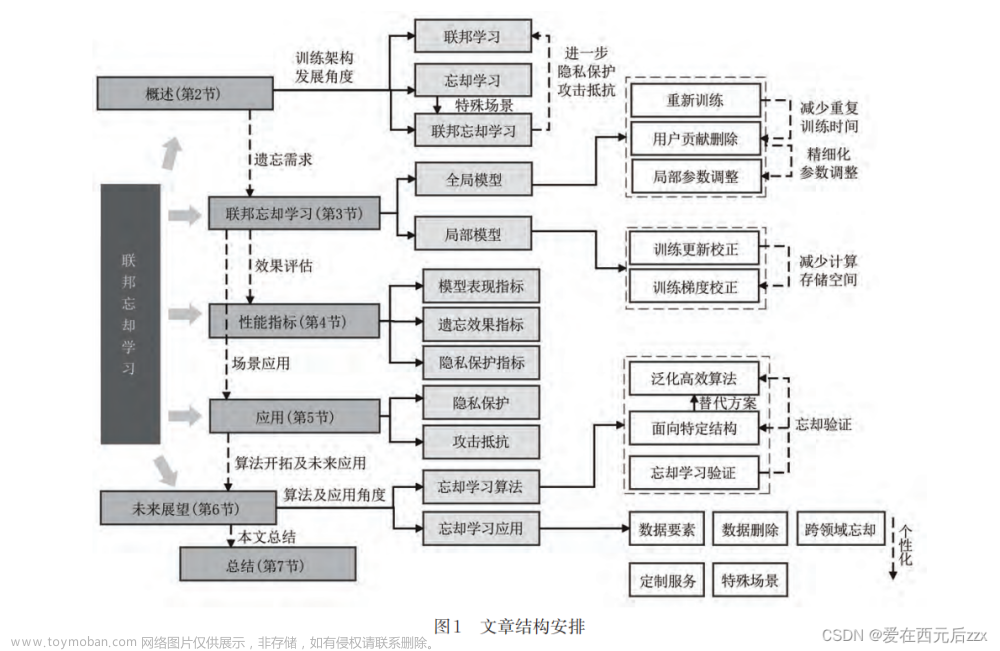
论文:联邦忘却学习研究综述
federated unlearning-联邦忘却学习
- 摘要
联邦忘却学习撤销用户数据对联邦学习模型的训练更新,可以进一步保护联邦学习用户的数据安全。
联邦忘却学习在联邦学习框架的基础上,通过迭代训练,直接删除等方式,撤销用户本地局部模型对全局模型的训练更新
- 2.1联邦学习
传统机器学习要求用户将原始数据上传至高性能云服务器进行集中式训练
联邦学习为中心服务器协同由N个持有训练数据的用户组成的集合U={u1,u2…un}共同训练机器学习模型,得到模型最优参数,其中每个用户持有训练数据。(FedAvg聚合规则对参与训练用户局部模型的参数更新进行聚合)

联邦学习所有用户共享全局模型的训练方式带来了新的数据隐私泄露安全隐患:
- 共享的全局模型可能泄露用户隐私数据。联邦学习的机器学习模型对所有参与训练的用户开放,攻击者可以在本地训练过程中访问全局模型,根据模型反推参与者的数据信息,进而导致数据隐私泄露。(成员推理攻击、模型翻转攻击)
- 在聚合过程中,如果不能识别恶意用户上传的虚假模型,联邦学习训练的机器学习模型可能受到数据投毒、模型投毒等攻击。
- 2.2忘却学习
忘却学习的核心在于通过调整模型参数,实现与特定数据未参与训练相同的效果,同时避免完全的重复性训练。基于忘却学习方法,服务提供者可以依据用户请求,使机器学习模型遗忘由特定用户数据训练产生的数据贡献,确保无法从模型中追踪到该用户数据的踪迹。
机器忘却学习不受隐私保护或数据加密的限制,将所有训练数据集中处理,对特定数据进行忘却学习。
- 2.3联邦忘却学习
联邦忘却学习通过撤销用户数据对全局模型产生的训练更新,来解决联邦学习中存在的隐私泄露问题。

联邦忘却学习流程:
- 联邦学习。中心服务器协同用户集合进行联邦学习,训练得到最优模型参数。
- 数据更新撤销。用户可以在任意时刻向中心服务器发送撤销数据请求。中心服务器根据用户请求完成目标。
- 用户将数据从联邦学习系统中删除,防止数据被重新训练。
- 服务器继续发起联邦学习任务,恢复全局模型的预测准确率。
联邦忘却学习忘却粒度
用户在不同场景下提出的联邦忘却学习请求有所不同,主要体现在联邦忘却学习对全局模型的忘却粒度。
- 样本忘却是从联邦学习模型中撤销特定数据样本对模型的训练更新,是细粒度的忘却学习请求,也是联邦忘却学习中常见的请求之一。
- 类别忘却用于分类任务中撤销单个或多个类别的数据对全局模型的训练更新。
- 任务忘却是粗粒度的忘却学习请求,用于撤销某个任务所有数据对模型的训练更新,但会因大量的数据撤销而产生灾难性的忘却。
- 3.联邦忘却学习算法
根据修正对象将各类联邦忘却学习算法划分为面向全局模型和面向局部模型。面向全局模型的忘却算法直接对全局模型参数进行修改并利用用户数据调整全局模型,而面向局部模型的算法则利用用户训练的局部模型参数对全局模型参数进行间接修改。
-
3.1面向全局模型的联邦忘却学习算法
-
重新训练:
重新训练通过模型回退和再训练方法能够完全撤销特定用户数据对模型的训练更新。
- 服务器通过联邦学习在服务器持续更新全局模型参数以完成模型训练
- 用户根据自身隐私需求向服务器发出忘却学习请求
- 服务器响应用户的忘却请求,将全局模型参数回退到某个训练时刻训练所对应的模型参数
- 为防止因参数回退产生的灾难性遗忘,服务器依赖回退后的模型参数在其他用户的数据上进行再训练,从而实现联邦忘却学习

重新训练在训练过程中传输大规模模型参数时会产生巨大的通信压力,并且也会增加训练的时间成本。
(Rapid retraining–KNOT–IFU)
- 用户贡献删除
针对重复性的再训练工作,用户贡献删除算法可以减少用户重复训练的时间和通信开销。
- 服务器仍然通过用户的数据训练全局模型,聚合用户数据训练产生的局部模型参数,并修改全局模型参数。
- 特定用户u向服务器发起忘却学习请求,服务器从全局模型中直接删除用户u产生的局部模型参数,实现对用户u数据的忘却。
- 服务器利用再训练提升模型准确率。
用户贡献删除算法不再进行模型参数的回退,而是撤销局部模型对全局模型的训练更新,在此基础上进行再训练。

(FUKD–FedLU)
- 局部参数调整
通过局部性地修改全局模型参数,解决特定模型结构的忘却学习问题。
- 服务器联合所有用户进行联邦学习训练,得到全局模型参数w。
- 用户ui向服务器发起忘却学习请求。
- 服务器接受忘却请求后,会根据模型结构对参数wi进行评估,识别出包含用户ui的参数贡献部分
- 服务器将全局模型中用户ui的参数贡献部分消除,形成新的参数w‘
- 服务器联合用户进行再训练,调整参数w’。

参数局部调整方法依赖于模型结构,采用可解释的数学方法判断特定用户数据贡献高的参数位置,并进行剪枝。
(RevFRF–FUKD)
- 面向全局模型算法比较
算法性能包括遗忘效果、忘却速度、占用空间和稳定性。
遗忘效果:机器学习模型执行忘却学习算法后对数据的记忆程度
忘却速度:忘却学习算法的快慢
占用空间:忘却算法过程中服务器占用的空间大小
稳定性:随联邦学习用户数量对遗忘效果、忘却速度和占用空间的敏感性

重新训练算法:遗忘效果好,忘却速度较慢,算法稳定性差,发起者均为用户,主要用于保护用户隐私,并且支持更多类型的忘却学习请求。
用户共享删除算法:占用空间大、忘却速度较快,发起者均为服务器,支持较少类型的忘却学习请求,因为其主要用于解决异构数据、中毒攻击等问题。
局部参数调整算法:遗忘效果好、忘却时间较长、占用空间较大
- 3.2面向局部模型的联邦忘却学习算法
通过增加联邦学习训练,在局部模型中获取新的知识,根据新知识整体性地修改全局模型,不需要进行再训练。
- 训练更新校正
训练更新校正算法在现有模型的基础上增加额外的联邦学习训练,对训练过程中产生的模型参数进行修正,并通过聚合修正后的模型修改全局模型的参数。
- 服务器协同所有用户进行联邦学习,完成全局模型的训练
- 用户ui向服务器发起忘却学习请求
- 服务器协同用户继续进行一定轮次的联邦学习训练,接收用户上传的模型参数
- 服务器对训练的局部模型参数进行修正,通过聚合修正后的模型参数更新全局模型,从而实现联邦忘却学习

(FedEraser–VERIFI)
- 训练梯度校正
在现有模型的基础上增加联邦学习训练,通过调整部分用户的训练方法,以直接聚合的方式来更新全局模型参数。
- 服务器协同所有用户进行联邦学习,完成全局模型参数w的更新
- 用户ui请求服务器撤销自身数据对模型的更新
- 服务器要求所有用户继续进行联邦学习训练,在此过程中调整用户的训练策略(例如损失函数、训练梯度等)
- 服务器接收并聚合用户的局部模型参数,利用聚合后的模型参数更新全局模型,以此实现联邦忘却学习。

(Forsaken–UPGA-- EWC-SGA)
- 面向局部模型算法比较
面向局部模型的联邦忘却学习算法通过对用户上传的局部模型参数或用户本地训练的梯度进行修改,利用模型聚合修改全局模型参数,从而实现联邦忘却学习。
训练更新校正算法:需要占用较大的空间,并且遗忘效果较差,但适用更多类型的模型
训练梯度校正算法:占用空间较少,稳定性较高,并且支持所有的忘却学习请求,因为大部分的计算工作是在用户本地进行的,服务器只需要进行聚合操作就可以实现忘却学习。
- 3.3联邦忘却学习算法对比

- 面向全局模型的联邦忘却学习算法虽然能够有效地删除目标用户对全局模型的训练更新,但模型准确性会在短时间内大幅降低,而且恢复后的模型难以在短时间达到撤销模型更新之前的映射效果。局部参数调整方法可以利用模型的结构信息和训练产生数据信息,因此在特定的模型上往往表现出良好的忘却学习效果。
- 面向局部模型的联邦忘却学习算法利用模型训练产生的数据信息,在此基础上通过训练实现联邦忘却。因此面向局部模型的联邦忘却学习算法可以防止模型准确率的急剧下降。
- 未来展望
- 不同机器学习任务的目标不同,所要求的忘却性能、忘却请求也不同,因此需要设计一个泛化高效的联邦忘却学习算法。
- 现阶段,局部参数调整的思想只能在面向全局模型的方法中使用,这样直接操作全局模型参数可能会损失模型参数之间的关键信息,进而影响全局模型的准确率。可以将局部参数调整的思想引入到面向局部模型算法中,用户通过本地训练过程来调整局部模型的参数。
- 建立联邦忘却学习和忘却学习验证的体系旨在确认特定数据的训练更新是否已成功地从模型中移除
- 总结
联邦学习模型在训练过程中保留了用户数据的记忆,攻击者可以利用模型推断数据等方法窃取用户隐私,并攻击联邦学习模型。文章来源:https://www.toymoban.com/news/detail-838769.html
进而影响全局模型的准确率。可以将局部参数调整的思想引入到面向局部模型算法中,用户通过本地训练过程来调整局部模型的参数。
3. 建立联邦忘却学习和忘却学习验证的体系旨在确认特定数据的训练更新是否已成功地从模型中移除
- 总结
联邦学习模型在训练过程中保留了用户数据的记忆,攻击者可以利用模型推断数据等方法窃取用户隐私,并攻击联邦学习模型。
联邦忘却学习通过撤销用户数据对联邦学习模型训练,进一步保护联邦学习的用户隐私和模型安全。文章来源地址https://www.toymoban.com/news/detail-838769.html
到了这里,关于论文阅读---联邦忘却学习研究综述的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!