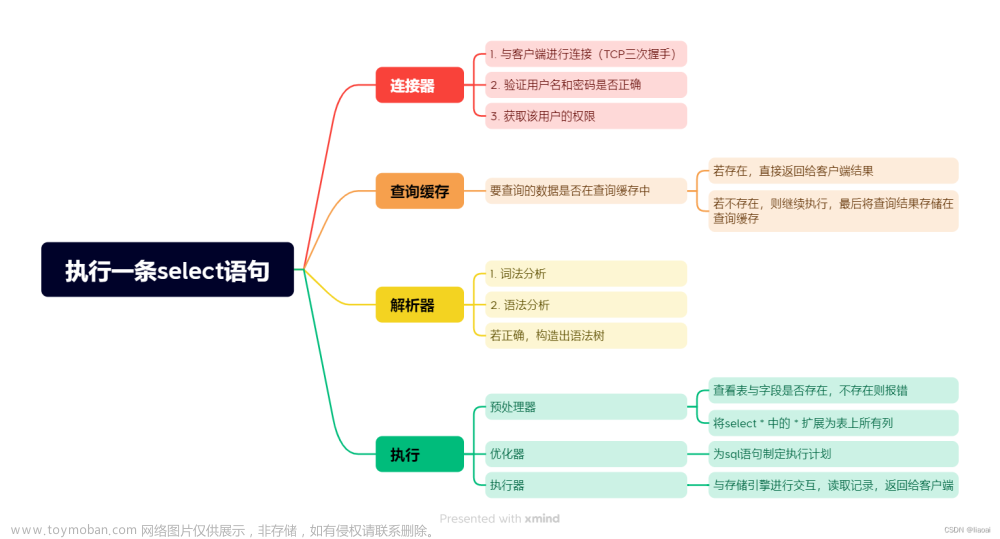
推荐:SQL语句执行顺序相关问题。
MySQL Server架构
分层概述
MySQL Server架构可抽象为3层。
- 连接层:验证用户名密码,认证成功后,获取当前账号的权限并缓存,并分配TCP连接池和线程池资源。
- 处理层:实现核心的处理功能。
- 存储层:将处理后的数据高性能安全的写入磁盘,或从磁盘中正确的读取。
模块构成与执行顺序
-
连接层 :提供多个线程用于客户端和服务器交互,连接层包含连接池与线程池。
- 连接池:MySQL可以有多个客户端进行连接,为了解决TCP连接频繁创建销毁引起的性能损耗,所以建立了TCP连接池,采用长连接模式复用TCP连接。
- 线程池:MySQL采用多线程的方式运行,MySQL Server也会分配一个线程来处理后面的流程,像TCP连接池一样,为了避免开销,也会创建一个线程池。
- SQL接口:接收SQL指令,返回查询结果。
- 缓存缓冲区:使用键值对的方式缓存查询的结果(由于命中率太低在8的版本中被废弃)。
- 解析器:对SQL语法进行分析,让程序读懂SQL。将SQL语句分解,验证权限,创建为语法树,如果SQL语法错误,也是在这一步给的提示。流程如下:词法分析->语法分析->分析机->抽象语法树。
- 优化器:对SQL的执行进行优化,进行查询时,根据索引和SQL的情况,选择最合适的查询策略,这个模块是最复杂的模块。
- 可插拔存储引擎: 存储引擎(InnoDB,MyISAM等)用于规范数据如何被高效安全的读写。可插拔主要体现在针对库或者表可以进行引擎切换,结合日志模块 (老生常谈的Bin、Relay、Redo、Undo、Error、General、Slow这些)生成相关日志。
- 文件系统:这是操作系统层的东西,数据不是无脑存储到磁盘上的,需要文件系统的约束,它提供了对存储设备的访问、分配、保护和检索文件的方法,文件系统诸如NTFS,EXFAT,FAT32,NFS、NAS,EXT2、EXT3。
data文件相关
InnoDB引擎.frm、.idb、.opt文件是什么?
MySQL登录成功后使用SHOW VARIABLES LIKE 'datadir';,或者Linux系统下查看vim /etc/my.cnf,找datadir项,可查看数据存储的目录。认准一个使用InnoDB引擎的非空数据库,在datadir/数据库名的目录下会发现有.frm、.idb文件、.opt类型的文件。
- .frm 存储表结构的数据。
- .idb用于存储数据(5.7及以上默认使用,8的版本只有.idb,把idb和.frm进行了合并)。
- .opt,通常叫做db.opt,纯文本,用于存储字符集编码排序规则那套东西:例如default-character-set=utf8mb4;default-collation=utf8mb4_unicode_ci;(8的版本已去除)
InnoDB引擎.idb与ibdata1文件版本差异
注意mysql5.5.7到5.6.6的版本中的数据,是放在data/ibdata1文件中的。
.idb叫做独立表空间,ibdata1叫做系统表空间。
使用show variables like 'innodb_file_per_table';可查看相关配置,如果是OFF,则表示使用ibdata1文件。ON表示使用独立表空间。
MyISAM引擎.frm、.MYD、.MYI、.opt文件是什么的?
MySQL登录成功后使用SHOW VARIABLES LIKE 'datadir';,或者Linux系统下查看vim /etc/my.cnf,找datadir项,可查看数据存储的目录。认准一个使用InnoDB引擎的非空数据库,在datadir/数据库名的目录下会发现有.frm、.MYD、.MYI、.opt文件类型的文件。
- .frm 存储表结构的数据(在8的版本变成了.sdi)。
- .MYD,用于存数据。
- .MYI,用于存储索引。
- .MYD、.MYI合并到一起,相当于InnoDB引擎的idb文件。
- .opt,通常叫做db.opt,纯文本,用于存储字符集编码排序规则那套东西:例如default-character-set=utf8mb4;default-collation=utf8mb4_unicode_ci;(8的版本已去除)。
data下的各种日志,会在另一篇文章中讲。
既然有了information_schema 库来存储元数据,为什么还要.frm和.opt?
information_schema库,用于存储数据库的结构、表、视图、列、约束、索引等信息的元数据,同时.frm和.opt也存储了一份元数据,这也是问题的由来。
侧重定位不同,information_schema 数据库是一个用于快速检索元数据的库,方便开发者进行元数据分析和操作,而.frm是专门服务于表结构的,MySQL本身玩的就是数据,适当的冗余不见得是坏事。
information_schema的部分数据基于.frm、.opt,还是独立维护?
部分基于.frm、.opt。
试试就知道,开了一个虚拟机找一个测试库,.frm非文本文件没法改,修改某个库的.opt文件,将default-collation=utf8mb4_unicode_ci;改为default-collation=utf8mb4_general_ci;重启MySQL服务,执行SELECT * FROM information_schema.SCHEMATA WHERE SCHEMA_NAME = 'db_name';发现编码同步做了更改。
扩展
MySQL8对缓存缓冲区的移除
缓存缓冲区和Redis在项目中作用与用法相似,用于缓存查询语句查询出来的结果,key为SQL语句,val为数据,使用空间换时间,里面涉及表缓存,记录缓存,权限缓存等。
此模块在8的版本中移除,因为命中率太低。如果查询请求包含某些系统函数(now()),或者一些系统库(如mysql、information_schema、performance_schema)那么请求就不会被缓存。是缓存就会有一致性的问题,mysql会监听每一张表的写操作(DDL,DML),如果发生了变更,将会删除缓存。其次是对于复杂的业务,不会只有读操作,这也是分表冷热数据分离的原因之一,所以被移除掉了。
客户端连接器
连接器属于客户端(MySQL Client、Navicat、PHP的PDO,Java的JDBC等)的组件,所以放到了这里。用于和MySQL Server通信。一般是有TCP和Socket两种通信方式(与PHP与Nginx通信方式类似)。
- TCP就是常见的IP端口号的方式。
- Socket就是UNIX套接字,一种本地通信方式。在linux中创建一个套接字文件(.sock文件),客户端通过该文件与服务器通信。与TCP/IP相比,使用UNIX域套接字可以更快地进行本地通信,因为不需要经过网络协议栈的处理。但是因为无法远程的局限性,所以用得少,对PHP开发者来说,PDO和主流框架,都支持此连接方式。
查询缓存命中率
执行show status like 'Qcache%';会得到一个kv格式的表格
Qcache_free_blocks: 查询缓存中空闲的内存块数量。
Qcache_free_memory: 查询缓存中可用的内存大小。
Qcache_hits: 查询缓存命中的次数,即从查询缓存中成功获取到结果的查询次数。
Qcache_inserts: 查询缓存中插入的查询次数。
Qcache_lowmem_prunes: 由于内存不足而从查询缓存中移除的查询次数。
Qcache_not_cached: 由于不符合查询缓存规则而没有被缓存的查询次数。
Qcache_queries_in_cache: 当前查询缓存中缓存的查询数量。
Qcache_total_blocks: 查询缓存中的内存块总数量。
数据库缓冲池
InnoDB是依靠页来管理存储空间的,CRUD的操作是对页面的读写。因为磁盘IO操作慢,内存操作快,所以MySQL Server会使用内存来作为数据缓冲池,真正访问页之前,需要把磁盘上的页缓存到内存中的Buffer Pool后才可以访问,用于提升MySQL的性能。
流程:当数据库系统需要从磁盘读取数据时,它首先检查缓冲池中是否已经缓存了相应的数据页。如果数据页已经在缓冲池中,则不需要从磁盘读取,而是直接从缓冲池中获取数据,这样可以大大提高数据检索速度。
缓冲池的数据有数据页、索引页、锁数据、和数据字典。
配置缓冲池
MyISAM:缓冲池和innodb的不一样,是键缓存,参数为key_buffer_size;
查看:SHOW VARIABLES LIKE 'key_buffer_size'; SHOW STATUS LIKE 'Key_blocks_%';单位为字节。
配置:在my.cnf中配置key_buffer_size = 256M后重启。
InnoDB:
查看:SHOW VARIABLES LIKE 'innodb_buffer_pool_size';单位为字节。
配置:在my.cnf中配置innodb_buffer_pool_size = 256M后重启。
不想要重启,可以使用set globak k=v,(5.7及以上可用)。但是无法持久化保存。
多个缓冲池
在多线程情况下,访问buffer pool中的数据需要加锁处理,对于并发量打的情况下,加锁会影响处理速度,所以就考虑到拆分buffer pool的情况,用于提高并发处理的能力。每个buffer pool被称为一个实例,他们是独立的,独立的申请内存,独立的管理数据。
查看:SHOW VARIABLES LIKE 'innodb_buffer_pool_instances';
配置:在my.cnf中配置innodb_buffer_pool_instances= 2后重启。
每个buffer_size为innodb_buffer_pool_size / innodb_buffer_pool_instances;
当innodb_buffer_pool_size<=1GB时,设置多个实例是无效的。文章来源:https://www.toymoban.com/news/detail-837796.html
执行SQL时更新了缓冲池的数据,这些数据会实时同步到磁盘吗?
不会。
对数据表中的记录进行修改时,首先会修改缓冲池中的数据,然后会以一定的频率刷新到磁盘上,也不是每次更新操作都会把数据刷新到磁盘。缓冲池会采用一个叫做checkpoint的方式将更改的数据(脏页数据)写入到磁盘,此操作用于提升数据库的性能。文章来源地址https://www.toymoban.com/news/detail-837796.html
InnoDB与MyISAM区别
| 项目 | InnoDB | MyISAM |
|---|---|---|
| 事务 | 支持 | 不支持 |
| 外键 | 支持(但不支持跨引擎) | 不支持 |
| 最小锁粒度 | 行锁 | 表锁 |
| 日志 | 支持redo、undo、bin log | 支持bin log |
| 聚簇索引 | 支持 | 不支持 |
| 二级索引叶子节点存储 | 索引值与主键 | 索引值与所在行地址 |
| 适用场景 | 高并发,事务,金融 | 节省资源,轻量级简单业务 |
| count(*)统计算法 | 逐行遍历,时间复杂度O(n) | 内部自动维护,时间复杂度O(1) |
到了这里,关于MySQL Server架构概述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!