核心概念
索引
概念:
这里可以类比与 MySQL 中的表,但是不同于表
在 es 中索引有三层含义
- 表示源文件数据:通常说集群中有 user 索引,即表示集群服务中存在 user 这样一张“表”
- 表示索引文件:以加速查询检索为目的而设计和创建的数据文件,通常承载于某些特定的数据结构,如哈希、FST 等。例如:通常所说的 正排索引 和 倒排索引(也叫正向索引和反向索引)。就是当前这个表述,索引文件和源数据是完全独立的,索引文件存在的目的仅仅是为了加快数据的检索,不会对源数据造成任何影响
- 表示创建数据的动作:通常说创建或添加一条数据,在 ES 的表述为索引一条数据或索引一条文档,或者 index 一个 doc 进去。此时索引一条文档的含义为向索引中添加数据。
组成:
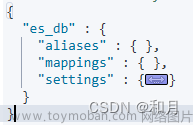
aliases:
索引别名,
es 中索引一旦创建,不允许修改结构,但是可以新建一个索引,然后将原索引数据迁移到新索引,再对新索引起别名,间接实现修改索引的目的
mappings:
映射关系,定义了索引中包含哪些字段,以及字段的类型、长度、分词器等
如下:
home、name、salary 表示字段名,类似与 MySQL 中的表字段
type:表示类型,
其中的常见的比如:
- text:文本【数据保存后会自动对该字段的值进行分词】
- keyword:表示不对该字段进行分词,全值保存,比如姓名
- long:表示数字
- float:小数
- ...
analyzer:表示指定的分词器
{
"es_db" : {
"aliases" : { },
"mappings" : {
"properties" : {
"home" : {
"type" : "text"
},
"name" : {
"type" : "keyword"
},
"salary" : {
"type" : "float"
},
"gender": {
"type": "text",
"analyzer": "standard"
}
}
},
"settings" : {}
}
}mappings 中常见的类型如下:
| 参数名称 |
释义 |
| analyzer |
指定分析器,只有 text 类型字段支持。 |
| copy_to |
该参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询 |
| dynamic |
控制是否可以动态添加新字段,支持以下四个选项: true:(默认)允许动态映射 false:忽略新字段。这些字段不会被索引或搜索,但仍会出现在_source返回的命中字段中。这些字段不会添加到映射中,必须显式添加新字段。 runtime:新字段作为运行时字段添加到索引中,这些字段没有索引,是_source在查询时加载的。 strict:如果检测到新字段,则会抛出异常并拒绝文档。必须将新字段显式添加到映射中。 |
| doc_values |
为了提升排序和聚合效率,默认true,如果确定不需要对字段进行排序或聚合,也不需要通过脚本访问字段值,则可以禁用doc值以节省磁盘空间(不支持 text 和 annotated_text) |
| eager_global_ordinals |
用于聚合的字段上,优化聚合性能。 |
| enabled |
是否创建倒排索引,可以对字段操作,也可以对索引操作,如果不创建索引,任然可以检索并在_source元数据中展示,谨慎使用,该状态无法修改。 |
| fielddata |
查询时内存数据结构,在首次用当前字段聚合、排序或者在脚本中使用时,需要字段为fielddata数据结构,并且创建倒排索引保存到堆中 |
| fields |
给 field 创建多字段,用于不同目的(全文检索或者聚合分析排序) |
| format |
用于格式化代码,如 |
| index |
是否对创建对当前字段创建倒排索引,默认 true,如果不创建索引,该字段不会通过索引被搜索到,但是仍然会在 source 元数据中展示。 |
| norms |
是否禁用评分(在filter和聚合字段上应该禁用) |
| null_value |
为 null 值设置默认值 |
| search_analyzer |
设置单独的查询时分析器 |
settings:
索引设置,常见设置如 分片和副本的数量等
文档:Document
文档是 ES 中的最小数据单元。它是一个具有结构化 JSON 格式的记录。文档可以被索引并进行搜索、更新和删除操作。

文档元数据,所有字段均以下划线开头,为系统字段,用于标注文档的相关信息:
- _index:文档所属的索引名
- _type:文档所属的类型名
- _id:文档唯一 id
- _source: 文档的原始 Json 数据
- _version: 文档的版本号,修改删除操作 _version 都会自增1
- _seq_no: 和 _version 一样,一旦数据发生更改,数据也一直是累计的。Shard 级别严格递增,保证后写入的 Doc 的 _seq_no 大于先写入的 Doc 的 _seq_no。
- _primary_term: _primary_term 主要是用来恢复数据时处理当多个文档的 _seq_no 一样时的冲突,避免 Primary Shard 上的写入被覆盖。每当 Primary Shard 发生重新分配时,比如重启,Primary选举等,_primary_term 会递增1。
常用指令
es 中指令都是基于 restful 风格
创建索引

#put / + 索引名
PUT /db_1
# 也可以指定一些配置
PUT /db_2
{
"settings": {
"number_of_shards": "1",
"number_of_replicas": "1"
},
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age" : {
"type" : "long"
},
"address" : {
"type" : "text"
}
}
}
}查询索引

#查看索引
GET /db_2删除索引

#删除索引
DELETE /db_1索引文档

#索引文档
PUT /db_2/_doc/1
{
"name":"张三",
"age":18,
"address":"和月努力学编程"
}
查询文档
有两种方式:一种模糊查询,一种精准查询
模糊查询

这里补充一个指令,查看文档字段分词效果
查看分词结果

#查看分词结果
#ik_max_word:会将文本做最细粒度的拆分
#analyzer:指定分词器
POST _analyze
{
"analyzer":"ik_max_word",
"text":"和月努力学习编程"
}精准查询

#精准查询
GET /db_2/_search
{
"query": {
"term": {
"name": "张三"
}
}
}更新文档
全文替换

可以看到更新成功,这里表示全文替换,并不是更新其中一个字段

#更新文档 这种方式是全文替换,PUT 和 POST 效果是一样的
PUT /db_2/_doc/1
{
"address":"和月努力学编程"
}
GET /db_2/_doc/1部分更新
可以看到当前 age 是 18

执行部分更新命令

再次查询,可以看到只有 age 变化了

#部分更新
POST /db_2/_update/1
{
"doc": {
"age": 16
}
}
GET /db_2/_doc/1删除文档

再次查询已经查不到 id 为 1 的文档了,删除成功
 文章来源:https://www.toymoban.com/news/detail-838142.html
文章来源:https://www.toymoban.com/news/detail-838142.html
#删除文档
DELETE /db_2/_doc/1
GET /db_2/_doc/1感谢观看!!!本次先介绍这么多,感兴趣的小伙伴可以关注留言,持续更新中文章来源地址https://www.toymoban.com/news/detail-838142.html
到了这里,关于ElasticSearch 核心概念以及常用命令的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!