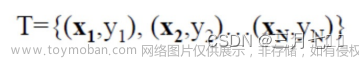机器学习(算法篇)完整教程(附代码资料)主要内容讲述:机器学习算法课程定位、目标,K-近邻算法,1.1 K-近邻算法简介,1.2 k近邻算法api初步使用定位,目标,学习目标,1 什么是K-近邻算法,1 Scikit-learn工具介绍,2 K-近邻算法API,3 案例,4 小结。K-近邻算法,1.3 距离度量学习目标,1 欧式距离,2 ,3 切比雪夫距离 (Chebyshev Distance):,4 闵可夫斯基距离(Minkowski Distance):,5 标准化欧氏距离 (Standardized EuclideanDistance):,6 余弦距离(Cosine Distance),7 汉明距离(Hamming Distance)【了解】:,9 马氏距离(Mahalanobis Distance)【了解】。K-近邻算法,1.4 k值的选择学习目标。K-近邻算法,1.5 kd树学习目标,1 kd树简介,2 构造方法,3 案例分析,4 总结。K-近邻算法,1.6 案例:鸢尾花种类预测--数据集介绍,1.7 特征工程-特征预处理学习目标,1 案例:鸢尾花种类预测,2 scikit-learn中数据集介绍,1 什么是特征预处理,2 归一化,3 标准化。K-近邻算法,1.8 案例:鸢尾花种类预测—流程实现,1.9 练一练,1.10 交叉验证,网格搜索,1.11 案例2:预测facebook签到位置学习目标,1 再识K-近邻算法API,2 案例:鸢尾花种类预测,总结,1 什么是交叉验证(cross validation),2 什么是网格搜索(Grid Search),3 交叉验证,网格搜索(模型选择与调优)API:,4 鸢尾花案例增加K值调优,1 数据集介绍,2 步骤分析,3 代码过程。线性回归,2.1 线性回归简介,2.2 线性回归api初步使用,2.3 数学:求导学习目标,1 线性回归应用场景,2 什么是线性回归,1 线性回归API,2 举例,1 常见函数的导数,2 导数的四则运算,3 练习,4 矩阵(向量)求导 [了解]。线性回归,2.4 线性回归的损失和优化学习目标,1 损失函数,2 优化算法。线性回归,2.6 梯度下降法介绍,2.5 线性回归api再介绍学习目标,1 全梯度下降算法(FG),2 随机梯度下降算法(SG),3 小批量梯度下降算法(mini-bantch),4 随机平均梯度下降算法(SAG),5 算法比较,6 梯度下降优化算法(拓展)。线性回归,2.7 案例:波士顿房价预测学习目标,1 分析,2 回归性能评估,3 代码。线性回归,2.8 欠拟合和过拟合学习目标,1 定义,2 原因以及解决办法,3 正则化,4 维灾难【拓展知识】。线性回归,2.9 正则化线性模型,2.10 线性回归的改进-岭回归,2.11 模型的保存和加载,逻辑回归,3.1 逻辑回归介绍,3.2 逻辑回归api介绍,3.3 案例:癌症分类预测-良/恶性乳腺癌肿瘤预测学习目标,1 Ridge Regression (岭回归,又名 Tikhonov regularization),2 Lasso Regression(Lasso 回归),3 Elastic Net (弹性网络),4 Early Stopping [了解],1 API,2 观察正则化程度的变化,对结果的影响?,3 波士顿房价预测,1 sklearn模型的保存和加载API,2 线性回归的模型保存加载案例,学习目标,1 逻辑回归的应用场景,2 逻辑回归的原理,3 损失以及优化,1 分析,2 代码。逻辑回归,3.4 分类评估方法,3.5 ROC曲线的绘制,决策树算法,4.1 决策树算法简介学习目标,1.分类评估方法,2 ROC曲线与AUC指标,3 总结,1 曲线绘制,2 意义解释,学习目标。决策树算法,4.2 决策树分类原理学习目标,1 熵,2 决策树的划分依据一------信息增益,3 决策树的划分依据二----信息增益率,4 决策树的划分依据三——基尼值和基尼指数。决策树算法,4.3 cart剪枝学习目标,1 为什么要剪枝,2 常用的减枝方法。决策树算法,4.4 特征工程-特征提取学习目标,1 特征提取,2 字典特征提取,3 文本特征提取。决策树算法,4.5 决策树算法api,4.6 案例:泰坦尼克号乘客生存预测,集成学习,5.1 集成学习算法简介,5.2 Bagging学习目标,1 泰坦尼克号数据,2 步骤分析,3 代码过程,3 决策树可视化,学习目标,1 什么是集成学习,2 ,3 集成学习中boosting和Bagging,1 Bagging集成原理,2 随机森林构造过程,3 随机森林api介绍,4 随机森林预测案例,5 bagging集成优点。集成学习,5.3 Boosting,聚类算法,6.1 聚类算法简介,6.2 聚类算法api初步使用,6.3 聚类算法实现流程学习目标,1.boosting集成原理,2 GBDT(了解),3.XGBoost【了解】,4 什么是泰勒展开式【拓展】,学习目标,1 认识聚类算法,1 api介绍,2 案例,1 k-means聚类步骤,2 案例练习,3 小结。聚类算法,6.4 模型评估,6.5 算法优化学习目标,1 误差平方和(SSE \The sum of squares due to error):,2 , — K值确定,3 轮廓系数法(Silhouette Coefficient),4 CH系数(Calinski-Harabasz Index),5 总结,1 Canopy算法配合初始聚类,2 K-means++,3 二分k-means,4 k-medoids(k-中心聚类算法),5 Kernel k-means(了解),6 ISODATA(了解),7 Mini Batch K-Means(了解),8 总结。聚类算法,6.6 特征降维,6.7 案例:探究用户对物品类别的喜好细分降维,6.8 算法选择指导学习目标,1 降维,2 特征选择,3 主成分分析,1 需求,2 分析,3 完整代码。
全套笔记资料代码移步: 前往gitee仓库查看
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~


机器学习算法课程定位、目标
定位
- 课程以算法、案例为驱动的学习,伴随浅显易懂的数学知识
- 作为人工智能领域的提升课程,掌握更深更有效的解决问题技能
目标
- 掌握机器学习常见算法原理
- 应用Scikit-learn实现机器学习算法的应用,
- 结合场景解决实际问题
K-近邻算法
学习目标
- 掌握K-近邻算法实现过程
- 知道K-近邻算法的距离公式
- 知道K-近邻算法的超参数K值以及取值问题
- 知道kd树实现搜索的过程
- 应用KNeighborsClassifier实现分类
- 知道K-近邻算法的优缺点
- 知道交叉验证实现过程
- 知道超参数搜索过程
- 应用GridSearchCV实现算法参数的调优
1.1 K-近邻算法简介
1 什么是K-近邻算法

- 根据你的“邻居”来推断出你的类别
1.1 K-近邻算法(KNN)概念
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法
- 定义
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
- 距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离 ,关于距离公式会在后面进行讨论


1.2 电影类型分析
假设我们现在有几部电影

其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想

分别计算每个电影和被预测电影的距离,然后求解

1.2 k近邻算法api初步使用
机器学习流程复习:

- 1.获取数据集
- 2.数据基本处理
- 3.特征工程
- 4.机器学习
- 5.模型评估
1 Scikit-learn工具介绍

- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API
- 目前稳定版本0.19.1
1.1 安装
pip3 install scikit-learn==0.19.1
安装好之后可以通过以下命令查看是否安装成功
import sklearn
- 注:安装scikit-learn需要Numpy, Scipy等库
1.2 Scikit-learn包含的内容

- 分类、聚类、回归
- 特征工程
- 模型选择、调优
2 K-近邻算法API
-
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
3 案例
3.1 步骤分析
- 1.获取数据集
- 2.数据基本处理(该案例中省略)
- 3.特征工程(该案例中省略)
- 4.机器学习
- 5.模型评估(该案例中省略)
3.2 代码过程
- 导入模块
from sklearn.neighbors import KNeighborsClassifier
- 构造数据集
x = [[0], [1], [2], [3]]
y = [0, 0, 1, 1]
- 机器学习 -- 模型训练
# 实例化API
estimator = KNeighborsClassifier(n_neighbors=2)
# 使用fit方法进行训练
estimator.fit(x, y)
estimator.predict([[1]])
4 小结
-
最近邻 (k-Nearest Neighbors,KNN) 算法是一种分类算法,
-
1968年由 Cover 和 Hart 提出,应用场景有字符识别、文本分类、图像识别等领域。
-
该算法的思想是:一个样本与数据集中的k个样本最相似,如果这k个样本中的大多数属于某一个类别.
-
实现流程
1)计算已知类别数据集中的点与当前点之间的距离
2)按距离递增次序排序
3)选取与当前点距离最小的k个点
4)统计前k个点所在的类别出现的频率
5)返回前k个点出现频率最高的类别作为当前点的预测分类

-
问题
1.距离公式,除了欧式距离,还有哪些距离公式可以使用?
2.选取K值的大小?
3.api中其他参数的具体含义?
K-近邻算法
学习目标
- 掌握K-近邻算法实现过程
- 知道K-近邻算法的距离公式
- 知道K-近邻算法的超参数K值以及取值问题
- 知道kd树实现搜索的过程
- 应用KNeighborsClassifier实现分类
- 知道K-近邻算法的优缺点
- 知道交叉验证实现过程
- 知道超参数搜索过程
- 应用GridSearchCV实现算法参数的调优
1.3 距离度量
1 欧式距离(Euclidean Distance):
欧氏距离是最容易直观理解的距离度量方法,我们小学、初中和高中接触到的两个点在空间中的距离一般都是指欧氏距离。

举例:
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 1.4142 2.8284 4.2426 1.4142 2.8284 1.4142
2 曼哈顿距离(Manhattan Distance):
在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)。


举例:
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 2 4 6 2 4 2
3 切比雪夫距离 (Chebyshev Distance):
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。


举例:
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 1 2 3 1 2 1
4 闵可夫斯基距离(Minkowski Distance):
闵氏距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述。
两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:

其中p是一个变参数:
当p=1时,就是曼哈顿距离;
当p=2时,就是欧氏距离;
当p→∞时,就是切比雪夫距离。
根据p的不同,闵氏距离可以表示某一类/种的距离。
小结:
1 闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在明显的缺点:
e.g. 二维样本(身高[单位:cm],体重[单位:kg]),现有三个样本:a(180,50),b(190,50),c(180,60)。
a与b的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c的闵氏距离。但实际上身高的10cm并不能和体重的10kg划等号。
2 闵氏距离的缺点:
(1)将各个分量的量纲(scale),也就是“单位”相同的看待了;
(2)未考虑各个分量的分布(期望,方差等)可能是不同的。
5 标准化欧氏距离 (Standardized EuclideanDistance):
标准化欧氏距离是针对欧氏距离的缺点而作的一种改进。
思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化”到均值、方差相等。假设样本集X的均值(mean)为m,标准差(standard deviation)为s,X的“标准化变量”表示为:

如果将方差的倒数看成一个权重,也可称之为加权欧氏距离(Weighted Euclidean distance)。
举例:
X=[[1,1],[2,2],[3,3],[4,4]];(假设两个分量的标准差分别为0.5和1)
经计算得:
d = 2.2361 4.4721 6.7082 2.2361 4.4721 2.2361
6 余弦距离(Cosine Distance)
几何中,夹角余弦可用来衡量两个向量方向的差异;机器学习中,借用这一概念来衡量样本向量之间的差异。
- 二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:

- 两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦为:

即:

夹角余弦取值范围为[-1,1]。余弦越大表示两个向量的夹角越小,余弦越小表示两向量的夹角越大。当两个向量的方向重合时余弦取最大值1,当两个向量的方向完全相反余弦取最小值-1。
举例:
X=[[1,1],[1,2],[2,5],[1,-4]]
经计算得:
d = 0.9487 0.9191 -0.5145 0.9965 -0.7593 -0.8107
7 汉明距离(Hamming Distance)【了解】:
两个等长字符串s1与s2的汉明距离为:将其中一个变为另外一个所需要作的最小字符替换次数。
例如:
The Hamming distance between "1011101" and "1001001" is 2.
The Hamming distance between "2143896" and "2233796" is 3.
The Hamming distance between "toned" and "roses" is 3.

随堂练习:
求下列字符串的汉明距离:
1011101与 1001001
2143896与 2233796
irie与 rise
汉明重量:是字符串相对于同样长度的零字符串的汉明距离,也就是说,它是字符串中非零的元素个数:对于二进制字符串来说,就是 1 的个数,所以 11101 的汉明重量是 4。因此,如果向量空间中的元素a和b之间的汉明距离等于它们汉明重量的差a-b。
应用:汉明重量分析在包括信息论、编码理论、密码学等领域都有应用。比如在信息编码过程中,为了增强容错性,应使得编码间的最小汉明距离尽可能大。但是,如果要比较两个不同长度的字符串,不仅要进行替换,而且要进行插入与删除的运算,在这种场合下,通常使用更加复杂的编辑距离等算法。
举例:
X=[[0,1,1],[1,1,2],[1,5,2]]
注:以下计算方式中,把2个向量之间的汉明距离定义为2个向量不同的分量所占的百分比。
经计算得:
d = 0.6667 1.0000 0.3333
8 杰卡德距离(Jaccard Distance)【了解】:
杰卡德相似系数(Jaccard similarity coefficient):两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示:

杰卡德距离(Jaccard Distance):与杰卡德相似系数相反,用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度:

举例:
X=[[1,1,0][1,-1,0],[-1,1,0]]
注:以下计算中,把杰卡德距离定义为不同的维度的个数占“非全零维度”的比例
经计算得:
d = 0.5000 0.5000 1.0000
9 马氏距离(Mahalanobis Distance)【了解】
下图有两个正态分布图,它们的均值分别为a和b,但方差不一样,则图中的A点离哪个总体更近?或者说A有更大的概率属于谁?显然,A离左边的更近,A属于左边总体的概率更大,尽管A与a的欧式距离远一些。这就是马氏距离的直观解释。

马氏距离是基于样本分布的一种距离。
马氏距离是由印度统计学家马哈拉诺比斯提出的,表示数据的协方差距离。它是一种有效的计算两个位置样本集的相似度的方法。
与欧式距离不同的是,它考虑到各种特性之间的联系,即独立于测量尺度。
马氏距离定义:设总体G为m维总体(考察m个指标),均值向量为μ=(μ1,μ2,… ...,μm,)`,协方差阵为∑=(σij),
则样本X=(X1,X2,… …,Xm,)`与总体G的马氏距离定义为:

马氏距离也可以定义为两个服从同一分布并且其协方差矩阵为∑的随机变量的差异程度:如果协方差矩阵为单位矩阵,马氏距离就简化为欧式距离;如果协方差矩阵为对角矩阵,则其也可称为正规化的欧式距离。
马氏距离特性:
1.量纲无关,排除变量之间的相关性的干扰;
2.马氏距离的计算是建立在总体样本的基础上的,如果拿同样的两个样本,放入两个不同的总体中,最后计算得出的两个样本间的马氏距离通常是不相同的,除非这两个总体的协方差矩阵碰巧相同;
3 .计算马氏距离过程中,要求总体样本数大于样本的维数,否则得到的总体样本协方差矩阵逆矩阵不存在,这种情况下,用欧式距离计算即可。
4.还有一种情况,满足了条件总体样本数大于样本的维数,但是协方差矩阵的逆矩阵仍然不存在,比如三个样本点(3,4),(5,6),(7,8),这种情况是因为这三个样本在其所处的二维空间平面内共线。这种情况下,也采用欧式距离计算。
欧式距离&马氏距离:

举例:
已知有两个类G1和G2,比如G1是设备A生产的产品,G2是设备B生产的同类产品。设备A的产品质量高(如考察指标为耐磨度X),其平均耐磨度μ1=80,反映设备精度的方差σ2(1)=0.25;设备B的产品质量稍差,其平均耐磨损度μ2=75,反映设备精度的方差σ2(2)=4.
今有一产品G0,测的耐磨损度X0=78,试判断该产品是哪一台设备生产的?
直观地看,X0与μ1(设备A)的绝对距离近些,按距离最近的原则,是否应把该产品判断设备A生产的?
考虑一种相对于分散性的距离,记X0与G1,G2的相对距离为d1,d2,则:

因为d2=1.5 < d1=4,按这种距离准则,应判断X0为设备B生产的。
设备B生产的产品质量较分散,出现X0为78的可能性较大;而设备A生产的产品质量较集中,出现X0为78的可能性较小。
这种相对于分散性的距离判断就是马氏距离。文章来源:https://www.toymoban.com/news/detail-838578.html
 文章来源地址https://www.toymoban.com/news/detail-838578.html
文章来源地址https://www.toymoban.com/news/detail-838578.html
未完待续, 同学们请等待下一期
全套笔记资料代码移步: 前往gitee仓库查看
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
到了这里,关于【机器学习】机器学习创建算法第1篇:机器学习算法课程定位、目标【附代码文档】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!