SpringBoot 整合 Spring Data Elasticsearch
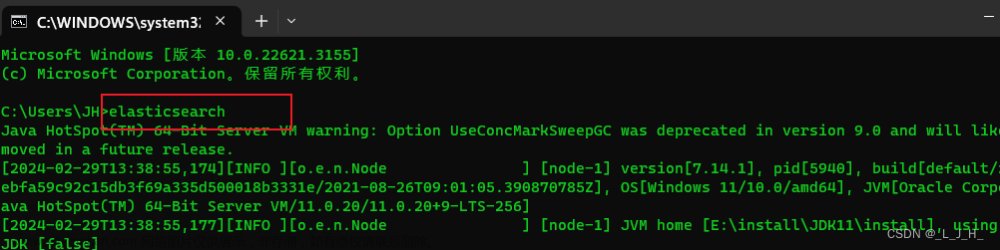
启动命令行窗口,执行:elasticsearch 命令即可启动 Elasticsearch 服务器
三种查询方式解释:
方法名关键字查询: 就是全自动查询,只要按照规则来定义查询方法 ,Spring Data Elasticsearch 就会帮我们生成对应的查询语句,并且生成方法体。
@Query 查询 : 就是半自动查询, 按照 Spring Data Elasticsearch 所要求的规则来定义查询语句,那么 Spring Data Elasticsearch 就会为其生成查询方法。
自定义查询: 就是全手动查询,就是自己写完整的查询方法。
ElasticsearchRestTemplate(ReactiveElasticsearchTemplate) 介绍
若类加载路径下有 Spring Data Elasticsearch 依赖,
Spring Boot 就会在容器中自动配置一个 ElasticsearchRestTemplate(传统的、非反应式的同步的API)
若类加载路径下有 Spring Data Elasticsearch 和 Spring WebFlux 的依赖,
Spring Boot会在容器中自动配置一个 ReactiveElasticsearchTemplate(基于 Reactive 反应式的异步的API)

ElasticsearchRestTemplate 底层依赖于容器中自动配置的 RestHighLevelClient
( RestHighLevelClient 是 Elasticsearch 官方提供的),
ReactiveElasticsearchTemplate 底层依赖于容器中自动配置的 ReactiveElasticsearchClient。
( ReactiveElasticsearchClient 是 Spring Data Elastic提供的)
【备注】
Elasticsearch 官方并未提供反应式的 RestClient :
因此 Spring Data Elasticsearch 额外补充了一个 ReactiveElasticsearchClient,用于提供反应式API支持,
ReactiveElasticsearchClient 相当于 RestHighLevelClient 的反应式版本,因此它们二者的功能基本相似。
与 RestHighLevelClient、ReactiveElasticsearchClient相比,
ElasticsearchRestTemplate、 ReactiveElasticsearchTemplate 能以更面向对象的方法来操作 Elasticsearch 索引库,这些 XxxTemplate 方法操作的是数据类的对象。
而 RestHighLevelClient、ReactiveElasticsearchClient 依然是面向 Elasticsearch 的索引库、文档编程。
Spring Data Elasticsearch 的功能
Spring Data Elasticsearch 大致包括如下几方面功能:
1、DAO 接口只需继承 CrudRepository 或 ReactiveCrudRepository ,Spring Data Elasticsearch 能为 DAO 组件提供实现类。
2、Spring Data Elasticsearch 支持方法名关键字查询,只不过 Elasticsearch 查询都是全文检索查询。
3、Spring Data Elasticsearch 同样支持使用 @Query 指定查询语句,只不过此处指定的查询语句都是 JSON 格式的查询语句。
——这是因为 Elasticsearch 它需要的查询语句就是 JSON 格式。
4、Spring Data Elasticsearch 同样支持 DAO 组件添加自定义的查询方法
——通过添加额外的父接口,并为额外的该接口提供实现类,Spring Data Elasticsearch 就能该实现类中的方法“移植”到DAO组件中。
与 NoSQL 技术不同的是,Elasticsearch 属于全文检索引擎,因此无论它的方法名关键字查询也是基于全文检索的。
例如:
对于 findByName(String name) 方法,假如传入参数为 “鸣人”,
这意味着查询 name 字段中 包含“ 鸣人” 关键字的文档,
而不是查询 name 字段值 等于 “鸣人” 的文档
——此处与 Solr 是完全一样的操作。
注解(@Document 和 @Field )
Repository 操作的数据类使用 @Document 和 @Field 注解修饰。
其中 @Document 修饰的数据类映射到索引库,使用该注解时可指定如下两个常用属性:
indexName: 指定该实体映射到哪个 Index(Index在这里就是索引库)
createIndex: 指定是否根据实体类创建 Index。
@Field 修饰的属性则映射到索引文档的 Field,使用该注解时可指定如下常用属性:
name: 指定该属性映射到索引文档的哪个Field,如果不指定该属性,默认基于同名映射。
analyzer: 用这个字段指定在创建索引库时,为索引库添加哪种分词器。
searchAnalyzer: 指定对该字段执行搜索时所使用的分词器。

代码演示:
1、创建项目
创建一个springboot项目

2、添加依赖

3、配置文件

4、添加实体类

5、基于 ReactiveElasticsearchTemplate 的反应式的异步版本API
就是 Dao 组件是继承 【ReactiveCrudRepository 】这个 API 接口来实现 【方法名关键字查询】 和 【@Query查询】的。
然后【自定义查询方法】是基于 【ReactiveElasticsearchTemplate 】这个反应式的 API 实现的。
ReactiveCrudRepository 是 Spring Data 提供的接口之一,用于支持基于响应式编程模型的 CRUD(增删改查)操作,同时支持异步、非阻塞的操作。
反应式异步版本,就是演示的查询方法的返回值类型是 Flux 或者 Mono 。
一、测试类演示–方法名关键字查询 (全自动查询)
演示 Spring Data Elasticsearch 所提供的方法名关键字查询
方法名关键字查询: 就是全自动查询,只要按照规则来定义查询方法 ,Spring Data Elasticsearch 就会帮我们生成对应的查询语句,并且生成方法体。
添加 DAO 组件(继承 ReactiveCrudRepository 接口 )

1、添加文档
代码

测试结果
运行成功
查看指定索引库的所有文档信息:http://localhost:9200/books/_search

2、根据文档id删除文档
代码

测试结果
运行成功
查看指定索引库的所有文档信息:http://localhost:9200/books/_search
可以看到 id =13 和 14 的文档已经被删除了

3、普通关键字查询
对 name 在这个字段进行关键字查询
代码

测试结果

4、对关键字做正则表达式查询
对 description 这个字段的关键词做正则表达式查询,
如图:通过这个方法名关键字查询【findByDescriptionMatches】 可以看出来是对 description 这个字段的关键词进行查询。
代码

测试结果
全自动的方法名关键字查询:内部执行的查询语句如图:

5、对关键字做范围查询
对 price 这个字段,做价格的范围查询
代码

测试结果
全自动的方法名关键字查询:内部执行的查询语句如图:
6、根据 in 运算符查询
使用 in 运算符,根据集合内的id,查询出对应的文档
代码

测试结果


二、 测试类演示–@Query查询(半自动查询)
@Query 查询 : 就是半自动查询, 按照 Spring Data Elasticsearch 所要求的规则来定义查询语句,那么 Spring Data Elasticsearch 就会为其生成查询方法。
添加 DAO 组件
//指定自定义的查询语法:-------------------------------------------------------
//根据字段和关键字进行全文检索 -- ?0就是要查询的字段;?1就是要查询的关键字 ------ 不支持通配符查询
@Query("{ \"match\": { \"?0\": \"?1\" } } ")
//通过 query_string 来指定原生的 Lucene 查询语法--------支持通配符查询
//@Query("{ \"query_string\": { \"query\": \"?0:?1\" } } ")
Flux<Book> findByQuery(String field, String term);

match – 不支持通配符查询
如图,在dao组件写的查询语句中,用的是简单 match ,是不支持通配符查询的
测试类代码

测试结果

因为在用 @Query("{ “match”: { “?0”: “?1” } } ")查询时,
用的是简单 match ,是不支持通配符查询的

query_string – 支持通配符查询
dao注解这里的查询方法,把 match 改成 query_string,
通过 query_string 来指定原生的 Lucene 查询语法--------支持通配符查询

测试类代码
测试类代码还是这个

测试结果

如图: @Query("{ “query_string”: { “query”: “?0:?1” } } ") 中,
使用 query_string 就支持通配符查询了

三、测试类演示–自定义查询方法(全手动查询)
自定义查询: 就是全手动查询,就是自己写完整的查询方法。
让 DAO 接口继承自定义 DAO 接口、并为自定义 DAO 接口提供实现类,可以为 DAO 组件添加自定义查询方法。
自定义查询方法通常推荐使用 ElasticsearchRestTemplate 或 ReactiveElasticsearchTemplate 执行查询;
当然也可通过 RestHighLevelClient 或 ReactiveElasticsearchClient 来执行查询。
代码演示(使用 ReactiveElasticsearchTemplate 反应式)
自定义DAO接口
自定义DAO组件,用来实现全手动的自定义查询方法
自定义查询的方法的作用:查询一个文档内, name 字段要包含 nameTerm 这个关键字 且 description 字段要包含 descTerm 这个关键字

自定义方法的实现逻辑

BookDao 继承CustomBookDao 这个自定义的Dao接口,主要用来通过 BookDao 调用 CustomBookDao 里面的自定义查询方法
测试类方法

测试结果
name 字段里面有【忍者】这个关键字,且 description 字段里面有 【成长】 这个关键字。
符合的文档有一条

name 字段里面有【教师】这个关键字,且 description 字段里面有 【成长】 这个关键字。
符合的文档有一条
name 字段里面有【教师】这个关键字,而 description 字段里面没有 【嘿嘿嘿】 这个关键字。
符合的文档没有

有符合的条件却没有查询出文档,
如图,表示 is 这个查询语句不支持通配符查询
没查出文档,因为是要求一个文档的 name 字段要有【忍者】关键字,且 description 字段要有【首领】关键字才行
6、基于 ElasticsearchRestTemplate 的传统的、非反应式的同步版本API
就是 Dao 组件是继承 【CrudRepository】这个 API 接口来实现 【方法名关键字查询】 和 【@Query查询】的。
然后【自定义查询方法】是基于 【ElasticsearchRestTemplate 】这个反应式的 API 实现的。
上面的代码,都是演示基于Reactive 反应式的异步编程去操作 Elasticsearch 服务器,返回的都是 Flux 和 Mono 这种数据类型。
接下来演示的就是传统的、非反应式的同步编程,返回的数据就是我们熟悉的 List < Book > 集合
@EnableElasticsearchRepositories 注解介绍
@EnableElasticsearchRepositories 注解用于手动启用 Elasticsearch Repository 支持。
一旦程序显式使用该注解,那 Spring Data Elasticsearch 的 Repository 自动配置就会失效。
应用场景: 当需要连接多个 Elasticsearch 索引库时或进行更多定制时,可手动使用该注解。
使用 @EnableElasticsearchRepositories 或 @EnableReactiveElasticsearchRepositories 时也要指定如下属性:
basePackages: 指定扫描哪个包下的DAO组件(Repository组件)。
elasticsearchTemplateRef 或 reactiveElasticsearchTemplateRef:
指定基于哪个 ElasticsearchRestTemplate 或 ReactiveElasticsearchTemplate 来实现Repository组件。
由此可见,Spring Data Elasticsearch 的 Respository 组件要依赖 RestTemplate,
而不是依赖 restClient ( restClient 就是指 RestHighLevelClient 或者 ReactiveElasticsearchClient)。
异步DAO组件 修改成 同步DAO组件(非反应式)步骤
上面的反应式是异步的,现在使用传统的、非反应式的同步组件来操作 Elasticsearch 服务器。
1、改为继承 CrudRepository
2、方法返回值不再是 Flux 或 Mono,而是应该改为 List 或 数据对象。
3、实现自定义方法时,应该依赖 ElasticsearchRestTemplate,而不是 ReactiveElasticsearchTemplate
4、同步方式连接 Elasticsearch 所使用的配置信息与反应式 API 的连接方式是不同的。
代码演示
就是拷贝上面的代码,把反应式异步的改成同步的操作。
application.properties 配置文件
反应式的 API 连接 Elasticsearch 的方式和 同步的 API 连接 Elasticsearch 的方式是不一样的

SyncBookDao 方法名关键字查询和@Query查询的DAO组件
其他没变,就是返回值的数据类型改成用List集合来接收

SyncCustomBookDao 自定义查询方法的DAO组件

SyncCustomBookDaoImpl 自定义查询方法的实现类

SyncBookDaoTest 同步的测试类


同步方式测试结果
可以看出全部都测试通过文章来源:https://www.toymoban.com/news/detail-838836.html
 文章来源地址https://www.toymoban.com/news/detail-838836.html
文章来源地址https://www.toymoban.com/news/detail-838836.html
完整代码
Book 实体类
package cn.ljh.elasticsearch_boot.domain;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
//实体类-和数据库表进行映射的类就叫实体类
@Document(indexName = "books")
@Getter
@Setter
@ToString
public class Book
{
//@Id:标识这个字段为这个实体类的主键
@Id
//@Field:用于指定实体类中属性与文档字段的映射关系
@Field
private Integer id;
//使用 @Field 为字段指定 ik_max_word 和 ik_smart,是为了能通过该字段的内容来进行全文检索
//"ik_max_word" 表示索引时使用 IK 分词器的最细粒度切分; "ik_smart" 则表示搜索时使用 IK 分词器的智能分词模式
@Field(analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String name; //书名
@Field(analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String description; //内容
@Field
private Double price; //价格
//无参构造器
public Book()
{
}
//有参构造器
public Book(Integer id, String name, String description, Double price)
{
this.id = id;
this.name = name;
this.description = description;
this.price = price;
}
}
application.properties 配置文件
# --------------------基于 Reactive 反应式的异步方式连接Elasticsearch-----------------------
# 配置Elasticsearch服务器的地址
spring.data.elasticsearch.client.reactive.endpoints=127.0.0.1:9200
# 配置不使用SSL
spring.data.elasticsearch.client.reactive.use-ssl=false
# 连接超时时间
spring.data.elasticsearch.client.reactive.socket-timeout=10s
# 配置连接Elasticsearch服务器的用户名、密码
spring.data.elasticsearch.client.reactive.username=elastic
spring.data.elasticsearch.client.reactive.password=123456
# 查看 spring data elasticsearch 执行查询时的语句
logging.level.org.springframework.data.elasticsearch=debug
# --------------------传统同步方式连接Elasticsearch-----------------------
# 配置Elasticsearch服务器的地址
spring.elasticsearch.rest.uris=http://127.0.0.1:9200
# 连接超时时间
spring.elasticsearch.rest.read-timeout=10s
# 配置连接Elasticsearch服务器的用户名、密码
spring.elasticsearch.rest.username=elastic
spring.elasticsearch.rest.password=123456
反应式的异步方式代码
BookDao 异步DAO组件
package cn.ljh.elasticsearch_boot.dao;
import cn.ljh.elasticsearch_boot.domain.Book;
import org.springframework.data.elasticsearch.annotations.Query;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import reactor.core.publisher.Flux;
import java.util.List;
/**
* Book 表示操作这个实体类; Integer:表示实体类Book的主键类型是Integer
* <Book,Integer>:表示告诉 ReactiveCrudRepository 接口,对Book这个实体类进行数据库操作。
* 在 BookDao 接口中就可以直接调用 ReactiveCrudRepository 接口提供的方法来对 Book 实体进行增删改查等操作
*
* BookDao 继承CustomBookDao 这个自定义的Dao接口,主要用来通过 BookDao 调用 CustomBookDao 里面的自定义查询方法
*
* 继承 ReactiveCrudRepository 接口的 Reactive 反应式的异步编程的Dao组件
*
*/
public interface BookDao extends ReactiveCrudRepository<Book, Integer>,CustomBookDao
{
//这里使用的是响应式的API,索引返回的类型是Flux
//Spring Data Elasticsearch 所提供的方法名关键字查询---------------------------------------
//对name在这个字段进行关键字查询
Flux<Book> findByName(String term);
//对Description这个字段的关键词做正则表达式查询
Flux<Book> findByDescriptionMatches(String termPattern);
//对 price 这个字段,做价格的范围查询
Flux<Book> findByPriceBetween(double start, double end);
//使用 in 运算符,根据集合内的id,查询出对应的文档
Flux<Book> findByIdIn(List<Integer> ids);
//通过 @Query 来指定自定义的查询语法:-------------------------------------------------------
//根据字段和关键字进行全文检索 -- ?0就是要查询的字段;?1就是要查询的关键字 ------ 不支持通配符查询
// @Query("{ \"match\": { \"?0\": \"?1\" } } ")
//通过 query_string 来指定原生的 Lucene 查询语法--------支持通配符查询
@Query("{ \"query_string\": { \"query\": \"?0:?1\" } } ")
Flux<Book> findByQuery(String field, String term);
}
CustomBookDao 异步自定义DAO组件
package cn.ljh.elasticsearch_boot.dao;
import cn.ljh.elasticsearch_boot.domain.Book;
import reactor.core.publisher.Flux;
/**
* author JH 2024-02
*/
//自定义DAO接口,用来实现自定义查询方法
public interface CustomBookDao
{
//方法作用:查询一个文档内, name 字段要包含 nameTerm 这个关键字 且 description 字段要包含 descTerm 这个关键字
Flux<Book> customQuery(String nameTerm, String descTerm);
}
CustomBookDaoImpl 异步自定义DAO组件实现类
package cn.ljh.elasticsearch_boot.dao.impl;
import cn.ljh.elasticsearch_boot.dao.CustomBookDao;
import cn.ljh.elasticsearch_boot.domain.Book;
import org.springframework.data.elasticsearch.core.ReactiveElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.query.Criteria;
import org.springframework.data.elasticsearch.core.query.CriteriaQuery;
import reactor.core.publisher.Flux;
/**
* author JH 2024-02
*/
public class CustomBookDaoImpl implements CustomBookDao
{
//ReactiveElasticsearchTemplate 能以更面向对象的方法来操作 Elasticsearch 索引库
private final ReactiveElasticsearchTemplate reactiveEsTemplate;
//通过构造器完成依赖注入
public CustomBookDaoImpl(ReactiveElasticsearchTemplate reactiveEsTemplate)
{
this.reactiveEsTemplate = reactiveEsTemplate;
}
@Override
public Flux<Book> customQuery(String nameTerm, String descTerm)
{
//构建了查询条件 Criteria 对象;要求查询的 "name" 字段值为 nameTerm,且 "description" 字段值为 descTerm
Criteria criteria = new Criteria("name").is(nameTerm)
.and("description").is(descTerm);
//通过 Criteria 对象构建了 CriteriaQuery 对象,用于包装查询条件
CriteriaQuery criteriaQuery = new CriteriaQuery(criteria);
//执行全文检索查询:参数1:要执行的查询语句; 参数2:要执行的实体类型
//查询结果以 Flux<SearchHit<Book>> 的形式返回,其中 SearchHit 包含了 Elasticsearch 中查询到的相关数据
Flux<SearchHit<Book>> searchHitFlux = reactiveEsTemplate.search(criteriaQuery, Book.class);
//通过 map 操作将 SearchHit 转换为 Book 对象,最终返回一个 Flux<Book>,包含了符合查询条件的 Book 对象流
Flux<Book> bookFlux = searchHitFlux.map(bookSearchHit -> bookSearchHit.getContent());
return bookFlux;
}
}
BookDaoTest 异步DAO组件方法的测试类
package cn.ljh.elasticsearch_boot.dao;
import cn.ljh.elasticsearch_boot.domain.Book;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.CsvSource;
import org.junit.jupiter.params.provider.ValueSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.annotations.Query;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.util.List;
/**
* author JH 2024-02
*/
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
public class BookDaoTest
{
@Autowired
private BookDao bookDao;
//---------------------------方法名关键字查询方法------全自动---------------------------------------------------
//添加文档
@ParameterizedTest //参数测试
//多次测试中,每一次进行测试时需要多个参数,用这个注解
@CsvSource({
"11,火影忍者,旋涡鸣人成长为第七代火影的故事,150",
"12,家庭教师,废材纲成长为十代首领的热血事迹,200",
"13,七龙珠,孙悟空来到地球后的热闹景象,300",
"14,七龙珠Z,超级赛亚人贝吉塔来到地球后的热闹景象,400"
})
public void testSave(Integer id, String name, String description, double price)
{
Book book = new Book(id, name, description, price);
//反应式API返回的值是 Mono
Mono<Book> result = bookDao.save(book);
//反应式API,以同步阻塞的方式保证它执行完成
result.blockOptional().ifPresent(System.err::println);
}
/**
* .blockOptional(): 这是 Mono 类的方法,在 Reactor 中用于将 Mono 对象转换为一个 Optional 对象,并以阻塞的方式等待 Mono 的完成。
* 如果 Mono 成功完成并且有值,那么会返回包含该值的 Optional 对象;
* 如果 Mono 为空或者出现错误,则返回一个空的 Optional。
* 这个方法适用于需要立即获取 Mono 结果并进行后续处理的场景
*
* .blockOptional() 主要用于处理单个值的 Mono 对象,并以阻塞的方式获取结果
*/
//根据文档id删除文档
@ParameterizedTest
//多次测试中,每一次进行测试时只需要1个参数,用这个注解
@ValueSource(ints = {
13,
14
})
public void testDeleteById(Integer id)
{
//根据id删除文档的方法
bookDao.deleteById(id)
//反应式API,以同步阻塞的方式保证它执行完成
.blockOptional();
}
//对 name 在这个字段进行关键字查询
@ParameterizedTest
@ValueSource(strings = {
"忍者",
"教师"
})
public void testFindByName(String term){
Flux<Book> bookFlux = bookDao.findByName(term);
//toIterable()方法是同步的,将一个 Reactive Flux 转换为普通的 Iterable 对象;
bookFlux.toIterable()
//遍历打印
.forEach(System.err::println);
}
/**
* .toIterable(): 这是 Flux 类的方法,在 Reactor 中用于将 Flux 对象转换为一个 Iterable 对象,从而可以在同步代码中对 Flux 中的元素进行迭代遍历
* 使用 .toIterable() 方法会阻塞当前线程直到 Flux 中的所有元素都被订阅完毕,然后将这些元素包装成 Iterable 对象返回
*
* .toIterable() 主要用于处理包含多个元素的 Flux 对象,并以阻塞的方式将所有元素转换为 Iterable 对象
*/
//对description这个字段的关键词做正则表达式查询
@ParameterizedTest
@ValueSource(strings = {
// . 代表任何字符; + 代表匹配前面 . 这个字符可以出现一次到多次
//正则表达式要放在//斜杠中
"/热.+/",
"/成.+/",
"/忍.+/"
})
public void testFindByDescriptionMatches(String termPattern)
{
Flux<Book> bookFlux = bookDao.findByDescriptionMatches(termPattern);
//toIterable()方法是同步的,将一个 Reactive Flux 转换为普通的 Iterable 对象;
bookFlux.toIterable()
//遍历打印
.forEach(System.err::println);
}
//对 price 这个字段,做价格的范围查询
@ParameterizedTest
@CsvSource({
"150,200",
"200,300"
})
public void testFindByPriceBetween(double start, double end)
{
Flux<Book> bookFlux = bookDao.findByPriceBetween(start, end);
//toIterable()方法是同步的,将一个 Reactive Flux 转换为普通的 Iterable 对象;
bookFlux.toIterable()
//遍历打印
.forEach(System.err::println);
}
//使用 in 运算符,根据集合内的id,查询出对应的文档
@ParameterizedTest
@CsvSource({
"11,14",
"11,12"
})
public void testFindByIdIn(Integer id1, Integer id2)
{
Flux<Book> bookFlux = bookDao.findByIdIn(List.of(id1,id2));
//toIterable()方法是同步的,将一个 Reactive Flux 转换为普通的 Iterable 对象;
bookFlux.toIterable()
//遍历打印
.forEach(System.err::println);
}
//---------------------------@Query()查询方法------半自动---------------------------------------------------
//根据字段和关键字进行全文检索
@ParameterizedTest
@CsvSource({
"description,成长",
"description,热*"
})
public void testFindByQuery(String field, String term)
{
Flux<Book> bookFlux = bookDao.findByQuery(field, term);
//toIterable()方法是同步的,将一个 Reactive Flux 转换为普通的 Iterable 对象;
bookFlux.toIterable()
//遍历打印
.forEach(System.err::println);
}
//---------------------------自定义查询方法----全手动-----------------------------------------------------
//方法作用:查询 name 字段要包含 nameTerm 这个关键字 和 description 字段要包含 descTerm 这个关键字
@ParameterizedTest
@CsvSource({
//查询要求 name 字段里面有【忍者】这个关键字,且 description 字段里面有 【成长】 这个关键字
"忍者,成长",
"教师,成长",
"教师,嘿嘿嘿",
"忍者,成*",
"忍者,首领"
})
public void testCustomQuery(String nameTerm, String descTerm)
{
Flux<Book> bookFlux = bookDao.customQuery(nameTerm, descTerm);
bookFlux.toIterable().forEach(System.err::println);
}
}
传统的同步方式代码
SyncBookDao 同步DAO组件
package cn.ljh.elasticsearch_boot.dao;
import cn.ljh.elasticsearch_boot.domain.Book;
import org.springframework.data.elasticsearch.annotations.Query;
import org.springframework.data.repository.CrudRepository;
import reactor.core.publisher.Flux;
import java.util.List;
/**
* Book 表示操作这个实体类; Integer:表示实体类Book的主键类型是Integer
* <Book,Integer>:表示告诉 eCrudRepository 接口,对Book这个实体类进行数据库操作。
* 在 BookDao 接口中就可以直接调用 CrudRepository 接口提供的方法来对 Book 实体进行增删改查等操作
*
* BookDao 继承CustomBookDao 这个自定义的Dao接口,主要用来通过 BookDao 调用 CustomBookDao 里面的自定义查询方法
*
*
* 继承 CrudRepository 接口的传统的、非反应式的同步的Dao组件,
*
*/
public interface SyncBookDao extends CrudRepository<Book, Integer>, SyncCustomBookDao
{
//Spring Data Elasticsearch 所提供的方法名关键字查询---------------------------------------
//对name在这个字段进行关键字查询
List<Book> findByName(String term);
//对Description这个字段的关键词做正则表达式查询
List<Book> findByDescriptionMatches(String termPattern);
//对 price 这个字段,做价格的范围查询
List<Book> findByPriceBetween(double start, double end);
//使用 in 运算符,根据集合内的id,查询出对应的文档
List<Book> findByIdIn(List<Integer> ids);
//通过 @Query 来指定自定义的查询语法:-------------------------------------------------------
//根据字段和关键字进行全文检索 -- ?0就是要查询的字段;?1就是要查询的关键字 ------ 不支持通配符查询
// @Query("{ \"match\": { \"?0\": \"?1\" } } ")
//通过 query_string 来指定原生的 Lucene 查询语法--------支持通配符查询
@Query("{ \"query_string\": { \"query\": \"?0:?1\" } } ")
List<Book> findByQuery(String field, String term);
}
SyncCustomBookDao 同步自定义DAO组件
package cn.ljh.elasticsearch_boot.dao;
import cn.ljh.elasticsearch_boot.domain.Book;
import reactor.core.publisher.Flux;
import java.util.List;
/**
* author JH 2024-02
*/
//自定义DAO接口,用来实现自定义查询方法
public interface SyncCustomBookDao
{
//方法作用:查询一个文档内, name 字段要包含 nameTerm 这个关键字 且 description 字段要包含 descTerm 这个关键字
List<Book> customQuery(String nameTerm, String descTerm);
}
SyncCustomBookDaoImpl 同步自定义DAO组件实现类
package cn.ljh.elasticsearch_boot.dao.impl;
import cn.ljh.elasticsearch_boot.dao.CustomBookDao;
import cn.ljh.elasticsearch_boot.dao.SyncCustomBookDao;
import cn.ljh.elasticsearch_boot.domain.Book;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.Criteria;
import org.springframework.data.elasticsearch.core.query.CriteriaQuery;
import java.util.ArrayList;
import java.util.List;
/**
* author JH 2024-02
*/
public class SyncCustomBookDaoImpl implements SyncCustomBookDao
{
//ElasticsearchRestTemplate 能以更面向对象的方法来操作 Elasticsearch 索引库
private final ElasticsearchRestTemplate esRestTemplate;
//通过构造器完成依赖注入
public SyncCustomBookDaoImpl(ElasticsearchRestTemplate esRestTemplate)
{
this.esRestTemplate = esRestTemplate;
}
@Override
public List<Book> customQuery(String nameTerm, String descTerm)
{
//构建了查询条件 Criteria 对象;要求查询的 "name" 字段值为 nameTerm,且 "description" 字段值为 descTerm
Criteria criteria = new Criteria("name").is(nameTerm)
.and("description").is(descTerm);
//通过 Criteria 对象构建了 CriteriaQuery 对象,用于包装查询条件
CriteriaQuery criteriaQuery = new CriteriaQuery(criteria);
//执行全文检索查询:参数1:要执行的查询语句; 参数2:要执行的实体类型
//search方法的返回值是 SearchHit<Book> ,该 API 带了s,相当于是一个集合
SearchHits<Book> searchHits = esRestTemplate.search(criteriaQuery, Book.class);
List<Book> bookList = new ArrayList<>();
//bookSearchHit 的类型是 SearchHit<Book>
searchHits.forEach(bookSearchHit -> bookList.add(bookSearchHit.getContent()));
return bookList;
}
}
SyncBookDaoTest 同步DAO组件方法的测试类
package cn.ljh.elasticsearch_boot.dao;
import cn.ljh.elasticsearch_boot.domain.Book;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.CsvSource;
import org.junit.jupiter.params.provider.ValueSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.util.List;
/**
* author JH 2024-02
*/
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.NONE)
public class SyncBookDaoTest
{
@Autowired
private SyncBookDao syncBookDao;
//---------------------------方法名关键字查询方法------全自动---------------------------------------------------
//添加文档
@ParameterizedTest //参数测试
//多次测试中,每一次进行测试时需要多个参数,用这个注解
@CsvSource({
"21,火影忍者,旋涡鸣人成长为第七代火影的故事,150",
"22,家庭教师,废材纲成长为十代首领的热血事迹,200",
"23,七龙珠,孙悟空来到地球后的热闹景象,300",
"24,七龙珠Z,超级赛亚人贝吉塔来到地球后的热闹景象,400"
})
public void testSave(Integer id, String name, String description, double price)
{
Book book = new Book(id, name, description, price);
Book b = syncBookDao.save(book);
System.err.println(b);
}
//根据文档id删除文档
@ParameterizedTest
//多次测试中,每一次进行测试时只需要1个参数,用这个注解
@ValueSource(ints = {
13,
14
})
public void testDeleteById(Integer id)
{
//根据id删除文档的方法
syncBookDao.deleteById(id);
}
//对 name 在这个字段进行关键字查询
@ParameterizedTest
@ValueSource(strings = {
"忍者",
"教师"
})
public void testFindByName(String term)
{
List<Book> books = syncBookDao.findByName(term);
books.forEach(System.err::println);
}
//对description这个字段的关键词做正则表达式查询
@ParameterizedTest
@ValueSource(strings = {
// . 代表任何字符; + 代表匹配前面 . 这个字符可以出现一次到多次
//正则表达式要放在//斜杠中
"/热.+/",
"/成.+/",
"/忍.+/"
})
public void testFindByDescriptionMatches(String termPattern)
{
List<Book> books = syncBookDao.findByDescriptionMatches(termPattern);
books.forEach(System.err::println);
}
//对 price 这个字段,做价格的范围查询
@ParameterizedTest
@CsvSource({
"150,200",
"200,300"
})
public void testFindByPriceBetween(double start, double end)
{
List<Book> books = syncBookDao.findByPriceBetween(start, end);
books.forEach(System.err::println);
}
//使用 in 运算符,根据集合内的id,查询出对应的文档
@ParameterizedTest
@CsvSource({
"11,14",
"11,12"
})
public void testFindByIdIn(Integer id1, Integer id2)
{
List<Book> books = syncBookDao.findByIdIn(List.of(id1, id2));
books.forEach(System.err::println);
}
//---------------------------@Query()查询方法------半自动---------------------------------------------------
//根据字段和关键字进行全文检索
@ParameterizedTest
@CsvSource({
"description,成长",
"description,热*"
})
public void testFindByQuery(String field, String term)
{
List<Book> books = syncBookDao.findByQuery(field, term);
books.forEach(System.err::println);
}
//---------------------------自定义查询方法----全手动-----------------------------------------------------
//方法作用:查询 name 字段要包含 nameTerm 这个关键字
// 且 description 字段要包含 descTerm 这个关键字
@ParameterizedTest
@CsvSource({
//查询要求 name 字段里面有【忍者】这个关键字,
// 且 description 字段里面有 【成长】 这个关键字
"忍者,成长",
"教师,成长",
"教师,嘿嘿嘿",
"忍者,成*",
"忍者,首领"
})
public void testCustomQuery(String nameTerm, String descTerm)
{
List<Book> books = syncBookDao.customQuery(nameTerm, descTerm);
books.forEach(System.err::println);
}
}
pom.xml 依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.3</version>
</parent>
<groupId>cn.ljh</groupId>
<artifactId>elasticsearch_boot</artifactId>
<version>1.0.0</version>
<name>elasticsearch_boot</name>
<properties>
<java.version>11</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- 这个依赖会传递依赖 elasticsearch Client -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
到了这里,关于18、全文检索--Elasticsearch-- SpringBoot 整合 Spring Data Elasticsearch(异步方式(Reactive)和 传统同步方式 分别操作ES的代码演示)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!