🔥博客主页: 小羊失眠啦.
🎥系列专栏:《C语言》 《数据结构》 《C++》 《Linux》 《Cpolar》
❤️感谢大家点赞👍收藏⭐评论✍️

思考:
1、cache的entry里都是有什么?
2、TLB的entry里都是有什么?
3、MMU操作的页表中的entry中都是有什么? L1和L3表中的entry中分别都是有什么?
本文已有答案,学完之后,你能否知道,看造化了,哈哈….
说明:
MMU/TLB/Cache等知识太过于零碎,各个模块直接又紧密相关,所以在介绍时会串着介绍,本文旨在介绍MMU的工作原理,学习cache请参考<ARM cache的学习笔记-一篇就够了)>以下来自笨叔叔公众号中的提问:
1、cache的内部组织架构是怎么样的?能否画出一个cache的layout图?什么是set,way?
2、直接映射,全关联和组相联之间有什么区别?优缺点是啥?
3、重名问题是怎么发生的?
4、同名问题是怎么发生的?
5、VIPT会不会发生重名问题?
6、什么是inner shareability 和outer shareability?怎么区分?
7、什么是PoU?什么是PoC?
8、什么是cache一致性?业界解决cache一致性都有哪些方法?
9、MESI状态转换图,我看不懂。
10、什么cache伪共享?怎么发生的,如何避免?
11、DMA和cache为啥会有cache一致性问题?
12、网卡通过DMA收数据和发数据,应该怎么操作cache?
13、对于self-modifying code,怎么保证data cache和指令cache的一致性问题?
本文转自 周贺贺,baron,代码改变世界ctw,Arm精选, 资深安全架构专家,11年手机安全/SOC底层安全开发经验。擅长trustzone/tee安全产品的设计和开发。
一、Memory attribute
armv8定义了device memory和normal memory两种内存,其中device memory固定的就是Outer-Shareable和Non-cacheable,而normal memory有多种属性可选。
说明一下:在B2.7.2章节中有这么一句话“Data accesses to memory locations are coherent for all observers in the system, and correspondingly are treated as being Outer Shareable”, treated as被看作是(但不是),所以在一些的文章中就认为device memory是没有shareable属性的。其实也能够理解,一段memory设置成了non-cacheable,然后再去讨论该memory的shareable属性,好像也没有意义。 不管怎么样,我们还是按照下方表格的来理解吧,device memory固定为Outer-Shareable和Non-cacheable

对于device memory,又分下面三种特性:
➨Gathering和non Gathering(G or nG):表示对多个memory的访问是否可以合并,如果是nG,表示处理器必须严格按照代码中内存访问来进行,不能把两次访问合并成一次。例如:代码中有2次对同样的一个地址的读访问,那么处理器必须严格进行两次read transaction
➨Reordering(R or nR):表示是否允许处理器对内存访问指令进行重排。nR表示必须严格执行program order
➨Early Write Acknowledgement(E or nE):PE访问memory是有问有答的(更专业的术语叫做transaction),对于write而言,PE需要write ack操作以便确定完成一个write transaction。为了加快写的速度,系统的中间环节可能会设定一些write buffer。nE表示写操作的ack必须来自最终的目的地而不是中间的write buffer
针对上面的三种特性,给出下面四种配置
- Device-nGnRnE : 处理器必须严格按照代码中内存访问来进行、必须严格执行program order(无需重排序)、写操作的ack必须来自最终的目的地
- Device-nGnRE : 处理器必须严格按照代码中内存访问来进行、必须严格执行program order(无需重排序)、写操作的ack可以来自中间的write buffer
- Device-nGRE : 处理器必须严格按照代码中内存访问来进行、内存访问指令可以进行重排、写操作的ack可以来自中间的write buffer
- Device-GRE : 处理器对多个memory的访问是否可以合并、内存访问指令可以进行重排、写操作的ack可以来自中间的write buffer
| 部分属性的含义 | |
|---|---|
| Shareable | 内存是共享的 |
| non-Shareable | 内存不共享,一般只可被单个PE访问 |
| cacheable | 内存会被缓存 |
| non-cacheable | 内存不会被缓存 |
PoU/PoC/Inner/Outer的定义
简而言之,PoU/PoC定义了指令和命令的所能抵达的缓存或内存,在到达了指定地点后,Inner/Outer Shareable定义了它们被广播的范围。
例如:在某个A15上执行Clean清指令缓存,范围指定PoU。显然,所有四个A15的一级指令缓存都会被清掉。那么其他的各个Master是不是受影响?那就要用到Inner/Outer/Non Shareable



有了上面的这些定义,那么我们再来看inner Shareable和outer Shareable
| Shareable | |
|---|---|
| inner Shareable | 内存在inner范围内是共享的 |
| outer Shareable | 内存在outer范围内是共享的 |
读分配(read allocation)
当CPU读数据时,发生cache缺失,这种情况下都会分配一个cache line缓存从主存读取的数据。默认情况下,cache都支持读分配。
写分配(write allocation)
当CPU写数据发生cache缺失时,才会考虑写分配策略。当我们不支持写分配的情况下,写指令只会更新主存数据,然后就结束了。当支持写分配的时候,我们首先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache line中的数据。
写直通(write through)
当CPU执行store指令并在cache命中时,我们更新cache中的数据并且更新主存中的数据。cache和主存的数据始终保持一致。
写回(write back)
当CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit(翻翻前面的图片,cache line旁边有一个D就是dirty bit)。我们会将dirty bit置位。主存中的数据只会在cache line被替换或者显示的clean操作时更新。因此,主存中的数据可能是未修改的数据,而修改的数据躺在cache中。cache和主存的数据可能不一致。

➨ 在ARMV8定义这些属性的寄存器和linux kernel或optee软件代码中使用的示例,请点击此处
二、cache的一些基本概念
cache是一个高速的内存块,它包含了很多entries,每一个entrie中都包含: memory地址信息(如tag)、associated data
cache的设计考虑了两大原则:
空间域(spatial locality): 访问了一个位置后,可能还会访问相邻区域, 如顺序执行的指令、访问一个结构体数据
时间域(Temporal locality):内存区域的访问很可能在短时间内重复,如软件中执行了一个循环操作.
为了减少cache读写的次数,将多个数据放到了同一个tag下,这就是我们所说的cache line
访问缓存中已经存在的信息叫做cache hit,访问缓存中不存在的数据叫做cache miss
cache引入的潜在问题:
内存的访问不一定同编程者预期的一样;
一个数据可以存在多个物理位置处
三、Cache内存访问的模型:

Memory coherency的术语定义:
Point of Unification (PoU), Point of Coherency (PoC), Point of Persistence (PoP), and Point of Deep Persistence (PoDP).
四、MMU的介绍
在ARMV8-aarch64体系下,ARM Core访问内存的硬件结构图如下所示:

其中,MMU由TLB和Table Walk Unit组成的.
TLB:Translation Lookaside Buffer (TLB),对应着TLB指令
Table Walk Unit,也叫地址翻译,address translation system,对应着AT指令
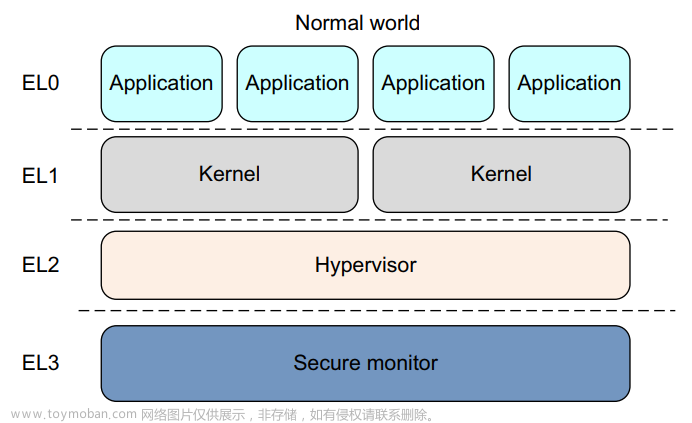
五、VMSA 相关术语:
➨ VMSA - Virtual Memory System Architecture
➨VMSAv8
➨VMSAv8-32
➨VMSAv8-64
➨Virtual address (VA)
➨Intermediate physical address (IPA)
➨Physical address (PA)
Translation stage can support only a single VA range
➨48-bit VA, 0x0000000000000000 to 0x0000FFFFFFFFFFFF
➨ARMv8.2-LVA : 64KB granule :52-bit VA,0x0000000000000000 to 0x000FFFFFFFFFFFFF
Translation stage can support two VA ranges
➨48-bit VA: 0x0000000000000000 - 0x0000FFFFFFFFFFFF , 0xFFFF000000000000 to 0xFFFFFFFFFFFFFFFF
➨52-bit VA: 0x0000000000000000 - 0x000FFFFFFFFFFFFF , 0xFFF0000000000000 to 0xFFFFFFFFFFFFFFFF
Address tagging / Memory Tagging Extension / Pointer authentication
六、address translation system (AT)
6.1 地址翻译的过程
MMU的地址翻译工作是一种自动行为,当填好页表、配置好系统寄存器之后,cpu发起的虚拟地址读写操作,将会经过MMU自动转换成物理地址,然后发送到AXI总线上完成真正的内存或device的读写操作. 如下列举了ARM在不同exception level中的地址翻译的模型.

在一般的情况下,我们是不会启用stage2的,除非enable了EL2、实现了hypervisor,那么这时候才会开启stage2,如下图所示:

6.2 和mmu相关的System registers

在armv8-aarch64体系下,TCR(Translation Control Register)寄存器有
- TCR_EL1
- TCR_EL2
- TCR_EL3
- VTCR_EL2
它们的含义:地址翻译的控制寄存器
-
TCR_EL1, Translation Control Register (EL1)
The control register for stage 1 of the EL1&0 translation regime. -
TCR_EL3, Translation Control Register (EL3)
The control register for stage 1 of the EL3 translation regime -
TCR_EL2, Translation Control Register (EL2)
The control register for stage 1 of the EL2, or EL2&0, translation regime -
VTCR_EL2, Virtualization Translation Control Register
The control register for stage 2 of the EL1&0 translation regime
对应的bit map为

6.3 Enable mmu and endianness的相关寄存器

在ARMV8-aarch64架构下有三个sctlr寄存器
- SCTLR_EL1
- SCTLR_EL2
- SCTLR_EL3
以SCTLR_EL3,该系统寄存器的SCTLR_EL3.EE(BIT[25])定义了MMU访问页表的方式:小端方式读、还是大端方式读

6.4 Address size configuration
- Physical address size – 告诉cpu,当前系统的物理地址是多少位
- Output address size – 告诉mmu,你需要给我输出多少位的物理地址
- Input address size – 告诉mmu,我输入的是多数为的虚拟地址
- Supported IPA size – stage2页表转换的部分size,暂不介绍
. Physical address size

b. output address size

c . Input address size
- TCR_ELx.T0SZ定义使用TTBR0_ELx时,VA地址的size
- TCR_ELx.T1SZ定义使用TTBR1_ELx时,VA地址的size

注意最大的size为:2^(64-x),x为TCR_ELx.T0SZ或TCR_ELx.T1SZ
d. Supported IPA size
由VTCR_EL2.SL0 and VSTCR_EL2.SL0寄存器决定
6.5 granule sizes
a. state 1 granule sizes

b. state 2 granule sizes

6.6 granule size对地址翻译的影响
granule size的配置不同,将会影响到页表的建立,不同的granule size的页面有着不同的页表结构,例如下表所示的:

6.7 disable mmu
disable mmu之后,the stage 1 translation,For the EL1&0:
For Normal memory, Non-shareable, Inner Write-Back Read-Allocate Write-Allocate, Outer Write-Back Read-Allocate Write-Allocate memory attributes
七、Translation table
7.1 TTBR0/TTBR1
ARM文档说:因为应用程序切换时要切换页表,页表经常改变,而kernel切换时不需要切换页表,页表几乎不改。所以ARM就提供了 a number of features,也就是TTBR0和TTBR1两个页表基地址. TTBR0用于0x00000000_00000000 - 0x0000FFFF_FFFFFFFF虚拟地址空间的翻译,TTBR1用于0xFFFF0000_00000000 - 0xFFFFFFFF_FFFFFFFF虚拟地址空间的翻译
EL2/EL3只有TTBR0,没有TTBR1,所以EL2/EL3的虚拟地址空间是:0x0000FFFF_FFFFFFFF
7.2 页表的entry中包含哪些信息
MMU除了完成地址的翻译,还控制的访问权限、memory ordering、cache policies.
如图所示,列出了三种类型的entry信息:

bits[1:0]表示该输出是block address,还是next level table address,还是invalid entry
7.3 granule sizes
有三种granule sizes的页表:4kb、16kb、64kb

7.4 Cache configuration
MMU使用translation tables 和 translation registers控制着cache policy、memory attributes、access permissions、va到pa的转换
八、ARM mmu三级页表查询的过程

- (1)、在开启MMU后,cpu发起的读写地址是一个64bit的虚拟地址,
- (2)、该虚拟地址的高16bit要么是全0,要么是全1. 如果是全0,则选择TTBR0_ELx做为L1页表的基地址; 如果是全1,则选择TTBR1_ELx做为L1页表的基地址;
- (3)、TTBRx_ELn做为L1页表,它指向L2页表,在根据bit[41:29]的index,查询到L3页表的基地址
- (4)(5)、有了L3页表的基地址之后,在根据bit[28:16]的index,查询到页面的地址
- (6)、最后再根据bit[15:0]查找到最终的物理地址
九、Translation Lookaside Buffer (TLB)
9.1 TLB entry里有什么?
TLB中不仅仅包含物理地址和虚拟地址,它还包含一些属性,例如:memory type、cache policies、access permissions、ASID、VMID
注:ASID - Address Space ID, VMID - Virtual Machine ID
9.2 contiguous block entries
TLB拥有固定数目的entries,所以你可以通过减少外部内存地址转换的次数来提升TLB hit率.
在ARMV8 architecture中有一个TLB中的feature叫contiguous block entries,它表示一个entry可以对应多个blocks. 一个entry找到多个blocks,再通过index来查找具体是哪个block。 页表的block entries中,也有一个contiguous bit。这个bit为1,则表示开启了TLB的contiguous block entries feature。
contiguous block entries feature要求alignment,例如:
• 16 × 4KB adjacent blocks giving a 64KB entry with 4KB granule. 缓存64kb blocks,只需16 enties
• 32 × 32MB adjacent blocks giving a 1GB entry for L2 descriptors, 128 × 16KB giving a 2MB entry for L3 descriptors when using a 16KB granule.
• 32 × 64Kb adjacent blocks giving a 2MB entry with a 64KB granule.
如果支持了contiguous bit,那么:
TLB查询后的PA = TLB entry中的PA + index。
9.3 TLB abort
如果开启了contiguous bit,而要转换的table entries确不是连续的,或者entries的output在地址范围之外或没有对齐,那么将会产生TLB abort
9.4 TLB一致性
如果os修改了页表(entries),那么os需要告诉TLB,invalid这些TLB entries,这是需要软件来做的. 指令如下:
TLBI <type><level>{IS} {, <Xt>}
十、VMSAv8-64 translation table format descriptors
这里的table format descriptors,其实就是本文开头“思考”中提到的entry,在页表中的entry, 要么是invalid,要么是table entry,要么是block entry
- An invalid or fault entry.
- A table entry, that points to the next-level translation table.
- A block entry, that defines the memory properties for the access.
- A reserved format
如果是table entry,其attribute描述如下:

如果是block entry,其attribute描述如下:

如果是stage2的entry,无论是table entry还是block entry,其attribute描述如下:

其实用如下的一张图来描述更清晰:

这里的bit[1:0]用于定义entry的类型(invalid? block ? table? reserved)
bit[4:2]指向 MAIR_ELn寄存器中的其中的一个字节,用于定义内存(main memory和device memory)的类型
MAIR_ELn寄存器拆分成8个bytes,每个byte定义一种内存类型
(MAIR_ELn, Memory Attribute Indirection Register (ELn))

每一个byte(attrn)的含义如下:

各个bit位的具体含义

例如optee中的内存属性配置如下:文章来源:https://www.toymoban.com/news/detail-838874.html
#define ATTR_DEVICE_INDEX 0x0
#define ATTR_IWBWA_OWBWA_NTR_INDEX 0x1
#define ATTR_INDEX_MASK 0x7
#define ATTR_DEVICE (0x4)
#define ATTR_IWBWA_OWBWA_NTR (0xff)
mair = MAIR_ATTR_SET(ATTR_DEVICE, ATTR_DEVICE_INDEX);
mair |= MAIR_ATTR_SET(ATTR_IWBWA_OWBWA_NTR, ATTR_IWBWA_OWBWA_NTR_INDEX);
write_mair_el1(mair);
推荐
- ARMv8/ARMv9架构从入门到精通 --博客专栏
- 《Armv8/Armv9架构从入门到精通 第二期》 --大课程
- 8天入门ARM架构 --入门课程
 文章来源地址https://www.toymoban.com/news/detail-838874.html
文章来源地址https://www.toymoban.com/news/detail-838874.html
到了这里,关于ARMV8-aarch64的虚拟内存(mmutlbcache)介绍-概念扫盲的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![Yocto系列讲解[技巧篇]92 - armv8 aarch64兼容armv7 32位程序运行环境](https://imgs.yssmx.com/Uploads/2024/01/820513-1.png)