无模型的强化学习算法
学习「强化学习」(基于这本教材,强烈推荐)时的一些总结,在此记录一下。
动态规划算法需要马尔可夫决策过程是已知的(状态转移函数、奖励函数已知),智能体不用真正地与环境互动也能在「理性」世界里求得最优策略。
现实通常并非如此,环境已知恰恰是很少见的。所以这里来看看「无模型的强化学习方法」,主要介绍:基于 「时序差分」 的Sarsa 和 Q-learning。
时序差分方法
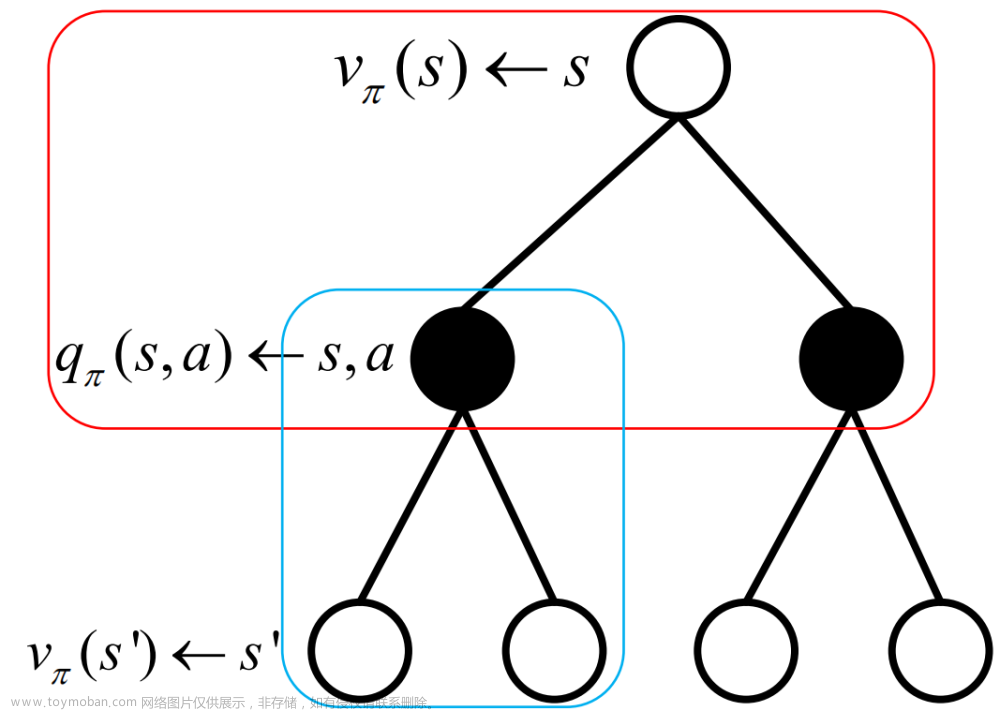
时序差分结合了「蒙特卡洛方法」和「动态规划」。在「蒙特卡洛方法」中我们知道,要想估计一个状态的价值,可以以该状态出发,模拟出大量状态转移序列再求得这些序列的期望回报:
我们将 \(\frac{1}{k}\) 换成一个可任意设置的常数 \(\alpha\),表示对价值估计更新的步长;再将 \(G_t = E[R_t + \gamma V{(s_{t+1})}]\) 换成单步状态转移时的回报 \(r_t + \gamma V{(s_{t+1})}\),表示只需要当前步状态转移结束即可进行计算回报。可得到时序差分算法:
其中 \(r_t + \gamma V(s_{t+1}) - V(s_t)\) 被称为 「时序差分误差」。
Sarsa算法
我们同样可以用时序差分算法来更新动作价值函数Q(s, a):
这样一来,在不知道「奖励函数 \(R\)」和「状态转移函数 \(P\)」的情况下,我们也可以通过执行动作来和环境交互得到反馈的数据(执行动作的奖励和下一个状态),再根据得到的数据用时序差分算法更新动作价值估计。
那该根据什么选取动作呢?可以使用 「\(\epsilon\)-贪心算法」 选取:每个状态都有 \((1-\epsilon)\) 的概率选取具有最大估计价值的动作,也有\(\epsilon\) 的概率随机选取一个动作,其中 \(\epsilon\) 是个很小的值。也就是说,采用这个算法有很大概率选「最好」的动作(跟普通贪心算法一样),也有小概率盲选(用于探索其它动作):

结合上面两个做法,我们可以制定这么一个强化学习流程:从初始状态出发,通过 \(\epsilon\)-贪心算法选择一个动作来执行,执行后通过环境得知奖励和新的状态,再在新的状态中通过 \(\epsilon\)-贪心算法选取动作与环境交互……重复这个过程直到到达目标状态。之后再从初始状态开始重复这个流程,多重复几次后,再贪心地在每一个状态选择动作价值最大的动作(即 \(\pi(s) = max{Q^\pi(s, a)}\))就可以得到满意的策略了。
这样,我们已经可以得到一个完整的强化学习算法了(教材中的图):

可以看到,这个算法的动作状态更新用到了当前状态s、当前选择动作a、执行动作获取的奖励r、执行动作后进入的下一个状态s'以及s'下选择的下一个动作a',故得名 「Sarsa算法」。
多步Sarsa算法
蒙特卡洛方法会求整个序列的回报并取多个序列的回报期望用于评估状态价值,这是十分合理的,只是需要算很多序列后再进行策略提升,显得比较慢;时序差分法则比较快,但只用了一个奖励和下一状态的价值估计,这个估计终究不是真实的价值,显得不是很「准」。而 「多步Sarsa算法」 则综合二者,主要是将「时序差分误差」进行了调整:

它不像蒙特卡洛方法那样「全走完」,也不像Sarsa那样「走一步」,而是选择了「走n步」。也就是说靠近现在的一部分状态它会正常计算,离得比较远的则采取估计。算法的其它部分都与常规的Sarsa一样,只不过要注意有时可能还没走够n步就已经到达目标状态了,这时的估计部分就相当于0。
Q-learning算法
Q-learning算法也是基于「时序差分算法」实现的,与「Sarsa算法」最大的不同在于,它不是通过 \(\epsilon\)-贪心算法,而是通过 直接贪心 来获取下一个动作的(这与「贝尔曼最优方程」思想是一致的):

总结
采样数据的策略称为「行为策略」,用这些数据来更新的策略称为「目标策略」。如果一个算法中的行为策略和目标策略相同,那这个算法就是 「在线策略算法」;反之称为 「离线策略算法」。

Sarsa 是在线策略算法,而 Q-learning 是离线策略算法。离线策略算法可以重用旧的策略产生的轨迹,可以节省资源,也更受欢迎。
补充:Dyna-Q算法
与前文提到的两种方法不同,Dyna-Q算法是 基于模型的强化学习算法,在这里提它是因为它与Q-learning有些关系:

Dyna-Q算法需要一个模拟的环境模型 \(M\),它会记录曾经真实与环境交互下得到的奖励与新状态,并与交互后的状态、动作绑定。它就是一个键为(当前状态s、动作a),值为(环境反馈的奖励r、环境反馈的新状态s')的字典。
而这个字典会用于「Q-planning」,Q-planning要做的就是从字典中随机取出一个键值对(也就是(s、a)和(r、s')),并让它们进行「虚拟」的Q-learning。这也是Dyna-Q是「基于模型」的体现。文章来源:https://www.toymoban.com/news/detail-837703.html
可以看到,在每次与环境进行交互执行一次 Q-learning 之后,Dyna-Q 会做N次 Q-planning。如果 N 为0的话,那Dyna-Q就等价于Q-learning了。文章来源地址https://www.toymoban.com/news/detail-837703.html
到了这里,关于无模型的强化学习方法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!