1. xxl-job基本介绍
1.1 Quartz的体系结构
Quartz中最重要的三个对象:Job(作业)、Trigger(触发器)、Scheduler(调度器)。

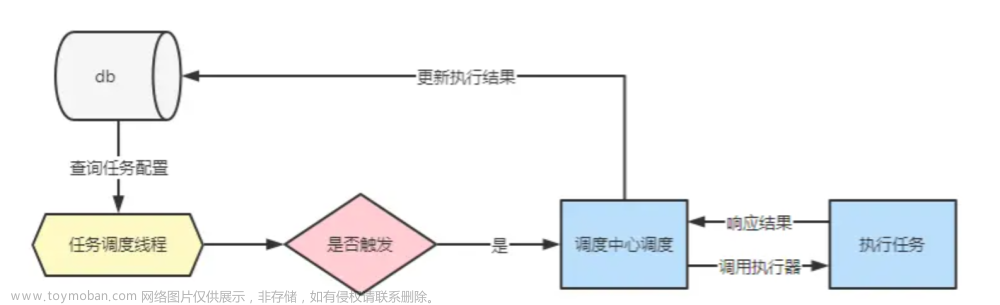
xxl-job的调度原理:调度线程在一个while循环中不断地获取一定数量的即将触发的Trigger,拿到绑定的Job,包装成工作线程执行。
当然,不管在任何调度系统中,底层都是线程模型。如果要自己写一个调度系统,一定要对多线程并发这一块有比较深入的学习,比如线程怎么启动怎么wait,怎么notify ,怎么加锁等等。
1.1. Quartz的不足
Quartz有差不多二十年的历史,调度模型已经非常成熟了,而且很容易集成到Spring中去,用来执行业务任务是一个很好的选择。
但是还是会有一些问题,比如:
1、调度逻辑(Scheduler)和任务类耦合在同一个项目中,随着调度任务数量逐渐增多,同时调度任务逻辑逐渐加重,调度系统的整体性能会受到很大的影响;
2、Quartz集群的节点之间负载结果是随机的,谁抢到了数据库锁就由谁去执行任务,这就有可能出现旱的旱死,涝的涝死的情况,发挥不了机器的性能。
3、Quartz本身没有提供动态调度和管理界面的功能,需要自己根据API进行开发。
4、Quartz的日志记录、数据统计、监控不是特别完善。
所以xxl-job和Elastic-Job都是对Quartz进行了封装,让用起来更简单,功能更强大。
1.2. xxl-job发展历史
源码地址:https://github.com/xuxueli/xxl-job
中文文档:https://www.xuxueli.com/xxl-job/
2015年开源,一个大众点评的程序员的业余之作。众所周知,大众点评因为被美团收购了,现在是美团点评。
xxl是作者名字许雪里的首字母简写,除了xxl-job之外作者还开源了很多其他组件,现在一共有11个开源项目。
到目前为止使用xxl-job的公司有几百家,算上那些没有登记的公司,实际上应该有几千家。
在xxl-job早期的版本中,直接使用了Quartz的调度模型,直到2019年7月7日发布的7.27 版本才移除Quartz依赖。
实际上即使重构代码移除了Quartz的依赖,xxl-job中也到处是Quartz的影子。比如任务、调度器、触发器的三个维度设计,是非常经典的。
最新发布版本是:2.3.1。
但是后面自从2.2.0版本开始,版本更新几乎没有什么变化
1.3. xxl-job特性
跟老牌的Quartz相比,xxl-job拥有更加丰富的功能。
总体上可以分成三类:
性能的提升:可以调度更多的任务。
可靠性的提升:任务超时、失败、故障转移的处理。
运维更加便捷:提供操作界面、有用户权限、详细的日志、提供通知配置、自动生成报表等等。
2. Xxl-job快速入门
1.1. 下载源码
1.1.1. release页面下载
https://github.com/xuxueli/xxl-job/releases
https://gitee.com/xuxueli0323/xxl-job
注意不要直接clone最新的master代码(SNAPSHOT版本),从发布界面下载稳定版本。
1.1.2. 在IDEA中打开

- /doc :文档资料,包括“调度数据库”建表脚本
- /xxl-job-admin :调度中心,项目源码,Spring Boot工程,可以直接启动
- /xxl-job-core :公共Jar依赖
- /xxl-job-executor-samples :执行器,Sample示例项目,其中的Spring Boot工程,可以直接启动。可以在该项目上进行开发,也可以将现有项目改造生成执行器项目。
1.2. 初始化数据库
数据库脚本在doc/db目录下:
生成8张表。
| 表名 | 作用 |
|---|---|
| xxl_job_group | 执行器信息表,维护任务执行器信息 |
| xxl_job_info | 调度扩展信息表:用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等 |
| xxl_job_lock | 任务调度锁表 |
| xxl_job_log | 调度日志表:用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等 |
| xxl_job_log_report | 调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到 |
| xxl_job_logglue | 任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能 |
| xxl_job_registry | 执行器注册表,维护在线的执行器和调度中心机器地址信息 |
| xxl_job_user | 系统用户表 |
表初始化好以后,就可以配置代码工程了。这里先说一下总体概念。
xxl-job的调度器和业务执行是独立的。调度器(调度线程)决定任务的调度,并且通过HTTP的方式调用执行器接口执行任务。
所以在这里需要先配置至少一个调度中心,运行起来,也可以集群部署。然后再配置至少一个执行器,运行起来,同样可以集群部署。
1.3. 配置调度中心
调度中心是任务的指挥中心,可以有多个实例。
1.1.1. 修改配置
/xxl-job/xxl-job-admin/src/main/resources/application.properties
检查各项配置,主要是端口,数据库。
默认用户名admin,密码 123456。
可以显式加上一行配置:
xxl.job.login.username=admin
xxl.job.login.password=123456
1.1.2. 编译打包
如果通过jar包方式部署运行,需要先编译打包。在xxl-job-admin目录下执行命令:
mvn package -Dmaven.test.skip=true
1.1.3. 启动工程
运行调度中心,xxl-job\xxl-job-admin\target目录下
java -jar xxl-job-admin-2.2.1-SNAPSHOT.jar
或者直接运行Spring Boot根目录下的XxlJobAdminApplication启动类。调度器是带界面的,访问:http://127.0.0.1:8080/xxl-job-admin
主要功能:

为了保证可用性,调度中心可以做集群部署,需要满足几个条件:
· DB配置保持一致;
· 集群机器时钟保持一致(单机集群忽视);
· 建议:推荐通过nginx为调度中心集群做负载均衡,分配域名。调度中心访问、执行器回调配置、调用API服务等操作均通过该域名进行。
1.4. 创建执行器
执行器负责任务的具体执行,分配线程。执行器需要注册到调度中心,这样调度器才知道怎么选择执行器,或者说做路由。执行器的执行结果,也需要通过回调的方式通知调度器。
xxl-job提供了6个执行器的demo,非常地贴心,这里选用Spring Boot。

1.1.1. 修改配置
/xxl-job/xxl-job-executor-samples/xxl-job-executor-sample-springboot/src/main/resources/application.properties
主要是修改了日志目录,还有admin的端口号。
xxl.job.admin.addresses=http://127.0.0.1:7391/xxl-job-admin
xxl.job.executor.logpath=E:/dev_logs/xxl-job/jobhandler
配置类会在com.xxl.job.executor.core.config.XxlJobConfig用到。
1.1.1. 编译打包
如果通过jar包方式部署运行,需要先编译打包。
在xxl-job\xxl-job-executor-samples\xxl-job-executor-sample-springboot目录下:
mvn package -Dmaven.test.skip=true
如果这个目录无法打包,就在根目录下打包。
1.1.2. 启动工程
运行执行器,上述路径的target目录下:
java -jar xxl-job-admin-2.2.1-SNAPSHOT.jar
或者直接运行XxlJobExecutorApplication启动类。
可以做集群部署, 这两项配置要一致:
xxl.job.admin.addresses=
xxl.job.executor.appname=
1.1. 添加任务
指挥官有了,工人也有了,下面就可以派事情给工人做了,也就是创建任务。
登录调度中心,打开任务管理界面,新增任务。

1.1.1. 路由策略
路由策略指的是一个任务选择哪个执行器去执行,Quartz只能随机负载。当执行器做集群部署的时候才有意义。Xxl-job提供了丰富的路由策略,包括:
| 策略 | 参数值 | 详细含义 |
|---|---|---|
| 第一个 | FIRST | 固定选择第一个机器 |
| 最后一个 | LAST | 固定选择最后一个机器 |
| 轮询 | ROUND | 依次选择执行 |
| 随机 | RANDOM | 随机选择在线的机器 |
| 一致性HASH | CONSISTENT_HASH | 每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上 |
| 最不经常使用 | LEAST_FREQUENTLY_USED | 使用频率最低的机器优先被选举 |
| 最近最久未使用 | LEAST_RECENTLY_USED | 最久未使用的机器优先被选举 |
| 故障转移 | FAILOVER | 按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度 |
| 忙碌转移 | BUSYOVER | 按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度 |
| 分片广播 | SHARDING_BROADCAST | 广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务 |
1.1.2. 运行模式
在xxl-job中,不仅支持运行预先编写好的任务类,还可以直接输入代码或者脚本运行(上代码都不用审核了??)。
运行任务类,这种方式就叫做BEAN模式,需要指定任务类,这个任务类就叫做JobHandler,是在执行器端编写的。
运行代码或者脚本,叫做GLUE模式,支持Java、Shell、Python、PHP、Nodejs、PowerShell,这个时候代码是直接维护在调度器这边的。
1.1.3. 阻塞处理策略
阻塞处理策略,指的是任务的一次运行还没有结束的时候,下一次调度的时间又到了,这个时候怎么处理。
| 策略 | 参数值 | 详细含义 |
|---|---|---|
| 单机串行,默认 | SERIAL_EXECUTION | 调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行 |
| 丢弃后续调度 | DISCARD_LATER | 调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败 |
| 覆盖之前调度 | COVER_EARLY | 调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务 |
1、SERIAL_EXECUTION(单机串行,默认):对当前线程不做任何处理,并在当前线程的队列里增加一个执行任务(一次只执行一个任务)。
2、DISCARD_LATER(丢弃后续调度):如果当前线程阻塞,后续任务不再执行,直接返回失败(阻塞就不再执行了)。
3、COVER_EARLY(覆盖之前调度):创建一个移除原因,新建一个线程去执行后续任务(杀掉当前线程)。
1.1.4. 子任务
如果需要在本任务执行结束并且执行成功的时候触发另外一个任务,那么就可以把另外的任务作为本任务的子任务运行。
因为每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),只需要把JobId填上就可以了。
比如:下载对账文件的任务成功以后,开始解析文件入库。入库成功以后,开始对账。
这样,多个任务就实现了串行调度。
1.2. 任务操作

1. Xxl-job 任务详解
1.1. Spring Boot任务类型
com.xxl.job.executor.service.jobhandler.SampleXxlJob
开发步骤:
1、在Spring Bean实例中,开发Job方法,方式格式要求为 “public ReturnT<String> execute(String param)”
2、为Job方法添加注解 “@XxlJob(value=“自定义jobhandler名称”, init = “JobHandler初始化方法”, destroy = “JobHandler销毁方法”)”,注解value值对应的是调度中心新建任务的JobHandler属性的值。
3、执行日志:需要通过 "XxlJobLogger.log" 打印执行日志;
**demoJobHandler:**简单示例任务,任务内部模拟耗时任务逻辑,用户可在线体验Rolling Log等功能;
**shardingJobHandler:**分片示例任务,任务内部模拟处理分片参数,可参考熟悉分片任务;
**commandJobHandler:**命令行任务;
**httpJobHandler:**通用HTTP任务Handler;业务方只需要提供HTTP链接等信息即可,不限制语言、平台。
/**
* 分片广播任务
* 直接由路由策略--> 分片广播
* @author xuxueli 2017-07-25 20:56:50
* 如果想实现分片策略可以在此业务类中进行实现逻辑
*/
public class ShardingJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
// 分片参数
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal());
// 业务逻辑
for (int i = 0; i < shardingVO.getTotal(); i++) {
if (i == shardingVO.getIndex()) {
XxlJobLogger.log("第 {} 片, 命中分片开始处理", i);
} else {
XxlJobLogger.log("第 {} 片, 忽略", i);
}
}
return SUCCESS;
}
}
/**
* 命令行任务
*
* @author xuxueli 2018-09-16 03:48:34
*/
public class CommandJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
String command = param;
int exitValue = -1;
BufferedReader bufferedReader = null;
try {
// command process
Process process = Runtime.getRuntime().exec(command);
BufferedInputStream bufferedInputStream = new BufferedInputStream(process.getInputStream());
bufferedReader = new BufferedReader(new InputStreamReader(bufferedInputStream));
// command log
String line;
while ((line = bufferedReader.readLine()) != null) {
XxlJobLogger.log(line);
}
// command exit
process.waitFor();
exitValue = process.exitValue();
} catch (Exception e) {
XxlJobLogger.log(e);
} finally {
if (bufferedReader != null) {
bufferedReader.close();
}
}
if (exitValue == 0) {
return IJobHandler.SUCCESS;
} else {
return new ReturnT<String>(IJobHandler.FAIL.getCode(), "command exit value("+exitValue+") is failed");
}
}
}
/**
* 跨平台Http任务
*
* @author xuxueli 2018-09-16 03:48:34
*/
public class HttpJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
// param parse
if (param==null || param.trim().length()==0) {
XxlJobLogger.log("param["+ param +"] invalid.");
return ReturnT.FAIL;
}
String[] httpParams = param.split("\n");
String url = null;
String method = null;
String data = null;
for (String httpParam: httpParams) {
if (httpParam.startsWith("url:")) {
url = httpParam.substring(httpParam.indexOf("url:") + 4).trim();
}
if (httpParam.startsWith("method:")) {
method = httpParam.substring(httpParam.indexOf("method:") + 7).trim().toUpperCase();
}
if (httpParam.startsWith("data:")) {
data = httpParam.substring(httpParam.indexOf("data:") + 5).trim();
}
}
// param valid
if (url==null || url.trim().length()==0) {
XxlJobLogger.log("url["+ url +"] invalid.");
return ReturnT.FAIL;
}
if (method==null || !Arrays.asList("GET", "POST").contains(method)) {
XxlJobLogger.log("method["+ method +"] invalid.");
return ReturnT.FAIL;
}
// request
HttpURLConnection connection = null;
BufferedReader bufferedReader = null;
try {
// connection
URL realUrl = new URL(url);
connection = (HttpURLConnection) realUrl.openConnection();
// connection setting
connection.setRequestMethod(method);
connection.setDoOutput(true);
connection.setDoInput(true);
connection.setUseCaches(false);
connection.setReadTimeout(5 * 1000);
connection.setConnectTimeout(3 * 1000);
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("Content-Type", "application/json;charset=UTF-8");
connection.setRequestProperty("Accept-Charset", "application/json;charset=UTF-8");
// do connection
connection.connect();
// data
if (data!=null && data.trim().length()>0) {
DataOutputStream dataOutputStream = new DataOutputStream(connection.getOutputStream());
dataOutputStream.write(data.getBytes("UTF-8"));
dataOutputStream.flush();
dataOutputStream.close();
}
// valid StatusCode
int statusCode = connection.getResponseCode();
if (statusCode != 200) {
throw new RuntimeException("Http Request StatusCode(" + statusCode + ") Invalid.");
}
// result
bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream(), "UTF-8"));
StringBuilder result = new StringBuilder();
String line;
while ((line = bufferedReader.readLine()) != null) {
result.append(line);
}
String responseMsg = result.toString();
XxlJobLogger.log(responseMsg);
return ReturnT.SUCCESS;
} catch (Exception e) {
XxlJobLogger.log(e);
return ReturnT.FAIL;
} finally {
try {
if (bufferedReader != null) {
bufferedReader.close();
}
if (connection != null) {
connection.disconnect();
}
} catch (Exception e2) {
XxlJobLogger.log(e2);
}
}
}
}
2. xxl-job架构设计
xxl-job跟Quartz特性和部署方式的不同,本质上是因为架构设计有着很大的区别。
1.1. 设计思想
1.1.1. 调度与任务解耦
在Quartz中,调度逻辑和任务代码是耦合在一起的。
而xxl-job把调度的动作抽象和独立出来,形成“调度中心”公共平台。调度中心只负责发起调度请求,平台自身并不承担业务逻辑。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性。
1.1.2. 全异步化& 轻量级
全异步化设计:XXL-JOB系统中业务逻辑在远程执行器执行,触发流程全异步化设计。相比直接在调度中心内部执行业务逻辑,极大的降低了调度线程占用时间;
异步调度:调度中心每次任务触发时仅发送一次调度请求,该调度请求首先推送“异步调度队列”,然后异步推送给远程执行器。
异步执行:执行器会将请求存入“异步执行队列”并且立即响应调度中心,异步运行。
轻量级设计:XXL-JOB调度中心中每个JOB逻辑非常 “轻”,在全异步化的基础上,单个JOB一次运行平均耗时基本在 “10ms” 之内(基本为一次请求的网络开销);因此,可以保证使用有限的线程支撑大量的JOB并发运行;
得益于上述两点优化,理论上默认配置下的调度中心,单机能够支撑5000 任务并发运行稳定运行;
实际场景中,由于调度中心与执行器网络ping延迟不同、DB读写耗时不同、任务调度密集程度不同,会导致任务量上限会上下波动。
如若需要支撑更多的任务量,可以通过调大调度线程数、降低调度中心与执行器ping延迟和提升机器配置几种方式优化。
1.1.3. 均衡调度
调度中心在集群部署时会自动进行任务平均分配,触发组件每次获取与线程池数量(调度中心支持自定义调度线程池大小)相关数量的任务,避免大量任务集中在单个调度中心集群节点。
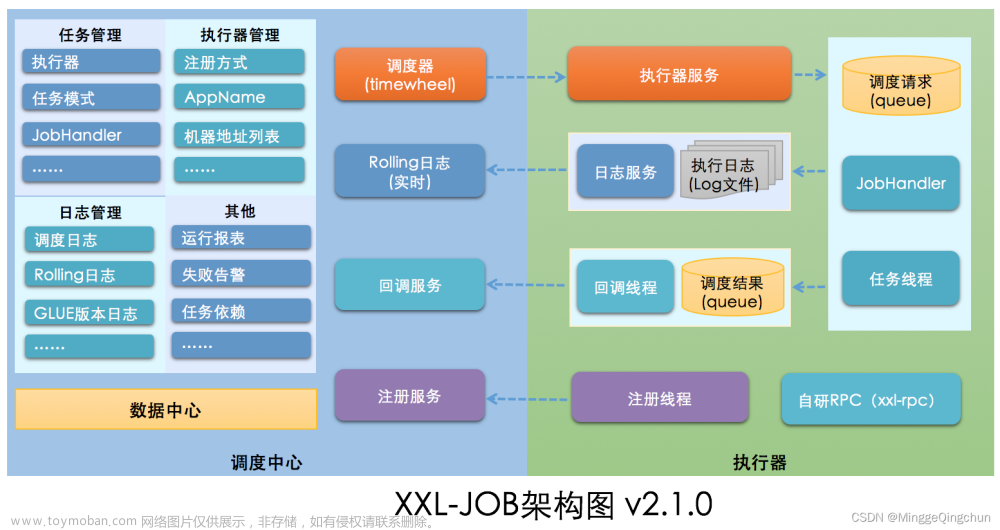
1.2. 系统组成

整体上分为两个模块:
1.1.4. 调度模块(调度中心)
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
调度中心支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
1.1.5. 执行模块(执行器)
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等。
从整体来看,xxl-job架构依赖较少,功能强大,简约而不简单,方便部署,易于使用。
3. xxl-job原理分析
源码部分
当执行器集群部署的时候,调度器需要为任务执行选择执行器。所以,执行器在启动的时候,必须先注册到调度中心,保存在数据库。
1.1. 执行器启动与注册


https://blog.csdn.net/oushitian/article/details/87938682
https://blog.csdn.net/RabbitInTheGrass/article/details/106918236
执行器的注册与发现有两种方式:
1、一种是执行器启动的时候,主动到调度中心注册,并定时发送心跳,保持续约。执行器正常关闭时,也主动告知调度中心注销掉。这种方式叫做主动注册。(调度中心类似于注册中心eureka,nacos,rocketmq的namesrv)
2、如果执行器宕机或者网络出问题了,调度中心就不知道执行器的情况,如果把任务路由给一个不可用的执行器执行,就会导致任务执行失败。
所以,调度中心本身也需要不断地对执行器进行探活。调度中心会启动一个专门的后台线程,定时调用执行器接口,如果发现异常就下线掉。
下面从执行器的源码去验证一下。
首先,一个Spring Boot的项目启动从哪里入手?
从配置类XxlJobConfig出发,这里用到了配置的参数。
配置类定义了一个XxlJobSpringExecutor,会在启动扫描配置类的时候创建执行器。XxlJobSpringExecutor继承了XxlJobExecutor。
父类实现了SmartInitializingSingleton接口,在对象初始化的时候会调用afterSingletonsInstantiated()方法,这里面父类的start()方法。
这里面做了几件事:
// 初始化日志路径
XxlJobFileAppender.initLogPath(logPath);
// 创建调度器的客户端
initAdminBizList(adminAddresses, accessToken);
// 初始化日志清理线程
JobLogFileCleanThread.getInstance().start(logRetentionDays);
// 初始化Trigger回调线程
TriggerCallbackThread.getInstance().start();
// 初始化执行器服务器
initEmbedServer(address, ip, port, appname, accessToken);

initAdminBizList创建调度器客户端,是执行器用来连接调度器的。
Trigger回调线程用来处理任务执行完毕后的回调,为什么需要回调。
从initEmbedServer方法进入执行器的创建,到embedServer.start。叫做embedServer是因为Spring Boot里面是用的内置的Tomcat启动的。
embedServer = new EmbedServer();
embedServer.start(address, port, appname, accessToken);

在这个start方法里面,最后有一个thread.start(),也就是调用了线程的run方法。线程是上面new出来的。在run方法里面,创建了一个名字叫bizThreadPool 的ThreadPoolExecutor,也就是业务线程的线程池。
ThreadPoolExecutor bizThreadPool = new ThreadPoolExecutor(
然后启动了一个Netty包的ServerBootstrap,然后启动服务器。
ServerBootstrap bootstrap = new ServerBootstrap();
在这里面要把执行器注册到调度中心。
startRegistry(appname, address);

到了ExecutorRegistryThread,在start方法里面最后启动了这个线程:
ExecutorRegistryThread.getInstance().start(appname, address);

registryThread.start();也就是执行了这个创建的线程的run方法。
首先拿到调度器的列表,它有可能是集群部署的。
for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {

然后挨个注册上去,调用的是AdminBizClient的registry方法(这个类是core包里面的):
public ReturnT<String> registry(RegistryParam registryParam) {
return XxlJobRemotingUtil.postBody(addressUrl + "api/registry", accessToken, timeout, registryParam, String.class);
}

调用了HTTP的接口,实际地址是:
http://127.0.0.1:7391/xxl-job-admin/ api/registry
在旧的版本中用的是XXL-RPC,后来改成了Restful的API。
请求的是com.xxl.job.admin.controller.JobApiController的api方法,这里有一个分支:
if ("registry".equals(uri)) {
RegistryParam registryParam = GsonTool.fromJson(data, RegistryParam.class);
return adminBiz.registry(registryParam);
}
这个时候会调用到AdminBizImpl的registryUpdate方法:

//注册中心也是类似这么设计的
int ret = xxlJobRegistryDao.registryUpdate(registryParam.getRegistryGroup(), registryParam.getRegistryKey(), registryParam.getRegistryValue(), new Date());
//小于1说明记录不存在,插入记录
xxlJobRegistryDao.registrySave(registryParam.getRegistryGroup(), registryParam.getRegistryKey(), registryParam.getRegistryValue(), new Date());
这个接口方法是没有实现类的——其实就是MyBatis的Mapper,把执行器保存到数据库。
XxlJobRegistryMapper.xml
<update id="registryUpdate" >
UPDATE xxl_job_registry SET `update_time` = #{updateTime}
WHERE `registry_group` = #{registryGroup}
AND `registry_key` = #{registryKey}
AND `registry_value` = #{registryValue}
</update>
<insert id="registrySave" >
INSERT INTO xxl_job_registry( `registry_group` , `registry_key` , `registry_value`, `update_time`)
VALUES( #{registryGroup} , #{registryKey} , #{registryValue}, #{updateTime})
</insert>
后台线程探活这一块,在调度器的代码中:
JobRegistryMonitorHelper.getInstance().start();
1.2. 调度器启动与任务执行(调度中心如何启动的)
执行器启动好以后,工人就准备干活了,接下来就看一下指挥官上岗以后是怎么指挥工人的。实际上是先启动调度器再启动执行器,但是因为调度的流程涉及到执行器,所以先分析执行器。
下面看看调度器是如何启动的,任务是如何得到执行的。
1.1.1. 从配置类入手
Spring Boot的工程,一样从配置类XxlJobAdminConfig入手。它实现了InitializingBean接口,会在初始化的时候调用afterPropertiesSet方法:
public void afterPropertiesSet() throws Exception {
adminConfig = this;
xxlJobScheduler = new XxlJobScheduler();
xxlJobScheduler.init();
}

init方法里面做了几件事情:
// 任务注册监控器
JobRegistryMonitorHelper.getInstance().start();
// 任务调度失败的监控器,失败重试,失败邮件发送
JobFailMonitorHelper.getInstance().start();
// 任务结果丢失处理
JobLosedMonitorHelper.getInstance().start();
// trigger pool启动
JobTriggerPoolHelper.toStart();
// log report启动
JobLogReportHelper.getInstance().start();
// start-schedule
JobScheduleHelper.getInstance().start();
JobRegistryMonitorHelper做的事情是不停地更新注册表,把超时的执行器剔除。每隔30秒执行一次:
TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
JobTriggerPoolHelper创建了两个线程池,一个快的线程池,一个慢的线程池,作用后面就会讲到。
这里主要关注的是调度器(指挥官)如何启动的,进入JobScheduleHelper的start方法,这段方法总体上看起来是这样的:
public void start(){
// schedule thread
scheduleThread = new Thread(…...);
scheduleThread.setDaemon(true);
scheduleThread.setName("xxl-job, admin JobScheduleHelper#scheduleThread");
scheduleThread.start();
// ring thread
ringThread = new Thread(…...);
ringThread.setDaemon(true);
ringThread.setName("xxl-job, admin JobScheduleHelper#ringThread");
ringThread.start();
}
也就是创建并且启动了两个后台线程,一个是调度线程,一个是时间轮线程。先从第一个线程开始说起。
1.1.2. 调度器线程
这里创建了一个scheduleThread线程,后面调用了start方法,也就是会进入run方法。
scheduleThread的run方法中,先随机睡眠4-5秒,为什么?为了防止执行器集中启动出现过多的资源竞争。
TimeUnit.MILLISECONDS.sleep(5000 - System.currentTimeMillis()%1000 );
然后计算预读取的任务数,这里默认是6000个。
int preReadCount = (XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax() + XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax()) * 20;
后面是一个while循环,也就是调度器重复不断地在做的事情。
1.1.3. 获取任务锁
第一步是获取数据库的排他锁,因为所有的节点连接到的数据库是同一个实例,所以这里是一个分布式环境的锁。也就是后面的过程是互斥的,如果有多个调度器的服务,同一时间只能有一个调度器在获取任务信息:
preparedStatement = conn.prepareStatement( "select * from xxl_job_lock where lock_name = 'schedule_lock' for update" );
获取的是job_lock表的lock_name=schedule_lock这一行数据的行锁。
如果加锁没有成功,说明其他调度中心在加载任务了,只能等其他节点提交事务或者回滚事务,释放锁以后才能获取锁。
获取锁成功后查询任务:
<select id="scheduleJobQuery" parameterType="java.util.HashMap" resultMap="XxlJobInfo">
SELECT <include refid="Base_Column_List" />
FROM xxl_job_info AS t
WHERE t.trigger_status = 1
and t.trigger_next_time <![CDATA[ <= ]]> #{maxNextTime}
ORDER BY id ASC
LIMIT #{pagesize}
</select>
这个SQL的含义:从任务表查询状态是1,并且下次触发时间小于{maxNextTime}的任务;{maxNextTime}=nowTime(当前时间) + PRE_READ_MS(5秒),也就是说查询5秒钟之内需要触发的任务:

1.1.4. 调度任务
这里根据任务的触发时间分成了三种情况。
这里假设任务的下次触发时间(TriggerNextTime)是9点0分30秒,2秒钟触发一次。

第一种情况就是当前时间已经是9点0分35秒以后了。
如果nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS,也就是触发时间已经过期5秒以上,那就不能调度了(misfire了),让它到下次触发的时间再跑,这里只需要更新下次触发时间。
什么时候会超时?比如你的查询非常慢,或者你查询到等待触发的任务以后,debug停在上面很久才走到时间判断。
第二种情况(正常情况):nowTime > jobInfo.getTriggerNextTime(),已经过了触发时间,但是没有超过5秒,时间是9点0分30秒到9点0分35秒之间。
这里要做的事情有四步:
1、触发任务
2、更新下次触发时间
一次触发完成之后,来一次预读,看看再下次的触发时间是不是满足:
nowTime + PRE_READ_MS > jobInfo.getTriggerNextTime()
下次触发时间是9点0分32秒,现在时间大于9点0分27秒(距离下次触发时间不足5秒了):
3、丢入时间轮
4、触发完了再把时间更新为下次更新时间
这里重点有两个,触发的时候做了什么。丢入时间轮做了什么。
第三种情况:还没到9点0分30秒。
1、丢入时间轮
2、刷新一下下次触发时间,因为还没触发,实际上时间没变
所以,这里要重点关注一下,任务触发的时候,是怎么触发的。丢入时间轮,又是一个什么操作。
1.1.5. 任务触发

从JobTriggerPoolHelper的trigger方法进入,又到了JobTriggerPoolHelper的addTrigger方法。
这里设计了两个线程池:fastTriggerPool和slowTriggerPool,如果1分钟内过期了10次,就使用慢的线程池。
ThreadPoolExecutor triggerPool_ = fastTriggerPool;
AtomicInteger jobTimeoutCount = jobTimeoutCountMap.get(jobId);
if (jobTimeoutCount!=null && jobTimeoutCount.get() > 10) { // job-timeout 10 times in 1 min
triggerPool_ = slowTriggerPool;
}
这里相当于做了一个线程池隔离,即使有很多慢的任务,也只能把慢任务的线程池耗光(秒啊!)。
什么样的任务会使用慢的线程池来执行呢?JobTriggerPoolHelper中addTrigger的末尾:如果这次执行超过了500ms,就给它标记一下,超过10次,它就要被丢到下等舱了。
if (cost > 500) { // ob-timeout threshold 500ms
AtomicInteger timeoutCount = jobTimeoutCountMap.putIfAbsent(jobId, new AtomicInteger(1));
if (timeoutCount != null) {
timeoutCount.incrementAndGet();
}
}
线程池选择好以后,execute一下,也就是分配线程来执行触发任务。
进入XxlJobTrigger的trigger方法:
XxlJobTrigger.trigger(jobId, triggerType, failRetryCount, executorShardingParam, executorParam, addressList);
在XxlJobTrigger的trigger方法中,先拿到任务信息,如果方法参数failRetryCount>0,就用参数值,否则用Job定义的failRetryCount。这里传进来的是-1。
XxlJobInfo jobInfo = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().loadById(jobId);
拿到失败重试次数和组别:
int finalFailRetryCount = failRetryCount>=0?failRetryCount:jobInfo.getExecutorFailRetryCount();
XxlJobGroup group = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().load(jobInfo.getJobGroup());
先不考虑广播分片的情况,分片的原理后面再分析。直接走到末尾的else,processTrigger:
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, shardingParam[0], shardingParam[1]);

前面是获取一些参数,然后记录日志,初始化Trigger参数。
然后获取路由,把结果放入routeAddressResult。如果是广播分片,所有的节点都要参与负载,否则要根据策略获取执行器地址。
不同的路由策略,获取路由的方式也不一样,这里是典型的策略模式:
routeAddressResult = executorRouteStrategyEnum.getRouter().route(triggerParam, group.getRegistryList());

回顾一下:
| 路由参数 | 翻译 | 详细含义 |
|---|---|---|
| FIRST | 第一个 | 固定选择第一个机器 |
| LAST | 最后一个 | 固定选择最后一个机器 |
| ROUND | 轮询 | 依次选择执行 |
| RANDOM | 随机 | 随机选择在线的机器 |
| CONSISTENT_HASH | 一致性HASH | 每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上 |
| LEAST_FREQUENTLY_USED | LRU最不经常使用 | 使用频率最低的机器优先被选举 |
| LEAST_RECENTLY_USED | LRU最近最久未使用 | 最久未使用的机器优先被选举 |
| FAILOVER | 故障转移 | 按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度 |
| BUSYOVER | 忙碌转移 | 按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度 |
| SHARDING_BROADCAST | 分片广播 |
广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务 |
如果没有启动执行器,那就拿不到执行器地址。

拿到执行器地址以后,runExecutor触发远程的执行器:
triggerResult = runExecutor(triggerParam, address);



这里调用的是ExecutorBizClient的run方法:
public ReturnT<String> run(TriggerParam triggerParam) {
return XxlJobRemotingUtil.postBody(addressUrl + "run", accessToken, timeout, triggerParam, String.class);
}

这里就调用了执行器的远程接口(http://192.168.44.1:9999/run),执行器接收到调用请求怎么处理后面再说。
参数内容:
TriggerParam{jobId=2, executorHandler='', executorParams='', executorBlockStrategy='SERIAL_EXECUTION', executorTimeout=0, logId=10337, logDateTime=1601783382002, glueType='GLUE_GROOVY', glueSource='package com.xxl.job.service.handler;
import com.xxl.job.core.log.XxlJobLogger;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.IJobHandler;
public class DemoGlueJobHandler extends IJobHandler {
@Override
public ReturnT<String> execute(String param) throws Exception {
XxlJobLogger.log("qingshan job, Hello World.");
return ReturnT.SUCCESS;
}
}
', glueUpdatetime=1601359733000, broadcastIndex=0, broadcastTotal=1}
回顾一下,这里说的是第二种情况:

一共四步,第一步结束了:
1、触发任务
2、更新下次触发时间
3、丢入时间轮
4、触发完了再把时间更新为下次更新时间
第二步和第四步非常简单,都是操作数据库。
第三步,丢入时间轮,什么是时间轮?为什么要丢入时间轮?
1.1.6. 时间轮
要回答这个问题,先从Java中最原始的任务调度的方法说起。
给你一批任务(假设有1000个任务),都是不同的时间执行的,时间精确到秒,你怎么实现对所有的任务的调度?
第一种思路是启动一个线程,每秒钟对所有的任务进行遍历,找出执行时间跟当前时间匹配的,执行它。如果任务数量太大,遍历和比较所有任务会比较浪费时间。

第二个思路,把这些任务进行排序,执行时间近(先触发)的放在前面。

用Java代码怎么实现呢?
JDK包里面自带了一个Timer工具类(java.util包下),可以实现延时任务(例如30分钟以后触发),也可以实现周期性任务(例如每1小时触发一次)。
它的本质是一个优先队列(TaskQueue),和一个执行任务的线程(TimerThread)。
public class Timer {
private final TaskQueue queue = new TaskQueue();
private final TimerThread thread = new TimerThread(queue);
public Timer(String name, boolean isDaemon) {
thread.setName(name);
thread.setDaemon(isDaemon);
thread.start();
}
}
在这个优先队列中,最先需要执行的任务排在优先队列的第一个。然后 TimerThread 不断地拿第一个任务的执行时间和当前时间做对比。如果时间到了先看看这个任务是不是周期性执行的任务,如果是则修改当前任务时间为下次执行的时间,如果不是周期性任务则将任务从优先队列中移除。最后执行任务。
但是Timer是单线程的,在很多场景下不能满足业务需求。
在JDK1.5之后,引入了一个支持多线程的任务调度工具ScheduledThreadPoolExecutor用来替代TImer,它是几种常用的线程池之一。看看构造函数,里面是一个延迟队列DelayedWorkQueue,也是一个优先队列。
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
优先队列的插入和删除的时间复杂度是O(logn),当数据量大的时候,频繁的入堆出堆性能不是很好。
这里先考虑对所有的任务进行分组,把相同执行时刻的任务放在一起。比如这里,数组里面的一个下标就代表1秒钟。它就会变成一个数组加链表的数据结构。分组以后遍历和比较的时间会减少一些。

但是还是有问题,如果任务数量非常大,而且时间都不一样,或者有执行时间非常遥远的任务,那这个数组长度是不是要非常地长?比如有个任务2个月之后执行,从现在开始计算,它的下标是5253120。
所以长度肯定不能是无限的,只能是固定长度的。比如固定长度是60,一个格子代表1秒(现在叫做一个bucket槽),一圈可以表示60秒。遍历的线程只要一个格子一个格子的获取任务,并且执行就OK了。
固定长度的数组怎么用来表示超出最大长度的时间呢?可以用循环数组。
比如一个循环数组长度60,可以表示60秒。60秒以后执行的任务怎么放进去?只要除以60,用得到的余数,放到对应的格子就OK了。比如90%60=30,它放在第30个格子。这里就有了轮次的概念,第90秒的任务是第二轮的时候才执行。

这时候,时间轮的概念已经出来了。
如果任务数量太多,相同时刻执行的任务很多,会导致链表变得非常长。这里可以进一步对这个时间轮做一个改造,做一个多层的时间轮。
比如:最内层60个格子,每个格子1秒;外层60个格子,每个格子1分;再外层24个格子,每个格子1小时。最内层走一圈,外层走一格。这时候时间轮就跟时钟更像了。随着时间流动,任务会降级,外层的任务会慢慢地向内层移动。
时间轮任务插入和删除时间复杂度都为O(1),应用范围非常广泛,更适合任务数很大的延时场景。Dubbo、Netty、Kafka中都有实现。
xxl-job中的时间轮是怎么实现的?回到JobScheduleHelper的start方法:
放入时间轮有这么两步:
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
pushTimeRing(ringSecond, jobInfo.getId());
ringSecond是0-59的秒数值(millionSeconds是毫秒数)。
把它想象成一个表盘的秒针指数。放入时间轮的这一段代码:
// push async ring
List<Integer> ringItemData = ringData.get(ringSecond);
if (ringItemData == null) {
ringItemData = new ArrayList<Integer>();
ringData.put(ringSecond, ringItemData);
}
ringItemData.add(jobId);
这个ringData是一个ConcurrentHashMap,key是Integer,放的是ringSecond(0-59)。Value是List<Integer>,里面放的是jobId。
到这里为止,JobScheduleHelper的start方法的前一半就分析完了。接下来是ringThread线程,看看时间轮的任务是怎么拿出来执行的。
1.1.7. 时间轮线程ringThread

在初始化的时候先对齐秒数:休眠当前秒数模以1000的余数,意思是下一个正秒运行。
TimeUnit.MILLISECONDS.sleep(1000 - System.currentTimeMillis()%1000 );
然后进入一个while循环。获取当前秒数:
// 避免处理耗时太长,跨过刻度,向前校验一个刻度;
int nowSecond = Calendar.getInstance().get(Calendar.SECOND);
注释:根据当前秒数刻度和前一个刻度进行时间轮的任务获取
for (int i = 0; i < 2; i++) {
List<Integer> tmpData = ringData.remove( (nowSecond+60-i)%60 );
if (tmpData != null) {
ringItemData.addAll(tmpData);
}
}
(nowSecond+60-k)%60跟nowSecond-k的结果一模一样,也就是当前秒数,和前一秒。比如当前秒数是40,就获取40和39的任务。从ringData里面拿出来,放进ringItemData,这里面存的是这两秒需要触发的所有任务的jobId。
接下来就是触发任务了。
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null, null);
又调用了JobTriggerPoolHelper的addTrigger。
在XxlJobTrigger的trigger方法中,调用了processTrigger,又调用了runExecutor
runResult = executorBiz.run(triggerParam);
这里实现类是ExecutorBizClient,发起了一个HTTP的请求。
public ReturnT<String> run(TriggerParam triggerParam) {
return XxlJobRemotingUtil.postBody(addressUrl + "run", accessToken, timeout, triggerParam, String.class);
}
最终的URL地址是执行器的9999端口:http://192.168.44.1:9999/run
跟上面一样。也就是说,放进时间轮等待触发的任务,也会通过远程请求,让执行器执行任务。
1.1.8. 执行器处理远程调用,回调
在业务实例这边,执行器启动9999端口监听的时候,在EmbedHttpServerHandler的channelRead0方法中,会创建线程池bizThreadPool,process方法处理URI的访问。
if ("/run".equals(uri)) {
TriggerParam triggerParam = GsonTool.fromJson(requestData, TriggerParam.class);
return executorBiz.run(triggerParam);
}
这个时候调用的是core包的ExecutorBizImpl的run方法。
第一步,先拿到任务的JobThread(表示有没有线程正在执行这个JobId的任务):
JobThread jobThread = XxlJobExecutor.loadJobThread(triggerParam.getJobId());
IJobHandler jobHandler = jobThread!=null?jobThread.getHandler():null;
如果有线程,再拿到jobHandler。什么是jobHandler?
在SpringBoot的工程里面,jobHandler就是加了@XxlJob注解的任务方法(一个任务一个方法)。其他的四个框架中的使用,需要自己编写Handler(任务类)继承IJobHandler。这个IjobHandler接口意思跟Quartz里面的Job接口是一样的,这里面必须要覆盖父类的execute方法。
中间是对于jobThread和jobHandler的判断。对于bean、GROOVY、其他脚本类型的任务,处理不一样。基本原则就是必须要有一个Handler,而且跟之前的Handler必须相同。
如果当前任务正在运行(根据JobId能够找到JobThread),需要根据配置的策略采取不同的措施,比如:
1、DISCARD_LATER(丢弃后续调度):如果当前线程阻塞,后续任务不再执行,直接返回失败(阻塞就不再执行了)。
if (jobThread.isRunningOrHasQueue()) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());
}
2、COVER_EARLY(覆盖之前调度):创建一个移除原因,新建一个线程去执行后续任务(杀掉当前线程)。
if (jobThread.isRunningOrHasQueue()) {
removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();
jobThread = null;
}
3、SERIAL_EXECUTION(单机串行,默认):对当前线程不做任何处理,并在当前线程的队列里增加一个执行任务(一次只执行一个任务)。
最后,调用JobThread的pushTriggerQueue方法把Trigger放入队列。
ReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);
这个队列是什么?TriggerQueue是什么?LinkedBlockingQueue。
执行器中单个任务处理线程一次只能执行一个任务。
JobThread在创建的时候就会启动,启动就会进入run方法的死循环,不断地从队列里面拿任务:
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
最终调用到Handler(任务类)的execute方法:
return handler.execute(triggerParamTmp.getExecutorParams());
在finally方法中调用了回调方法,告知调度器执行结果:
if(triggerParam != null) {
// callback handler info
if (!toStop) {
// commonm
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), executeResult));
} else {
// is killed
ReturnT<String> stopResult = new ReturnT<String>(ReturnT.FAIL_CODE, stopReason + " [job running, killed]");
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), stopResult));
}
}
放入一个队列。在TriggerCallbackThread的后台线程的run方法里面,调用doCallback方法,连接到调度器,写入调度结果。


总结一下整体调度流程:
1、调度中心获取任务锁,查询任务,根据情况触发或者放入时间轮
2、触发任务需要先获取路由地址,然后调用执行器接口
3、执行器接收到调用请求,通过JobThread执行任务,并且回调(callback)调度器的接口
1.3. 任务分片原理
XxlJobTrigger的trigger方法:
int[] shardingParam = null;
if (executorShardingParam!=null){
String[] shardingArr = executorShardingParam.split("/");
if (shardingArr.length==2 && isNumeric(shardingArr[0]) && isNumeric(shardingArr[1])) {
shardingParam = new int[2];
shardingParam[0] = Integer.valueOf(shardingArr[0]);
shardingParam[1] = Integer.valueOf(shardingArr[1]);
}
}
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST==ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null)
&& group.getRegistryList()!=null && !group.getRegistryList().isEmpty()
&& shardingParam==null) {
for (int i = 0; i < group.getRegistryList().size(); i++) {
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, i, group.getRegistryList().size());
}
}
然后拿到分片参数:sharding param。这个sharding param大家还记得是什么么?
最好是设计一个跟业务无关的分片字段,加上索引用它来获取数据的分片信息。
用/来分割。
如果只有两个,并且都是数字,把他们转换为整形。
如果是广播任务,则在所有节点上processTrigger。
1.4. 手动触发一次任务
com.xxl.job.admin.controller.JobInfoController
@RequestMapping("/trigger")
@ResponseBody
//@PermissionLimit(limit = false)
public ReturnT<String> triggerJob(int id, String executorParam, String addressList) {
// force cover job param
if (executorParam == null) {
executorParam = "";
}
JobTriggerPoolHelper.trigger(id, TriggerTypeEnum.MANUAL, -1, null, executorParam, addressList);
return ReturnT.SUCCESS;
}
之后就跟调度器自动触发任务的流程一样了。
1.5. 任务H A & Failover
https://blog.csdn.net/Royal_lr/article/details/100113760
这里要解决两个关键的问题。第一个,调度器怎么知道任务执行失败了。第二个,执行失败以后,怎么处理。
XxlJobTrigger的processTrigger方法:
routeAddressResult = executorRouteStrategyEnum.getRouter().route(triggerParam, group.getRegistryList());
 文章来源:https://www.toymoban.com/news/detail-838169.html
文章来源:https://www.toymoban.com/news/detail-838169.html
4. xxl-job二次开发
https://blog.csdn.net/m0_37527542/article/details/104468785文章来源地址https://www.toymoban.com/news/detail-838169.html
到了这里,关于分布式定时任务调度xxl-job的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!