requests模块可以用来获取网络数据;
那么对于爬虫来说,要获取下图网页中的内容,就需要网页的URL。
复制链接方法是,打开网页,点击链接框,右键选择复制。
requests.get()函数可用于模拟浏览器请求网页的过程,在Python语言中使用该函数,就能够获取网页数据。
get()函数中传入要访问网页的URL,就像浏览器打开URL一样。
(1)获取网页内容的步骤
(2)代码实现
# 使用import导入requests模块 import requests # 将网页链接赋值给url url = "https://*****************/" # 使用requests.get()方法获取url的内容,将结果赋值给response response = requests.get(url) # 输出response print(response)
返回的response对象,就是响应消息;
(3)获取状态码
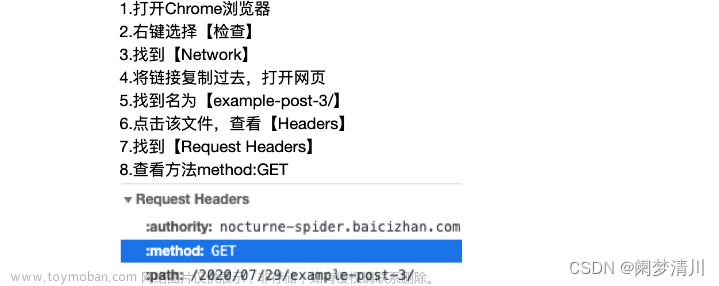
在浏览器中查看Response Headers中的信息就能够找到status:200,状态码200代表此次请求执行成功。
使用.status_code属性就可以查看状态码,这里输出的状态码数据类型是整型
import requests url = "https://nocturne-spider.baicizhan.com/2020/07/29/example-post-3/" response = requests.get(url) statusCode = response.status_code print(statusCode)
而只有状态码返回为200时,才能够成功获取到网页内容。
为满足上面的运行逻辑,我们要使用条件判断语句if..else先判断状态码,当状态码等于200时,再进行下一步操作。
if response.status_code == 200:
print(response.status_code)
else:
print("请求数据失败")(4)提取信息,获取内容
通过请求URL,获取到了Web服务器返回的信息,
要用.text属性,该属性能够将获取到的信息提取出来。
网页内容多,我们可以用切片(遵循左闭右开,将字符串进行分割)方法,输出前1000个字符;
if response.status_code == 200:
content = response.text[:1000]
print(content)
else:
print("请求数据失败")(5)HTML
刚刚输出的内容是HTML语言,它是由许多的标签组成,这些标签构成网页的内容;
这个就是类似输出的HTML语言
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=2"> <meta name="theme-color" content="#222"> <meta name="generator" content="Hexo 5.1.1"> <link rel="apple-touch-icon" sizes="180x180" href="/images/apple-touch-icon-next.png"> <link rel="icon" type="image/png" sizes="32x32" href="/images/favicon-32x32-next.png"> <link rel="icon" type="image/png" sizes="16x16" href="/images/favicon-16x16-next.png"> <link rel="mask-icon" href="/images/logo.svg" color="#222"> <link rel="stylesheet" href="/css/main.css"> <link rel="stylesheet" href="/lib/font-awesome/css/all.min.css">
文章来源:https://www.toymoban.com/news/detail-837238.html
(6)总结
HTML是构成网页的标记语言。
URL指定了要访问文档的具体地址。
HTTP协议规定了文档的传递方式。
爬虫就是根据URL,通过HTTP协议去获取HTML内容。文章来源地址https://www.toymoban.com/news/detail-837238.html
到了这里,关于Python爬虫基础:使用requests模块获取网页内容的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!