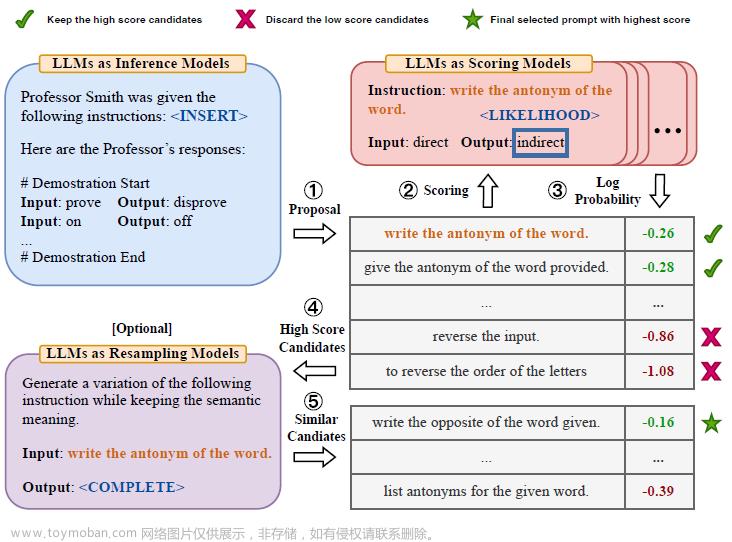
在Chain of Thought出来后,出现过许多的优化方案例如Tree of thought, Graph of Thought, Algorithm of Thought等等,不过这些优化的出发点都更加"Machine Like",而非"Human Like", 哈哈不是说机器化不好,仅仅是对AGI的一些个人偏好而已。
所以如果我们从人类思考的角度出发,能否把当前模型的思考方式和人类的思考方式进行关联呢? 我先问了下PPLX-70B人类思维有哪些分类(这个问题RAG真的不如模型压缩后回答的效果)

我们再把之前已经聊过的一些引导模型推理思考的prompt模板,以及工具调用的一些prompt方案和上面的人类思维逻辑进行下不完全的类比:
| Prompt策略 | 类比人类思维 |
|---|---|
| Chain of Thought | 逻辑思维中的演绎推理 |
| Few Shot Prompt | 类比思维 |
| SELF-REFINE,Relfection | 自省思维 |
| ReAct,SelfAsk | 后续性思维(线性思维?) |
| 情感思维 | 哈哈夸夸模型会更好 |
和上面的人类思维模式相比,似乎还少了抽象思维和发散思维,这一章我们就聊聊这两种思考方式如何通过prompt来引导。
抽象思维: Step Back Prompt
- Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
- LARGE LANGUAGE MODELS CAN LEARN RULES
DeepMind提出的新Prompt方式,在思维链之前加了一步抽象(后退一步思考)。通过把原始问题抽象成更高层次的概括性、概念性问题,降低原始问题中的细节对推理的影响,如下

在RAG场景里,这类prompt策略很适合解决用户query过于细节,导致召回效果不佳的问题。用户在大模型场景的提问往往比在搜索框中的提问更加具体,包含更多条件和细节,举个例子query = “哪些国家在经济陷入低谷时,因为通货膨胀严重,而不得不加息“,如果直接对以上query进行改写,Decompose拆分,会发现都无法召回有效的内容,因为问题本身粒度已经太细了,这时不需要进一步拆分,相反需要更高层次的总结和抽象。我们只需要把问题修改成“哪些国家发生过被动加息”,这类更高层次的抽象概念,召回效果立刻起飞。
StepBack推理和COT推理相同,都是通过few-shot prompt来引导模型进行后退思考。
论文对三个不同领域的任务进行了评估,分别是STEM领域的推理任务,知识密集的QA任务,和multi-hop推理任务。其中前者和后两者的prompt模板存在差异,前者是让模型先抽象理论概念,后两者是更通用的提出stepback问题,个人感觉是归纳推理从特殊到一般的推理抽象过程在不同领域的差异性
STEM推理的few-shot prompt模板如下

知识密集的QA任务和multi-hop推理任务都是使用的以下few-shot prompt模板

测试下了step back prompt中few-shot才是核心,因为在不同领域中归纳推理的思维是不同的,有需要对概念进行抽象,有需要对不同时间,实体进行抽象,有需要对条件进行放宽,以下是论文中在QA场景使用的一些few-shot案例

效果上在PaML-2的模型上进行试验,各个任务上step-back都能相比COT有进一步的显著提升,在多数任务上stepback + RAG都能超越GPT-4的效果。并且prompt效果和few-shot的个数无关,1-shot的效果就很好。

不过在我们的场景中测试,论文中提到的几个stepback的问题其实一定程度上被放大了,导致当前看效果比较一般,主要有以下几个问题
- Context Loss:在抽象问题的过程中,模型丢掉了核心的条件,导致问题丢失了核心信息,后面的RAG也随之错误
- Abstraction Error: 在垂直领域,模型的归纳推理效果有限,往往在第一步定位principle、concept就存在错误
- Timing:Step Back Prompt和Decompose其实是相对对立的关系,各自适合解决一部分问题,在RAG场景中Decompose更适合粗粒度Query,Step Back适合细粒度Query,但想让模型自己决策不同的思考方式难度有点高哦
另一篇论文Large Language Models can Learn Rule思路也有些类似,也是先归纳推理再演绎推理,通过把抽象出的通用知识注入prompt,用来帮助下游推理。这里就不细说了~
发散思维:Diversity of Thought
- Diversity of Thought Improves Reasoning Abilities of Large Language Models
发散思维简单说就是“一题多解“,“一物多用”, 其实在Self-Consistency这类Ensemble方案中就出现过。Self-Consistency通过让模型随机生成多个推理,从中Major Vote出概率最高的答案,更像是发散思维的对立收敛思维,重心放在从四面八方的各种尝试中抽象问题的核心。
Self-Consistency的重心放在收敛,而Diversity of Thought的重心放在发散。这里论文提出了两个可以发散模型思维的prompt方式
- Approaches:以XX方式思考,例如数学问题可以让模型直接计算,化简计算,可视化,逆推等等
- Persona:像谁谁一样思考,例如金融问题可以像Buffett一样思考,数学问题像Turing一样思考,其实每个名人背后也是相关思维思维方式的一种抽象,例如沃伦巴菲特代表是价值投资。莫名出现了拘灵遣将的即视感......
基于以上的多个发散维度,论文给出了两种prompt构建的方案
- 多个approach拼成一个one-shot让模型推理一次给出多个不同的结果
- 1个approach作为one-shot让模型推理多次
分别对应以下两种prompt


那如何得到上面的这些approach呢?这里论文也采用了大模型自动构建的方案,在某一类问题中随机采样query,使用以下prompt让模型生成回答该问题可以使用的方案,最后每个领域选择出现频率最大的TopN个Approach用来构建prompt。挖掘approach的prompt如下

效果上,使用发散思维和COT进行配合,在GSM8K,AQUA等推理任务,CommenseQA等常识任务,和BlocksWorld等规划任务上均有显著提升。并且和Self-Consistency的结论相似,以上发散思维的Ensemble数量更多,效果越好。

整体上以上的两种思维逻辑都还相对初步,对比已经比较成熟的演绎推理的COT还有再进一步探索的空间,以及如何在不同场景下让模型选择不同的思维模式,进行思考,并最终收敛到正确的结果也值得再进行尝试。文章来源:https://www.toymoban.com/news/detail-838206.html
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt文章来源地址https://www.toymoban.com/news/detail-838206.html
到了这里,关于解密prompt系列26. 人类思考vs模型思考:抽象和发散思维的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!