目录
urllib库简介
request模块
parse模块
error模块
response模块
读取响应内容
获取响应状态码
获取响应头部信息
处理重定向
关闭响应
总结
在Python的众多库中,urllib库是一个专门用于处理网络请求的强大工具。urllib库提供了多种方法来打开和读取URLs,从而使得网络数据的获取和处理变得简单而直接。本文将带领大家走进urllib库的世界,探索其功能和用法。
urllib库简介
urllib库是Python的一个标准库,它包含了多个模块,用于处理URL相关的操作。其中,request模块用于打开和读取URLs,parse模块用于解析URLs,error模块则用于处理URL请求过程中可能出现的异常。
request模块
urllib.request模块提供了多种方法来实现URL的打开和读取。其中最常用的方法是urlopen()。这个方法接收一个URL作为参数,返回一个HTTPResponse对象,该对象包含了服务器的响应。
下面是一个简单的示例:
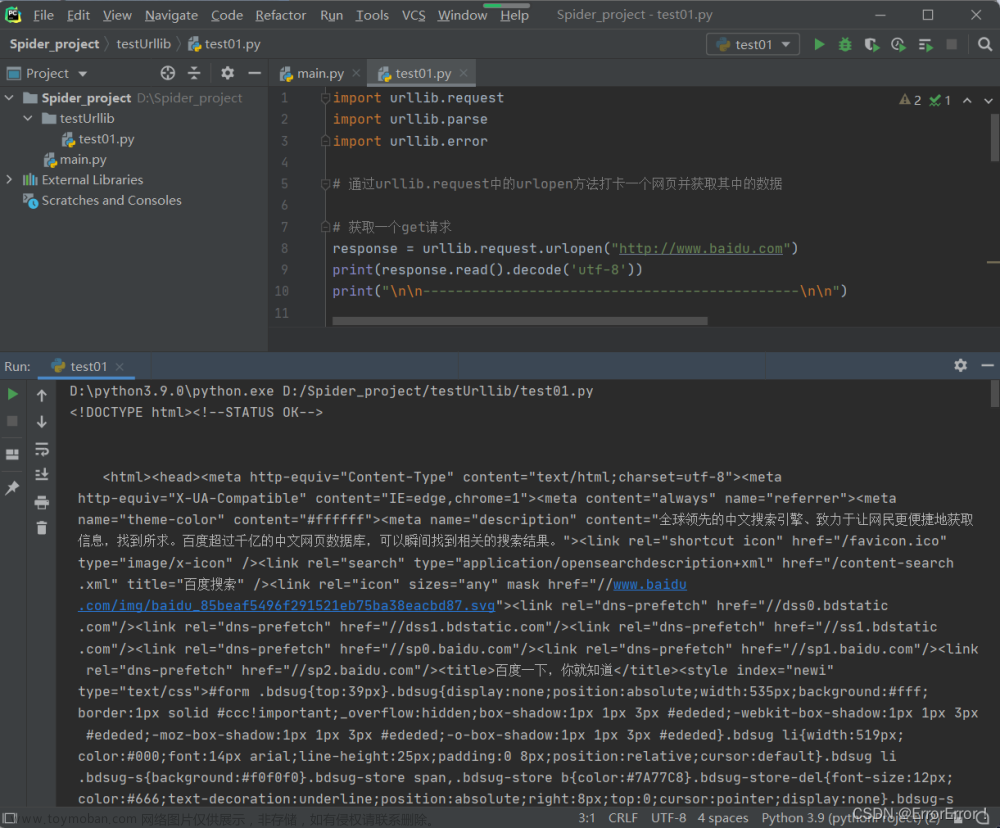
import urllib.request
response = urllib.request.urlopen('http://www.example.com')
print(response.read())在这个示例中,首先导入了urllib.request模块,然后使用urlopen()方法打开了一个URL。返回的HTTPResponse对象包含了服务器的响应,可以使用read()方法读取这个响应的内容。
parse模块
urllib.parse模块主要用于解析URLs。它提供了多种函数来解析URL的各个组成部分,比如网络位置、路径、参数等。
例如,使用urlparse()函数来解析一个URL:
import urllib.parse
url = 'http://www.example.com/path?arg1=value1&arg2=value2'
parsed_url = urllib.parse.urlparse(url)
print('Scheme:', parsed_url.scheme)
print('Netloc:', parsed_url.netloc)
print('Path:', parsed_url.path)
print('Params:', parsed_url.params)
print('Query:', parsed_url.query)
print('Fragment:', parsed_url.fragment)这个示例中,使用了urlparse()函数来解析一个URL,并打印出了URL的各个组成部分。
error模块
在网络请求中,经常会遇到各种异常,比如URL无法访问、网络连接超时等。urllib库提供了urllib.error模块来处理这些异常。
可以使用try-except语句来捕获和处理这些异常:
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://www.example.com')
print(response.read())
except urllib.error.URLError as e:
print('Error occurred:', e.reason)在这个示例中,如果urlopen()方法抛出了URLError异常,就会捕获这个异常并打印出错误的原因。
下面是 urllib.error 模块中一些常见的异常类及其使用示例:
URLError
URLError 是 urllib.error 模块中定义的基类,用于处理所有与 URL 相关的错误。它通常包含了一个描述错误的“原因”(reason)。
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://nonexistent-domain.com')
except urllib.error.URLError as e:
print('An error occurred:', e.reason)HTTPError
HTTPError 是 URLError 的一个子类,专门用于处理 HTTP 请求过程中出现的错误,比如 404 Not Found 或 500 Internal Server Error。当请求成功但服务器返回了一个错误状态码时,就会抛出 HTTPError 异常。
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://www.example.com/nonexistent-page')
except urllib.error.HTTPError as e:
print('HTTP error occurred:', e.code) # 输出 HTTP 状态码
print(e.reason) # 输出错误原因
print(e.headers) # 输出响应头部
print(e.read()) # 读取响应体内容(如果可用)ContentTooShortError
ContentTooShortError 异常通常在读取的数据少于预期时抛出。这可能是因为连接在数据完全接收之前被关闭。
import urllib.request
import urllib.error
try:
# 假设这个 URL 返回一个非常小的内容,但我们期望的内容长度更长
response = urllib.request.urlopen('http://www.example.com/small-content')
content = response.read(1000) # 尝试读取比实际内容更多的数据
except urllib.error.ContentTooShortError as e:
print('Content was too short:', e)异常处理策略
在实际应用中,可能会根据具体的需求来捕获和处理不同的异常。通常,会首先捕获 HTTPError,因为它提供了关于 HTTP 请求失败的详细信息。然后,会捕获更一般的 URLError,以处理其他与 URL 相关的错误。
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://www.example.com/some-page')
except urllib.error.HTTPError as e:
# 处理 HTTP 错误,比如状态码检查、重试逻辑等
print('HTTP error occurred:', e.code)
except urllib.error.URLError as e:
# 处理 URL 错误,比如网络不可用、DNS 解析失败等
print('URL error occurred:', e.reason)
except Exception as e:
# 处理其他未明确捕获的异常
print('An unexpected error occurred:', e)通过适当地使用 try-except 语句和 urllib.error 模块中的异常类,可以编写出健壮的网络请求代码,能够优雅地处理各种可能的错误情况。
response模块
urllib.response模块主要用于处理服务器的响应。通常,不需要直接操作urllib.response模块,而是会通过urllib.request模块得到的urllib.response.HttpResponse对象来间接地使用它。
当使用urllib.request.urlopen()或者其他类似方法发送一个HTTP请求时,如果请求成功,将得到一个HttpResponse对象,这个对象就是urllib.response模块的一部分。这个对象提供了方法来处理响应的状态、头部以及响应体。
以下是urllib.response模块在使用中经常涉及的几个方面:
读取响应内容
使用read()方法读取响应体的内容。
import urllib.request
response = urllib.request.urlopen('http://www.example.com')
content = response.read()
print(content)获取响应状态码
使用status属性获取HTTP响应的状态码。
import urllib.request
response = urllib.request.urlopen('http://www.example.com')
status_code = response.status
print(status_code)获取响应头部信息
使用getheader(name)方法获取特定头部的值,或者使用headers属性获取所有头部信息。
import urllib.request
response = urllib.request.urlopen('http://www.example.com')
content_type = response.getheader('Content-Type')
print(content_type)
# 获取所有头部信息
for header, value in response.headers.items():
print(header, value)处理重定向
默认情况下,urllib.request会自动处理HTTP重定向。但如果需要更细粒度的控制,可以通过urllib.request.HTTPRedirectHandler来自定义重定向行为。
处理cookies
虽然urllib.response模块本身不直接处理cookies,但可用urllib.request.HTTPCookieProcessor与http.cookiejar.CookieJar来管理cookies。
关闭响应
在读取完响应内容后,为了释放系统资源,通常应该关闭响应。Python的HTTP响应对象支持上下文管理器协议,因此可以使用with语句来自动关闭响应。
import urllib.request
with urllib.request.urlopen('http://www.example.com') as response:
content = response.read()
# 在这里处理内容
# 响应会在with块结束时自动关闭尽管urllib.response模块提供了这些功能,但在日常使用中,更多的是与urllib.request模块交互,它负责发送请求并返回HttpResponse对象,而HttpResponse对象则提供了上述方法来处理响应。
需要注意的是,对于更复杂的网络请求和处理,如POST请求、设置请求头部、处理cookies等,可能还需要结合urllib.request中的其他类和方法一起使用。同时,对于更加现代和高级的HTTP客户端需求,还可以考虑使用requests库,它提供了更加友好和强大的API。
代码实例
以下举3个实例,都是代码框架并不能正常运行,请根据网页实现情况修改代码。文章来源:https://www.toymoban.com/news/detail-838450.html
图片下载
import re
import urllib.request
def download_images(url):
# 从网页获取HTML代码
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
# 使用正则表达式提取图片URL
img_urls = re.findall(r'src="([^"]+\.(?:png|jpg|jpeg|gif|bmp))"', html)
# 遍历图片URL并下载图片
for img_url in img_urls:
img_url = 'http://example.com/' + img_url # 根据实际情况修改URL前缀
urllib.request.urlretrieve(img_url, 'image_' + img_url.split('/')[-1]) # 下载图片并保存
# 使用函数下载图片
download_images('http://example.com/some_page_with_images') # 替换为实际的网页URL股票信息
import urllib.request
from urllib.parse import urlencode
import json
def get_stock_info(stock_symbol):
# 假设有一个网站提供股票信息,并且它接受一个查询参数'symbol'
url = 'http://example.com/stock_info'
params = {'symbol': stock_symbol}
query_string = urlencode(params)
full_url = f"{url}?{query_string}"
# 发起请求
req = urllib.request.Request(full_url)
response = urllib.request.urlopen(req)
data = response.read()
# 解析JSON响应
stock_data = json.loads(data)
return stock_data
# 使用函数获取股票信息
stock_symbol = 'AAPL' # 例如,查询苹果公司的股票信息
stock_info = get_stock_info(stock_symbol)
# 输出股票信息
print(stock_info)天气预报
import urllib.request
import json
def get_weather_forecast(city):
# 假设有一个提供天气服务的网站,并且它接受一个查询参数'city'
url = 'http://example.com/weather_forecast'
params = {'city': city}
query_string = urllib.parse.urlencode(params)
full_url = f"{url}?{query_string}"
# 发起请求
req = urllib.request.Request(full_url)
response = urllib.request.urlopen(req)
data = response.read()
# 解析JSON响应
weather_data = json.loads(data)
return weather_data
# 使用函数获取天气预报
city = 'Beijing' # 想要查询的城市
weather_forecast = get_weather_forecast(city)
# 输出天气预报信息
print(weather_forecast)总结
urllib库是Python中用于处理网络请求的强大工具。通过urllib库,可以方便地打开和读取URLs,处理网络请求中的异常,以及解析URLs的各个组成部分。无论是进行网络爬虫的开发,还是实现其他与网络请求相关的功能,urllib库都是一个值得学习和使用的工具。文章来源地址https://www.toymoban.com/news/detail-838450.html
到了这里,关于Python 初步了解urllib库:网络请求的利器的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![python request大批量发送请求调用接口时,报错:[WinError 10048] 通常每个套接字地址(协议/网络地址/端口)只允许使用一次。](https://imgs.yssmx.com/Uploads/2024/01/409508-1.png)