这个空间就是「人类潜在空间」
这个空间上相近的人,可能就是生日、地区接近的人。人可以对应为这个空间的一个点,这个空间的一个点也对应一个人。如果在空间中我的附近找一个点,对应的人可能跟我非常相似,没准就是我失散多年的兄弟
- AI 就是通过学习找到了一个「图片潜在空间」,每张图片都可以对应到其中一个点,相近的两个点可能就是内容、风格相似的图片

问题2:CLIP的应用举例
如果让你把左侧三张图和右侧三句话配对,你可以轻松完成这个连线。但对 AI 来说,图片就是一系列像素点,文本就是一串字符,要完成这个工作可不简单。

原因在于
- 这需要 AI 在海量「文本-图片」数据上学习图片和文本的匹配。图中绿色方块是「图片潜在空间」的 N 张图片,紫色方块是「文本潜在空间」的 N 句描述语
CLIP会努力将对应的 I1与T1(蓝色方块)匹配,而不是 I2与T3(灰色方块)匹配
- 当 AI 能成功完成这个连线,也就意味着 AI 建立了「文字潜在空间」到「图片潜在空间」的对应关系,这样才能通过文字控制图片的去噪过程,实现通过文字描述得到图像的生成

3.2.2 第二层境界:依托公式深入模型结构
SD的模型结构:autoencoder + CLIP text encoder + UNet
还是看这个图
-
上图最左侧:编码输入/解码输出
编码器encoder 可以对图像进行压缩,可以理解为它能忽略图片中的高频信息,只保留重要的深层特征,将其压缩到一个 latent space「维度为(4, 64, 64)」,然后我们可以在这个 latent space 中进行 Diffusion Process,将其结果作为 U-Net 的输入
解码器decoder 负责将去噪后的 latent 图像恢复到原始像素空间「各维度为:(3,512,512),即(红/绿/蓝, 宽, 高)」
这个就是所谓的感知压缩(Perceptual Compression),即“将高维特征压缩到低维,接着在低维空间上进行操作”的方法具有普适性,可以很容易的推广到文本、音频、视频等不同模态的数据上 -
上图最右侧:用户的输入text或prompt
通过CLIP的text encoder提取输入text的text embeddings(维度为77✖️768,意味着77个token嵌入向量,其中每个向量包含768个维度)
然后通过cross attention方式送入噪声估计模型UNet中作为去噪条件condition
a ) 事实上,扩散模型可以理解为一个时序去噪自编码器,我们需要训练使得预测的噪声与真实噪声相近,则目标函数为:
b ) 而在 Latent Diffusion Models 中,引入了预训练的感知压缩模型,它包含一个编码器和一个解码器,这样就可以在训练时利用 得到 latent representation ,从而让模型在潜在表示空间中学习,其目标函数为:
c ) 对于条件生成任务,我们将拓展为:,这样就可以通过来控制图片合成的过程,通过在 UNet 上增加 cross-attention 机制来实现
而为了能够从不同的模态预处理,论文引入了一个领域专用编码器,它用来将映射成一个中间表示,这样我们就可以很方便的引入各种形式的条件,例如文本、类别、layout等
d ) 最终模型可通过一个 cross-attention 将去噪条件引导融入到 UNet 中,cross-attention 表示为:
其中是 UNet 的一个中间表征
最终,目标函数可以写为:
-
上图中底部:基于噪声估计模型U-Net实现文本条件引导下的latent生成
加噪后的隐式表达和文本语义表征通过Attention的方式输入到U-Net,用以更好的学习文本和图像的匹配关系,这里文本的语义向量就是条件(用户的输入text或prompt),控制图像生成往我们想要的方向发展,通过U-Net来预测每一步要减少的噪声
然后计算网络输出噪声和真实噪声的差距,最小化损失来反向传播更新参数,注意整个训练阶段VAE是冻结的
下图亦可辅助理解

3.2.3 第三层境界:从源码层面理解SD

// 待更
3.3 七月AIGC模特生成平台:基于SD的微调与二次开发
3.3.1 如何快速微调SD
目前Stable Diffusion 模型微调主要有4 种方式:
- Dreambooth
- LoRA(Low-Rank Adaptation of Large Language Models)
- Textual Inversion
- Hypernetworks
//待更文章来源:https://www.toymoban.com/news/detail-837150.html
3.4 SDXL Turbo
// 待更
3.5 LCM
参考文献与推荐阅读
-
Learning Transferable Visual Models From Natural Language Supervision
CLIP原始论文 - CLIP 论文逐段精读,这是针对该视频解读的笔记之一:CLIP和改进工作串讲
-
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP原始论文 -
多模态超详细解读 (六):BLIP:统一理解和生成的自举多模态模型
极智AI | 多模态新姿势 详解 BLIP 算法实现 - 理解DALL·E 2, Stable Diffusion和 Midjourney工作原理
- 读完 DALL-E 论文,我们发现大型数据集也有平替版
-
Hierarchical Text-Conditional Image Generation with CLIP Latents
DALL E2原始论文 - DALL·E 2(内含扩散模型介绍),这是针对该视频解读的笔记
- DALL-E 3技术报告阅读笔记
- OpenAI一夜颠覆AI绘画!DALL·E 3+ChatGPT强强联合,画面直接细节爆炸
- CoCa:对比+生成式任务构建“全能型多模态模型”,这是其论文地址
- 关于CoCa的另外几篇文章:CoCa: 在图生文过程中加入对比学习、如何评价谷歌的 CoCa,在 ImageNet 上达到新的 SOTA:91.0%?
- 浅析多模态大模型的前世今生
- The Illustrated Stable Diffusion,这是图解SD的翻译版
-
Stable Diffusion Clearly Explained!
How does Stable Diffusion paint an AI artwork? Understanding the tech behind the rise of AI-generated art. - Getting Started With Stable Diffusion
- High-Resolution Image Synthesis with Latent Diffusion Models
- 知乎上关于SD原理的几篇文章:Stable Diffusion 的技术原理是什么?、人工智能Ai画画——stable diffusion 原理和使用方法详解、十分钟读懂Stable Diffusion
- Memory-efficient array redistribution through portable collective communication
- stable diffusion 原理介绍 - AI绘画每日一帖
- How does Stable Diffusion work?
- Stable Diffusion 原理介绍与源码分析(一)
- 保姆级讲解 Stable Diffusion
- 李宏毅生成式AI模型diffusion model/stable diffusion概念讲解
- 速度惊人!手机跑Stable Diffusion,12秒出图,谷歌加速扩散模型破记录
- SDXL Turbo、LCM相继发布,AI画图进入实时生成时代:字打多快,出图就有多快
- 文生图10倍速,视频实时渲染!清华发布LCM:兼容全部SD大模型、LoRA、插件等
- 七月在线:AIGC下SD/MDJ的原理与实战课 [深度探究AI绘画/多模态]
首发之后的创作、修改、新增记录
- 端午假期三天,持续完善BLIP/BLIP2、DALLE/DALLE 2等相关的内容
- 6.25,开始写SD的原理部分
- 6.26,考虑到公式太多 容易把初学者绕晕,故把理解SD划分为三层境界
第一层境界 不涉及任何公式,从意图层面整体理解SD
且初步写清SD的基本逻辑
顺带感叹,这几天在网上反复看了大量关于stable diffusion原理的解读文章
我站在初学者角度上,没有一篇令我满意
我也不知道怎么回事,把文章写通俗没有那么难啊.. - 6.27,修改SD的原理部分,以让逻辑清晰明确
- 6.28,写清楚DALL·E2的模型架构
- 6.29,写DALL·E的部分,并梳理全文逻辑
断断续续两个月,总算通过本文和上一篇文章把SD相关的基本写清楚了,后续就是不断优化所有行文细节
以让逻辑更清晰 细节更明确,初学最爱看
感叹过程中 被各种资料反复绕晕过,好在 终究还是像之前解读各种稍复杂点的模型一样
一如既往的绕出来了 - 7.7,优化对潜在空间的说明描述
- 7.16,润色关于噪声估计器的部分描述
- 10.30,开始新增DALLE 3的部分
前几天写完了旋转位置编码,未来几天都在持续写DALLE 3的技术细节
一方面,它生成图的质量确实挺高
二方面,近期需要为某合作伙伴做一个文生图的应用,所以研究下各个相关模型的技术细节 - 10.31,优化SD的部分
- 11.10,重读DALLE 3论文并优化相关细节的描述
如在微博上所说的,“为准备这周日的DALLE 3公开课,在一字一句重抠DALLE 3论文,但其本质不算论文,很多训练细节没透露
好在现在完全可以一字一句耐心读paper了,一年前还是有点痛苦的,加之研究能力的不断提升,可以通过研究相关paper去补齐它的训练细节” - 11.12,优化第二部分中关于DALLE、DALLE 2的部分内容,以为阐述更精准
比如关于DALLE 2的训练步骤 - 11.13,继续优化第二部分中关于DALLE 3部分内容的描述细节
- 11.23,因11.25要在fanbook上做SD的专场公开课,故优化本文关于SD的部分内容
- 24年1.5,因本文一读者于评论中留言提醒:DALL·E3在计算余弦相似度的时候,直接根据公式计算就行了,没必要再用1去减
一看,确实如此,特此修正,感谢该朋友的指出
到了这里,关于AI绘画原理解析:从CLIP到DALLE1/2、DALLE 3、Stable Diffusion、SDXL Turbo、LCM的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!