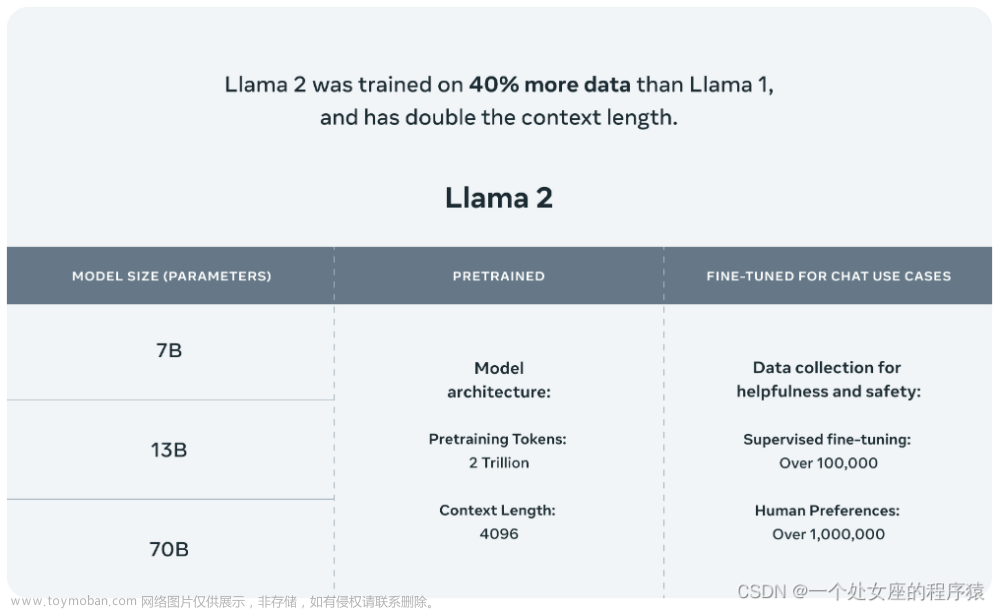
LLAMA介绍
LLaMA是由Facebook的母公司Meta AI设计的一个新的大型语言模型。LLaMA拥有70亿到650亿个参数的模型集合,是目前最全面的语言模型之一。
Llama是目前唯一一个可以进行本地部署和本地训练的大型模型,对各种提问有非常好的处理能力。非常适合个人和中小型企业,构建自己的大数据模型。
很多人都说是ChatGPT的平替。通过微调来满足特定小众行业的使用,将会在未来有非常大的潜力。
Mac上由于没有Nvidia显卡的加持,无法配置CUDA进行深度学习。好在有大神制作了C++的库,能实现小成本在低配Mac上跑模型的能力。

llama.cpp
是一个推理框架,在没有GPU跑LLAMA时,利用Mac M1/M2的GPU进行推理和量化计算。
Mac跑LLAMA唯一的路。同样也可以在Windows下面跑起来。
它是ggml这个机器学习库的衍生项目,专门用于Llama系列模型的推理。llama.cpp和ggml均为纯C/C++实现,针对Apple Silicon芯片进行优化和硬件加速,支持模型的整型量化 (Integer Quantization): 4-bit, 5-bit, 8-bit等。社区同时开发了其他语言的bindings,例如llama-cpp-python,由此提供其他语言下的API调用。
https://github.com/ggerganov/llama.cpp
安装llama.cpp
本地快速部署体验推荐使用经过指令精调的Alpaca-2模型,有条件的推荐使用6-bit或者8-bit模型,效果更佳。 下面以中文Alpaca-2-7B模型为例介绍,运行前请确保:
1、系统应有make(MacOS/Linux自带)或cmake(Windows需自行安装)编译工具
2、建议使用Python 3.10以上编译和运行该工具
3、必装的mac依赖
xcode-select --install # Mac的Xcode开发者工具,基本是必装的,很多地方都需要用到。
brew install pkgconfig cmake # c和c++的编译工具。
1、源码编译
git clone https://github.com/ggerganov/llama.cpp
2、编译
对llama.cpp项目进行编译,生成./main(用于推理)和./quantize(用于量化)二进制文件。
make
Windows/Linux用户如需启用GPU推理,则推荐与BLAS(或cuBLAS如果有GPU)一起编译,可以提高prompt处理速度。以下是和cuBLAS一起编译的命令,适用于NVIDIA相关GPU。
make LLAMA_CUBLAS=1
macOS用户无需额外操作,llama.cpp已对ARM NEON做优化,并且已自动启用BLAS。M系列芯片推荐使用Metal启用GPU推理,显著提升速度。只需将编译命令改为:LLAMA_METAL=1 make,
LLAMA_METAL=1 make
3、检查
编译成功会在目录下产生main等可执行的命令,下面转换量化模型文件时,会用到的命令就准备好了。
手动转换模型文件为GGUF格式
如果下载的是生成好的gguf模型就不需要手动转换了。为啥要这个格式。这个格式的LLAMA.cpp才认。其它格式的数据不认。
1、下载 Llama 2 模型
首先,从 Hugging Face https://huggingface.co/meta-llama 上下载你想要使用的 Llama 2 模型,比如 7B-Chat,我的Mac是8G内存,M2芯片,估计也只能跑到这个模型,再大的机器跑不动。
值得一提的是:https://huggingface.co/meta-llama/Llama-2-7b-chat 下载时,第一次需要授权,需要到meta官网,下面这个链接
https://llama.meta.com/llama-downloads
去提交一下邮件。这里选国家时会有意想不到的结果,自己思考一下。
如果要体验英文原版,就用上面的,会比较麻烦,但是对英文的回复比较好。
参考教程 https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/manual_conversion_zh
如果要使用中文语料库,需要先合并为原始模型和中文的模型,再生成bin,再去转换为gguf格式。喜欢折腾的可以试试。
如果要使用我这个中文混合模型,可以直接下载gguf格式。下面这几步都不用了。省事多了。
下载地址:https://huggingface.co/hfl/chinese-llama-2-7b-gguf/tree/main
记得选ggml-model-q4_0.gguf这个模型。
2、下载 llama.cpp 库,并按上面的流程进行编译安装成功
3、转换模型格式
然后,你需要把模型的文件转换成 GGUF 格式,使用 llama.cpp 库中的 convert.py 脚本来完成。转换时需要指定模型的路径和上下文长度(模型可以处理的最大的文本长度),不同的模型可能有不同的上下文长度。
如果模型是 LLaMA v1,则使用 --ctx 2048,如果你的模型是 LLaMA v2,则使用 --ctx 4096。这里使用 --ctx 4096。如下所示:
# 转换模型文件
python3 convert.py models/7B-Chat --ctx 4096
如果安装过程缺python包直接pip install 安装即可。
4、量化模型文件
使用 llama.cpp 库中的 quantize 程序来进行模型量化,使用 quantize 命令:
# 运行 quantize 程序,指定输入和输出的模型文件和量化方式
./quantize ./models/7B/ggml-model-f16.gguf ./models/7B/ggml-model-q4_0.gguf q4_0
这样,在 7B-Chat 文件夹中就生成一个 4 位整数的 GGUF 模型文件。
5、运行模型
./main -m ./models/7B/ggml-model-q4_0.bin \
-t 8 \
-n 128 \
-p 'The first president of the USA was '
# run the inference 推理
./main -m ./models/llama-2-7b-hf/ggml-model-q4_0.bin -n 128
#以交互式对话
./main -m ./models/llama-2-7b-hf/ggml-model-q4_0.bin --color -f prompts/alpaca.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3
#chat with bob
./main -m ./models/llama-2-7b-hf/ggml-model-q4_0.bin -n 256 --repeat_penalty 1.0 --color -i -r "User:" -f prompts/chat-with-bob.txt
此步骤过于烦锁,主要是模型文件占了几十GB。所以我直接下载别人的中文模型进行使用。不需要再手动进行转换、量化等操作。
以WebServer形式启动
调用手册:https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md
用WebServer形式。可以对接到别的系统里面,像FastGPT或者一些界面上,就可以无缝使用了。
1、启动server 参数请./server -h 查看,或者参考手册
./server --host 0.0.0.0 -m /Users/kyle/MyCodeEnv/models/ggml-model-q4_0.gguf -c 4096 --n-gpu-layers 1
默认会开到8080端口上,配置可改。不加gpu-layers走CPU,会报错。设个1就行
2、用CURL进行测试
curl --request POST \
--url http://127.0.0.1:8080/completion \
--header "Content-Type: application/json" \
--data '{"prompt": "给我讲个冷笑话:","n_predict": 128}'
3、效果如图

感觉 就是训练的还是量少,有些问题会胡说。理解不了的问题反应会非常慢。会花很长的时间。
Python调用接口库
https://github.com/abetlen/llama-cpp-python
https://llama-cpp-python.readthedocs.io/en/latest/install/macos/
1、Mac用户,pip编译,最简
安装llama-cpp-python (with Metal support)
为了启用对于Metal (Apple的GPU加速框架) 的支持,使用以下命令安装llama-cpp-python:
CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install llama-cpp-python
2、代码中使用,安装好之后可以直接用requests调用。无需第1步的llama-cpp-python依赖包。使用通用的ChatGPT的问答形式回答。
也可以不经Server直接调用模型文件
# -*- coding: utf-8 -*-
import requests
url = 'http://localhost:8080/v1/chat/completions'
headers = {
'accept': 'application/json',
'Content-Type': 'application/json'
}
dataEn = {
'messages': [
{
'content': 'You are a helpful assistant.',
'role': 'system'
},
{
'content': 'What is the capital of France?',
'role': 'user'
}
]
}
data = {
'messages': [
{
'content': '你是一个乐于助人的助手',
'role': 'system'
},
{
'content': '二战是哪一年爆发的?',
'role': 'user'
}
]
}
response = requests.post(url, headers=headers, json=data)
print(response.json())
print(response.json()['choices'][0]['message']['content'])
3、直接调用模型文件,需要安装llama-cpp-python包
# -*- coding: utf-8 -*-
from llama_cpp import Llama
# 加截模型
# llm = Llama(model_path='/Users/kyle/MyCodeEnv/models/ggml-model-q4_0.gguf', chat_format="llama-2") # 可以指定聊天格式
llm = Llama(model_path='/Users/kyle/MyCodeEnv/models/ggml-model-q4_0.gguf')
# 提问
response = llm("给我讲一下英国建国多少年了", max_tokens=320, echo=True)
# response = llm.create_chat_completion(
# messages=[
# {"role": "system", "content": "你是一个乐于助人的助手"},
# {
# "role": "user",
# "content": "给我讲一个笑话"
# }
# ]
# )
# print(response)
# 回答
print(response['choices'][0])
最后贴个官方的教程
https://llama-cpp-python.readthedocs.io/en/latest/install/macos/
再慢慢研究研究微调和训练自己的语料吧。文章来源:https://www.toymoban.com/news/detail-837687.html
跟上LLM的步伐。不接触AI就要落后了。
更多精彩内容,请关注我的公众号:青塬科技。文章来源地址https://www.toymoban.com/news/detail-837687.html
到了这里,关于Mac上LLAMA2大语言模型安装到使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!