机器学习流程—数据预处理 缩放和转换
相信机器学习的从业者,一定听到到过“特征缩放”这个术语,它被认为是数据处理周期中不可跳过的部分,因进行相应的操作们可以实现 ML 算法的稳定和快速训练。在本文中,我们将了解在实践中用于执行特征缩放的不同技术。
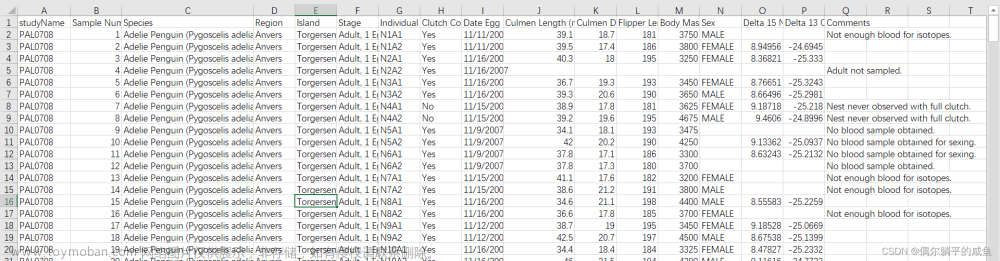
不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据归一化/标准化处理,以解决数据指标之间的可比性。文章来源:https://www.toymoban.com/news/detail-838480.html
如果没有进行特征缩放,那么机器学习算法往往会权衡较大的值,而忽略较小的值的权重,而不管值的单位如何,其实这是有问题的,举个例子富人的钱可能是用亿来衡量的,而群人的钱使用元来衡量的,这是单位的不同;还有有些数据本身的范围就比较大,例如人的收入和年龄相比,本身就存在很大的差距。文章来源地址https://www.toymoban.com/news/detail-838480.html
特征缩放的意义
- 缩放保证所有特征都处于可比较的规模并且具有可比较的范围。这个过程称为特征标准化。这很重要,因为特征的大小会对许多机器学习技术产生影响。较大规模的特征可能会主导学习过程并对结果产生过度影响,可以通过缩放特征来确保每个特征对学习过程的贡献相同。
- 算法性能改进:当特征缩放时,多种机器学习方法,包括基于梯度下降的算法、基于距离的算法(例如 k 最近邻)和支持向量机,性能更好或收敛得更快。通过缩放特征可以提高算法的性能,这可以加速算法收敛到理想结果。
- 防止数值不稳定:可以通过避免特征之间的显着尺度差异来防止数值不稳定。示例包括距离计算或矩阵运算,其中具有完全不同比例的特征可能会导致数值上溢或下溢问题。确保稳定的计算,并通过扩展功能来缓解这些问题
到了这里,关于机器学习流程—数据预处理 缩放和转换的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!