SadTalker是一款先进的人工智能模型,它通过从音频中学习生成3D运动系数,并使用全新的三维面部渲染器来生成头部运动,只需传入一张照片和一段音频,就能生成高质量的AI数字人视频

工作原理
1、显式地对音频和不同类型的运动系数之间的联系进行单独建模
2、通过蒸馏系数和3D渲染的脸部,从音频中学习准确的面部表情
3、通过条件VAE设计PoseVAE来合成不同风格的头部运动
4、使用生成的三维运动系数映射到人脸渲染的无监督三维关键点空间,合成最终视频
文章来源地址https://www.toymoban.com/news/detail-837701.html
SadTalker生成后的人物头部运动规律,面部表情自然,口型也和音频的内容保持一致(小姐姐还会眨眼睛!)

最新中文版:
百度网盘:https://pan.baidu.com/s/1AMInL9l_LxfQ0g3j1TrWQA?pwd=8r4f
使用方法
1、上传人物图片和音频(音频可以是英文、中文、歌曲)
2、设置参数(下面会详细介绍)
3、点击“生成”按钮

参数说明
· 姿式风格:调节头部运动风格,默认0
· 表达量表:人物表情丰富程度,默认1
· 生成中的批量大小:生成视频的速度,默认1,显卡好可以适当拉大
· 预处理
crop:从图片中截取头部做视频
resize:拉伸图片,人物被压缩选择此项
full:全身照做视频
extcrop:加强版crop,主要聚焦头部
extfull:加强版全身
· 面部渲染:两种模式可自由尝试
· GFPGAN:让面部高清化
在控制台可以查看当前的处理进度,程序执行完毕会输出信息The generated video is named

生成的视频保存在SadTalker\results路径下,也可以在网页端下载

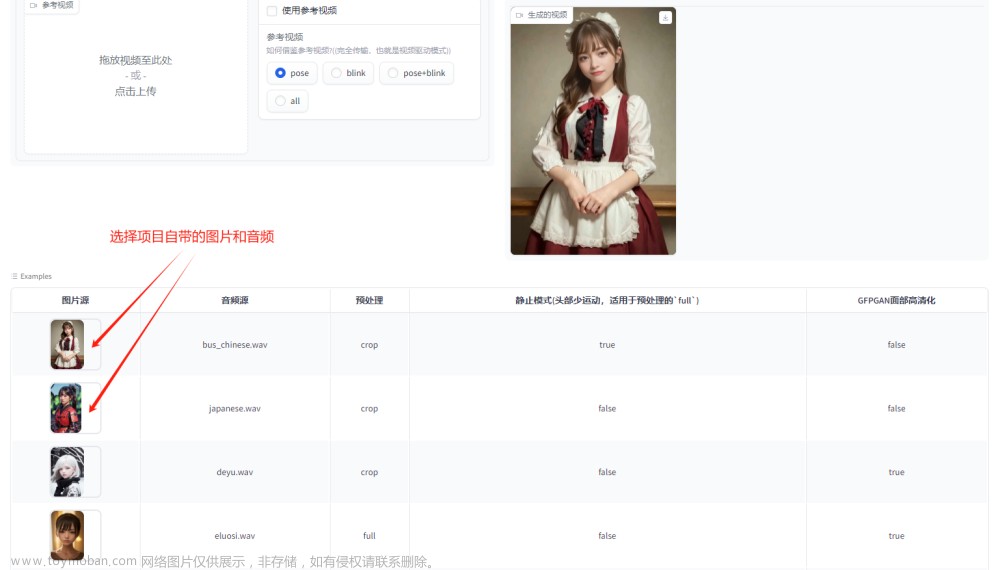
在操作界面下方的Examples中提供了部分图片和音频,请点击“图片源”选择使用
注意事项
①项目安装路径不要包含中文
②推荐使用GTX1060以上显存运行此项目
③使用过程中若不慎关闭软件后台,请重新打开,并刷新网页文章来源:https://www.toymoban.com/news/detail-837701.html
到了这里,关于照片也能说话了?嘴型表情全同步,AI数字人时代要来了的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!