前言
Stable Diffusion(稳定扩散)是一种生成模型,基于扩散过程来生成高质量的图像。它通过一个渐进过程,从一个简单的噪声开始,逐步转变成目标图像,生成高保真度的图像。这个模型的基础版本是基于扩散过程的,但也有一些改进版本,包括基于变分自动编码器(VAE)、局部正则化的自动编码器(LORA)和嵌入式扩散等。
感兴趣可加入:566929147 企鹅群一起学习讨论
1.基础模型
Stable Diffusion Checkpoint模型是生成图像所必须的基础模型,也称之为大模型。要使用Stable Diffusion出图之前必须配备一个主模型才能开始创作。这个主模型包含了生成图像所需的所有信息,无需额外的文件或组件。这些主模型的文件通常比较大,大小在2GB到7GB之间。它们的文件后缀通常是“ckpt”或“safetensors”。
不同的主模型具有不同的特点,它们在创作风格和擅长的领域上有所侧重。因此,在选择主模型时,需要考虑自己的创作需求和偏好。不同的主模型可以帮助你实现不同风格的图像生成。
一些流行和常见的Checkpoint模型包括“Anything”系列(如v3、v4.5、v5.0)、“AbyssOrangeMix3”、“ChilloutMix”、“Deliberate”,以及“国风系列”等等。这些Checkpoint模型都是从Stable Diffusion的基础模型训练而来,它们使用不同的数据进行训练,以生成特定风格或对象的图像。
需要注意的是,通常情况下是不会使用官方自带的大模型来进行创作出图的,因为它们的效果较差。但是如果想要自己练大模型,官方自带的大模型系列是一个不错的基础模型,因为它们涵盖了各种风格,属于中性模型。
当在下载模型时,可能会看到带有pruned、emaonly(ema)等后缀,pruned表示完整版,而emaonly表示剪枝版。(模型剪枝是一种通过删除神经网络中的冗余连接或参数来减小模型大小。可以帮助减少模型的存储空间和计算成本,同时在某些情况下还可以提高模型的推理速度。需要注意的是,尽管剪枝版模型在大小上更为轻量级,但在一些情况下可能会牺牲一定的性能。因此,在选择模型时,需要权衡模型大小和性能之间的关系,根据具体的应用场景和需求来做出选择。)但两者在使用上差别不大。如果想要自己练模型,则需要下载完整版。需要注意的是,有些剪枝版可能不带有后缀,有些可能后缀也是prune,因此在具体选择时需要参考相应的版本说明。
Civitai是一个全球性的提供AI艺术资源分享和发现的平台,旨在帮助用户轻松探索并使用各类AI艺术模型。平台用户可以上传和分享自己用数据训练的AI自定义模型,或者浏览和下载其他用户创建的模型。
以我这里使用的秋叶sd-webui-aki-v4.5整合包为例,模型下载之后,放到models/Stable-Diffusion目录。
之后刷新就可以看到相关的模型:
选择要使用的模型之后,可以输入正向提示词和反向提示,然后点生成:

2、外挂VAE模型
VAE模型可以被视作一种类似于颜色滤镜的工具,用于调整和改善生成图片的色彩。它并非在制图时必不可少,而是根据个人绘画需求决定是否采用。在使用某些模型时,有时绘制的图片整体颜色可能会显得较灰暗。在这种情况下,可以使用VAE模型对图片的颜色进行调整,以改善整体视觉效果。
下载或者自己训练出来的VAE模型把它放到models/VAE目录下:
测试VAE模型,左边是没有使用VAE模型的,右边是使用了VAE模型:
在绘图过程中,选择是否使用VAE模型通常对最终生成的图片效果并没有太大的影响。相比之下,VAE模型并不像其他模型(比如LORA模型)那样在绘图中的作用和效果十分明显。在测试中尝试了几个常用的大型模型,发现使用或不使用VAE模型对最终生成的图片效果的区别并不明显。
3、Lora模型
LoRA(Low-Rank Adaptation)是一种大语言模型低秩适配器,最早在2021年的论文《LoRA: Low-Rank Adaptation of Large Language Models》中提出。它的核心思想是通过降低模型可训练参数的数量,尽量不损失模型的性能,从而实现对大语言模型的微调。
在此之前,对于Stable Diffusion这样的模型,要训练大模型的话,通常需要使用Dreambooth等方法。如果对大模型的效果不满意,那么就只能从头开始重新训练,但是这个过程需要高要求的算力,且速度较慢。LoRA的引入极大地降低了训练的门槛,扩大了产出模型的适用范围。这意味着即使是非专业人员也可以在家用电脑上尝试训练自己的LoRA模型,从而更灵活地适应不同的任务和需求。
这里可以将大型模型比作素颜的人,因为它们通常生成的图片与原始数据相似,但可能缺乏一些细节或特定的特征。而LoRA模型则像是进行了化妆、整容或cosplay,它们能够通过增加细节、调整风格或改变外观,使生成的图片更加精美或符合特定的要求。LoRA模型不仅局限于人物,也适用于场景、动漫或其他风格,这使得它们在生成多样化的内容时具有广泛的应用性。大型模型提供了基础,而LoRA模型在此基础上进一步增强和丰富了生成的图片效果。
LoRA模型具有几个明显的优点:
-
性能优势: 使用LoRA时,只需要存储少量被微调过的参数,而不需要保存整个新模型。这使得LoRA模型的存储开销较小。此外,LoRA的新参数可以与原模型的参数合并,不会增加模型的运算时间。
-
功能丰富: LoRA模型维护了模型在微调中的“变化量”,通过用介于0到1之间的混合比例乘以这些变化量,可以控制模型的修改程度。此外,基于同一个原模型独立训练的多个LoRA模型可以同时使用。
这些优点在SD LoRA(中得到体现:
-
模型尺寸小: SD LoRA模型通常都很小,只有几十MB大小,这使得它们在存储和部署时都非常高效。
-
参数合并: SD LoRA模型的参数可以合并到SD基础模型中,得到一个新的SD模型,这有助于简化模型管理和部署过程。
-
画风控制: 可以使用0到1之间的比例来控制SD LoRA新画风的程度,使得用户可以根据需要调整生成图片的风格和效果。
-
多画风混合: 可以将不同画风的SD LoRA模型以不同的比例混合,从而进一步增加生成图片的多样性和可控性。
C站也有开源可用的Lora模型下载,下载之后,把模型放到models/Lora里面,重启或者刷新webui界面:
可以查看Lora的模型:
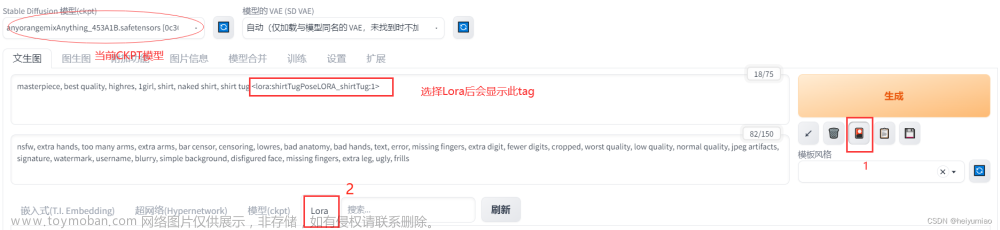
在WebUI中,点击所需的模型之后,系统会自动在提示词中增加对该模型及其权重的引用。格式如下:
<lora:模型的名字:模型的权重>
这样就可以在提示词中引用所选模型以及其权重了。模型的权重越高生成图片时越贴近模型提供的主体或者风格,权重的取值范围是:0-1。生成图片时可以同时使用多个LoRA模型,最终效果会综合多个模型的风格。
4.Embedding模型
Embedding可以被理解为一组提示词的集合,将这些提示词汇总到一个文件中。当需要使用这些提示词时,只需调用这个Embedding文件,就相当于输入了很多的提示词,这对用户来说非常方便。
Embedding可以用于正向提示词,也可以用于负向提示词。但在大多数情况下,它通常用于负向提示词,因为负向提示词的数量通常很多,而且复用性较高。例如,在人物绘图时,对于描述手指可能会使用诸如“坏的手指”、“多余的手指”、“缺失的手指”等多个负向提示词,同样的情况也适用于其他身体部位如腿、手等。这导致在绘图时需要频繁输入这么多的负向提示词,因此有时候负向提示词的数量远远超过正向提示词。
为了方便用户操作,减轻用户编写提示词的麻烦,常用的负向提示词会被打包在一起。这样用户只需要使用一个关键词,就可以代替输入很多的负向提示词,达到一词顶百词的效果。
由于Embedding模型是一组提示词的集合,所以Embedding模型文件通常不大,大小一般在几十KB到几百KB之间。
在C站上面,在搜索条件中通过Embedding关键字过滤出所有的Embedding模型。文章来源:https://www.toymoban.com/news/detail-837171.html

 文章来源地址https://www.toymoban.com/news/detail-837171.html
文章来源地址https://www.toymoban.com/news/detail-837171.html
到了这里,关于Stable Diffusion——基础模型、VAE、LORA、Embedding各个模型的介绍与使用方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!