需求背景
最近有一个需求需要建设一个知识库文档检索系统,这些知识库物料附件的文档居多,有较多文档格式如:PDF, Open Office, MS Office等,需要将这些格式的文件转化成文本格式,写入elasticsearch 的全文检索索引,方便搜索。 我这里介绍一种工具不考虑文件原来格式,但能方便将转化的文档写入到对应的es 索引,并且支持OCR识别扫描版本的pdf文档。
FSCrawler介绍
使用官方文档
github:https://github.com/dadoonet/fscrawler/tree/master
主要功能
- 本地文件系统(挂载盘)爬取和创建文件索引,更新已经存在的和删除旧的文档;
- 远程文件系统爬取例如:SSH/FTP等;
- 允许 REST 接口方式上传你的二进制文件到 es。
下载和安装
docker 下载
docker pull dadoonet/fscrawler
运行
docker run -it --rm \
-v ~/.fscrawler:/root/.fscrawler \
-v ~/tmp:/tmp/es:ro \
dadoonet/fscrawler fscrawler job_name
-
/root/.fscrawler是程序的工作目录,会读取该目录下的_settings.yaml 文件,如果不存在会默认创建一个; -
/tmp/es:ro是待爬取的文件目录,该文件夹下的文件会被读取,写入es 对应的索引,其中索引可以在_settings.yaml 中指定,如果不指定会默认创建索引名为,启动任务的名称job_name_folder。
实践说明
我们下面创建一个爬取任务 job_name 为例进行功能说明。
创建工作目录
我创建一个工作目录如下:
/data/workspace/app/fscrawler
我在这个文件夹下创建了一个文件目录:./es 用于存放我需要索引的文件,_settings.yaml用于配置爬取的任务。
_settings.yaml 文件配置
为了验证各种文件格式,
- 我配置了支持ocr 识别,支持中文和英文字符识别;
- 为了能快速验证,文件目录检查时间我设置为1min;
- 配置了一个es 数据库用于存储解析后的数据,但没指定索引。
_settings.yaml文件如下(具体字段意义见注释说明):
---
name: "job_name" # job name
fs:
url: "/tmp/es" # 要索引文件路径
update_rate: "1m" # 更新频率
excludes: # 排除文件
- "*/~*"
json_support: false # 是否支持json
filename_as_id: false # 是否将文件名作为id
add_filesize: true # 是否添加文件大小
remove_deleted: true # 是否删除已删除的文件
add_as_inner_object: false # 是否将文件内容作为内部对象
store_source: false # 是否存储源文件
index_content: true # 是否索引内容
attributes_support: false # 是否支持属性
raw_metadata: false # 是否原始元数据
xml_support: false # 是否支持xml
index_folders: true # 是否索引文件夹
lang_detect: false # 是否检测语言
continue_on_error: false # 是否继续错误
add_as_inner_object: true # 是否将文件内容作为内部对象
ocr:
language: "chi_sim+eng" # 识别语言
enabled: true # 是否启用ocr
pdf_strategy: "ocr_and_text" # pdf策略
follow_symlinks: false # 是否跟随符号链接
elasticsearch:
nodes:
- url: "http://xxx.xxx.xxx.xxx:9200"
username: xxx
password: xxxx
bulk_size: 100
flush_interval: "5s"
byte_size: "10mb"
ssl_verification: true
push_templates: true
启动任务
docker run -it --rm \
-v /data/workspace/app/fscrawler:/root/.fscrawler \
-v /data/workspace/app/fscrawler/es:/tmp/es:ro \
dadoonet/fscrawler fscrawler job_name
02:41:04,665 INFO [f.console] ,----------------------------------------------------------------------------------------------------.
| ,---,. .--.--. ,----.. ,--, 2.10-SNAPSHOT |
| ,' .' | / / '. / / \ ,--.'| |
| ,---.' || : /`. / | : : __ ,-. .---.| | : __ ,-. |
| | | .'; | |--` . | ;. /,' ,'/ /| /. ./|: : ' ,' ,'/ /| |
| : : : | : ;_ . ; /--` ' | |' | ,--.--. .-'-. ' || ' | ,---. ' | |' | |
| : | |-, \ \ `. ; | ; | | ,'/ \ /___/ \: |' | | / \ | | ,' |
| | : ;/| `----. \| : | ' : / .--. .-. | .-'.. ' ' .| | : / / |' : / |
| | | .' __ \ \ |. | '___ | | ' \__\/: . ./___/ \: '' : |__ . ' / || | ' |
| ' : ' / /`--' /' ; : .'|; : | ," .--.; |. \ ' .\ | | '.'|' ; /|; : | |
| | | | '--'. / ' | '/ :| , ; / / ,. | \ \ ' \ |; : ;' | / || , ; |
| | : \ `--'---' | : / ---' ; : .' \ \ \ |--" | , / | : | ---' |
| | | ,' \ \ .' | , .-./ \ \ | ---`-' \ \ / |
| `----' `---` `--`---' '---" `----' |
+----------------------------------------------------------------------------------------------------+
| You know, for Files! |
| Made from France with Love |
| Source: https://github.com/dadoonet/fscrawler/ |
| Documentation: https://fscrawler.readthedocs.io/ |
`----------------------------------------------------------------------------------------------------'
02:41:04,683 INFO [f.p.e.c.f.c.BootstrapChecks] Memory [Free/Total=Percent]: HEAP [560.9mb/8.7gb=6.25%], RAM [19.6gb/35gb=56.2%], Swap [0b/0b=0.0].
02:41:04,860 WARN [f.p.e.c.f.s.Elasticsearch] username is deprecated. Use apiKey instead.
02:41:04,860 WARN [f.p.e.c.f.s.Elasticsearch] password is deprecated. Use apiKey instead.
02:41:04,869 INFO [f.p.e.c.f.FsCrawlerImpl] Starting FS crawler
02:41:04,869 INFO [f.p.e.c.f.FsCrawlerImpl] FS crawler started in watch mode. It will run unless you stop it with CTRL+C.
SLF4J: No SLF4J providers were found.
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See https://www.slf4j.org/codes.html#noProviders for further details.
SLF4J: Class path contains SLF4J bindings targeting slf4j-api versions 1.7.x or earlier.
SLF4J: Ignoring binding found at [jar:file:/usr/share/fscrawler/lib/log4j-slf4j-impl-2.22.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See https://www.slf4j.org/codes.html#ignoredBindings for an explanation.
02:41:05,230 INFO [f.p.e.c.f.c.ElasticsearchClient] Elasticsearch Client connected to a node running version 8.8.1
02:41:05,266 INFO [f.p.e.c.f.c.ElasticsearchClient] Elasticsearch Client connected to a node running version 8.8.1
02:41:05,331 INFO [f.p.e.c.f.FsParserAbstract] FS crawler started for [job_name] for [/tmp/es] every [1m]
02:42:05,430 INFO [f.p.e.c.f.t.TikaInstance] OCR is enabled. This might slowdown the process.
启动成功后,如果是首次启动,没有指定索引和settings.yaml 文件的话会自动创建,当日志会给出警告。
启动成功后文件目录发生了变化:
- 自动创建
_default文件夹, 该文件夹下会生成es版本6,7,8对应的全文索引的默认的schema; - 自动创建一个
_status.json文件,用来检查上次运行的时间和文件变更信息,如下:
{
"name" : "job_name",
"lastrun" : "2024-02-21T07:55:58.851263972",
"indexed" : 0,
"deleted" : 0
}
本地索引目录添加文件
fscrawler配置的每间隔1分钟进行一次文件同步操作,这里需要注意:
1、如果需要启动时将历史文件全量同步的话,需要在启动fscrawler之前就将文件放入settings.yaml配置字段 url对应的文件路径,我们配置的是/tmp/es,容器映射的文件目录是:/data/workspace/app/fscrawler/es 。
2、后续启动后创建了_status.json文件,文件里面的字段lastrun表示上次同步运行的时间,如果文件的修改时间在这个时间之前,是不会同步更新的,新增的文件修改时间必须是在这个时间之后才会同步。
在kibana验证同步效果(我的kibana 版本 8.8.1)
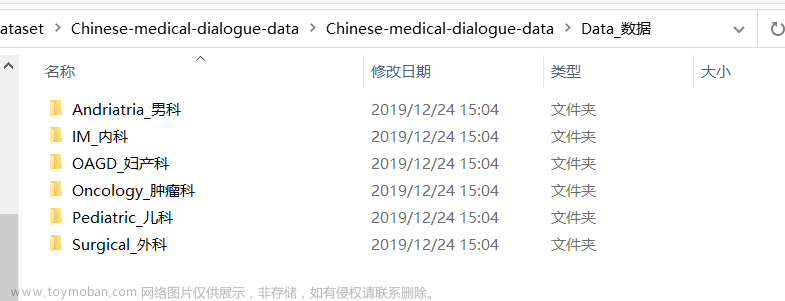
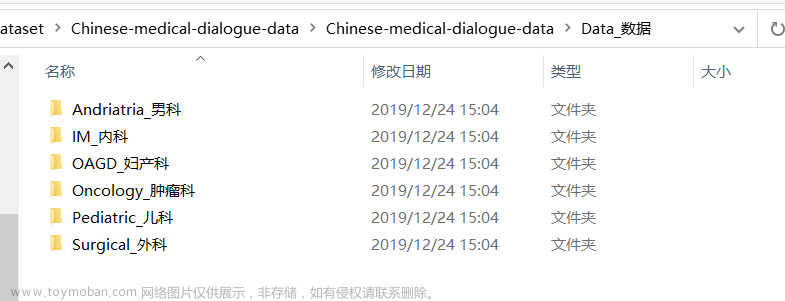
我在es目录下创建了多个格式的文件,包括txt、 doc、docx、ppt、pdf 和扫描件pdf 总共28个文件,文件目录如下:
在es中查看索引文档
-
在kibana创建可视化搜索应用,左侧菜单->Enterprise->Search Application;

-
点击创建并选择下拉选择的索引,输入应用名称即可


-
展示效果,可以看到文件内容和文件类型,pdf的扫描件效果也不错。

支持rest接口上传文件
启动时新增参数--rest 即可启动rest接口上传文件(注意:我本地为了测试方便使用--net=host -p 8080:8080 来映射主机端口到容器)
docker run -it --net=host -p 8080:8080 --rm \
-v /data/workspace/app/fscrawler:/root/.fscrawler \
-v /data/workspace/app/fscrawler/es:/tmp/es:ro \
dadoonet/fscrawler fscrawler job_name --rest
- 启动后可以查看fscrawler 状态和配置
// http://127.0.0.1:8080/fscrawler
{
"ok": true,
"version": "2.10-SNAPSHOT",
"elasticsearch": "8.8.1",
"settings": {
"name": "job_name",
"fs": {
"url": "/tmp/es",
"update_rate": "1m",
"excludes": [
"*/~*"
],
"json_support": false,
"filename_as_id": false,
"add_filesize": true,
"remove_deleted": true,
"add_as_inner_object": true,
"store_source": false,
...
- 上传文件
~/workspace » echo "This is my text" > test.txt
~/workspace » curl -F "file=@test.txt" "http://127.0.0.1:8080/fscrawler/_document" ernestxwli@VM-142-118-tencentos
{"ok":true,"filename":"test.txt","url":"http://xxx.xxx.xxx.xxx:9200/job_name/_doc/dd18bf3a8ea2a3e53e2661c7fb53534"}%
- 上传文件并添加额外标签
写入文件额外信息json到tags.txt, 内容如下{"external":{"tenantId": 24,"projectId": 34,"description":"these are additional tags"}}
curl -F "file=@test.txt" -F "tags=@tags.txt" "http://127.0.0.1:8080/fscrawler/_document"
- 查看es索引文档信息

可以看到业务可以根据自己的需要对文件进行字段扩展,以便满足业务需求, 当然还提供了其他接口来处理文件的删除等,详见官方文档。文章来源:https://www.toymoban.com/news/detail-837234.html
总结
FSCrawler 提供了一站式的集成方案用来解决各种文档数据转化并存储到es数据库,也有一定的灵活性来自定义拓展字段,可以作为一种文档转换存储工具的选择之一。文章来源地址https://www.toymoban.com/news/detail-837234.html
到了这里,关于【elasticsearch实战】知识库文件系统检索工具FSCrawler的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!