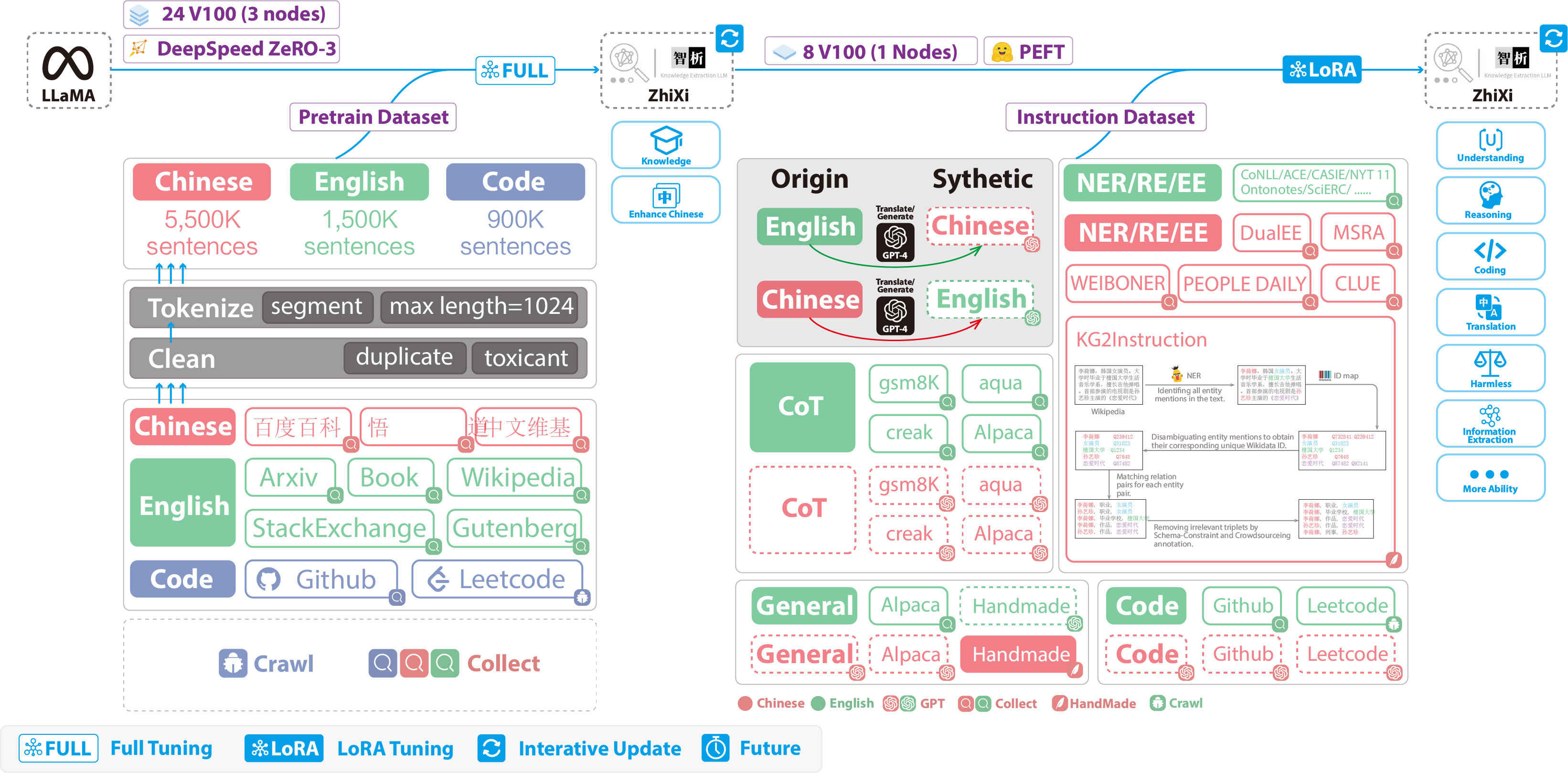
引言:探索语言模型的长上下文能力
近日,谷歌推出了Gemini Pro 1.5,将上下文窗口长度扩展到100万个tokens,目前领先世界。而其他语言模型也正在不断探索长上下文能力,也就是模型处理和理解超出其训练时所见上下文长度的能力。例如,一个模型可能在训练时只看到了每个输入中的4K tokens,但在实际应用中,我们希望它能够处理长达128K tokens的文档。这种能力对于多种应用场景至关重要,如多文档问答、代码库级别的代码理解、长历史对话建模,以及语言模型驱动的自主代理等。
然而,由于注意力机制的二次复杂度,将模型的上下文长度从4K扩展到128K看上去似乎是不切实际的。本文将介绍一种数据工程方法,通过在适当的数据混合上轻量级的持续预训练,来扩展语言模型的上下文长度至128K。
论文标题:Data Engineering for Scaling Language Models to 128K Context
公众号「夕小瑶科技说」后台回复“128K”获取论文PDF!
长上下文建模的重要性
1. 128K上下文窗口的新应用场景
随着语言模型上下文长度的增加至128K tokens,新的应用场景得以实现,这些场景在现有的模型范式中是难以完成的。例如,多文档问题回答、代码库级别的代码理解、长历史对话建模以及由语言模型驱动的自主代理等。这些应用场景的实现,不仅推动了语言模型的发展,也为人工智能领域带来了新的可能性。
2. 长上下文模型与Needle-in-a-Haystack测试
Needle-in-a-Haystack测试是一个用来检验模型是否能有效利用长上下文长度的测试平台。该测试要求模型在一个长达128K tokens的文档中,精确地复述一个被随机放置在任意位置的句子(即Needle)。目前,只有封闭源的前沿模型如GPT-4 128K展示了在此测试上的强大性能。而相比于开源领域的模型,我们的方法在Needle-in-a-Haystack测试中表现出色,缩小了与GPT-4 128K的差距。

上图是各模型的Needle-in-a-Haystack性能比较。x 轴表示文档(Haystack)的长度,从1K到128K不等;Y轴表示一个短句(Needle)在文档中的位置。例如,50% 表示Needle位于文档的中间。红色单元格表示语言模型无法确认Needle的信息,绿色单元格表示模型可以。白色虚线表示模型持续预训练(或对指令调整模型进行微调)上下文长度;因此其右侧区域表示长度泛化。大多数现有的开源模型在文档较长时都会出错。我们的训练方案在文档长度达到100K左右时表现出了很强的性能。
数据工程的关键作用
从数据角度看,我们的方法与现有工作的主要区别在于,我们认为数据对于扩展上下文长度至关重要。我们的数据混合集在三个方面不同于之前的工作:
-
持续预训练数据的长度。 我们使用 80K 的数据,而 Together 使用的是 32K,超过 32K 就无法泛化;
-
数据混合集。 我们使用的是 SlimPajama,它具有均衡的域,而 YaRN 使用的是仅书籍的 PG19;
-
长度上采样。 我们对长序列进行了上采样,而 LongLoRA 没有进行上采样。尽管这些细节非常微妙(例如,许多细节在以前的研究中只是作为一行被提及),但我们发现这些细节对大范围检索的性能至关重要。

实验设置:基础模型与数据集
1. 使用LLaMA-2作为基础模型
在本研究中,我们采用了LLaMA-2作为基础模型,具体使用了7B和13B两个版本。LLaMA-2模型是在现有的LLaMA模型基础上进行的改进,我们没有对模型架构进行重大更改,仅对RoPE的基数进行了调整,以适应更长的上下文长度。选择LLaMA-2作为基础模型的原因在于其在处理长上下文任务方面已经展现出了强大的性能,而我们的目标是通过持续预训练,进一步扩展其在128K长上下文中的能力。
2. SlimPajama数据集的选择与优势
为了持续预训练,我们选用了SlimPajama数据集。这个数据集是LLaMA预训练数据混合的开源再现版本,包含了来自CommonCrawl、C4、GitHub、Wikipedia、书籍、Arxiv和StackExchange的数据。SlimPajama数据集的优势在于其与LLaMA模型预训练时使用的数据分布非常接近,因此在持续预训练过程中,可以减少分布偏移的问题。此外,SlimPajama数据集的文档长度和来源领域的多样性,为我们提供了丰富的数据,以支持我们的长上下文建模实验。
持续预训练的策略
1. 长度上采样的不同方法
下图是SlimPajama数据集中各种数据混合策略的长度和域分布。在持续预训练过程中,我们考虑了几种不同的长度上采样方法,包括在4K处截断文档、在128K处截断文档、每源长度上采样以及全局长度上采样。这些方法各有利弊,例如在4K处截断文档虽然保留了原始数据混合,但打破了自然存在的长范围依赖;而在128K处截断文档则保留了这些长范围依赖,但仅使用自然存在的长依赖是不够的。全局长度上采样和针对特定源(如Arxiv/Book/Github)的上采样则会同时改变域混合和长度分布。

2. 选择每源长度上采样策略的理由
我们最终选择了每源长度上采样策略,因为实验表明(下图)这种方法能够在保持原始域混合比例的同时,提高长文档的比例,从而获得最平衡的性能提升。具体来说,我们将每个域中超过4K长度的文档的比例从约30%提高到约70%,这样做可以在不改变域混合比例的情况下,只改变训练文档的长度分布。与其他方法相比,每源长度上采样策略在保持短上下文性能的同时,显著提高了长上下文任务的性能。

下表是我们考虑了将原始数据混合更改为长上下文上采样数据混合后,跨领域的损失有何不同,并报告了与原始数据混合的损失差异(例如,每个源长度的上采样损失减去原始混合的损失)。我们认为损失差异大于0.01是显著的,用红色阴影表示性能下降超过+0.01的损失;或用绿色阴影表示性能改善小于-0.01的损失,或用灰色阴影表示没有显著差异。尽管对书籍/代码/arxiv进行上采样可以提高短上下文和长上下文的域内性能,但这种改进并不适用于所有领域。相反,对一个领域进行上采样,例如代码,甚至可能损害另一个领域,例如书籍。每个源长度的上采样是最平衡的混合,几乎没有任何跨领域的损失显著增加。

实验结果:长上下文性能的提升
1. 长上下文任务的表现与短上下文性能的维持
在长上下文任务中,我们的方法不仅提高了精确检索的能力,还保持了短上下文性能。这一点通过MMLU得分得到了证明(如下表),MMLU是一个广泛接受的基准测试,用于测试语言模型在短上下文内的一般能力。我们的方法在长上下文任务(Needle.)上的表现优于顶级开源模型,并且在短上下文性能(MMLU)上在开源模型中保持领先。

下表是我们进一步比较了128K上下文语言模型在一本书长度问题解答基准上的表现。这项任务是在一本书上建立语言模型,然后提出有关情节的问题。我们的方法优于LongLoRA和Yarn Mistral。我们的13B模型性能缩小了与GPT-4 128K的差距,预计未来的扩展和指令调整将进一步提高性能。

2. 长上下文能力的逐步解锁与数据量的关系
如下图,我们的实验结果表明,随着训练数据量的增加,模型的检索性能逐渐提高。特别是,当模型在500M到1B的token上进行持续预训练时,模型在其持续预训练的80K上下文内取得了相对良好的性能,但并不泛化到80K-128K的范围。在5B token之后,模型在0-80K上表现良好,并能泛化到未见长度80K-128K。在10B token时,模型似乎对其80K训练范围过拟合,长度泛化开始下降。在这一过程中,我们看到了损失的逐渐减少,这与检索性能的提高相关联。

讨论:数据工程对长上下文性能的影响
1. 长上下文模型性能的关键因素
在大语言模型研究中,数据工程与建模和算法创新同等重要。我们的研究结果强调了数据工程在长上下文模型性能中的重要性。我们的方法在长上下文任务上的改进归功于我们对数据工程的细致处理,包括持续预训练数据的长度、数据混合集、长度上采样等三个方面。我们也承认,我们的研究之所以成为可能,也得益于最新的机器学习系统研究中的创新,特别是FlashAttention,它将注意力机制的内存使用量从二次方减少到线性。
2. 长上下文训练的可行性与资源需求
我们展示了在学术级资源下进行长上下文持续预训练是可行的。我们的配置在8×80G A100上进行训练,耗时5天(下表)。我们的结果表明,对于监督式微调,由于长上下文训练的成本远低于之前认为的,未来的工作可以更深入地探讨100K长度微调和推理的解决方案,目前几乎没有开源工作涉及这一领域。对于预训练研究,目前还没有明确的答案,即长上下文持续预训练是否应该与其他能力(如数学和编码)结合,这通常需要数千亿的token。

结论:长上下文预训练的新策略
1. 长上下文能力的预训练获取
在对长上下文模型的研究中,我们发现,通过在适当的数据混合上进行轻量级的持续预训练,可以将模型的长上下文能力从4K扩展到128K。这一发现基于假设:即使是在4K上下文长度的预训练中,模型已经大致获得了在任意位置利用信息的能力。我们的实验表明,通过在1-5亿个token的长上下文数据上进行持续预训练,模型能够在128K的上下文中检索信息,而无需从头开始进行大规模预训练。
我们的数据工程方法强调了数据量和质量的重要性。对于数据量,我们证明了500亿到50亿token足以使模型能够在128K上下文中检索信息。而在数据质量方面,我们的研究结果强调了域平衡和长度上采样的重要性。我们发现,简单地在某些域(如书籍)上进行长数据上采样会导致次优的性能,而保持平衡的域混合则至关重要。
2. 对未来长上下文指导性微调研究的启示
我们的研究为未来在长上下文中进行指导性微调提供了新的见解。我们展示了在长上下文数据上进行持续预训练是一种有效且经济的策略,我们的方法在长上下文检索任务上缩小了与前沿模型如GPT-4 128K的差距,并为未来在100K上下文长度上进行指导性微调的研究奠定了基础。
公众号「夕小瑶科技说」后台回复“ 128K ”获取论文PDF!文章来源:https://www.toymoban.com/news/detail-838408.html
 文章来源地址https://www.toymoban.com/news/detail-838408.html
文章来源地址https://www.toymoban.com/news/detail-838408.html
到了这里,关于符尧大佬一作发文,仅改训练数据,就让LLaMa-2上下文长度扩展20倍!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!