安装环境
运行环境为
windows
R9000P2021拯救者笔记本
AMD R7-5800H
32G 内存
NVIDIA RTX 3070 Laptop GPU
安装主程序
Ollama下载exe,直接下一步下一步没有设置可以更改
windows默认安装路径:C:\Users\wbigo\AppData\Local\Programs\Ollama\
安装后会自动将该路径加入环境变量
双击图标运行后状态栏会出现小图标,右键有退出、打开日志文件夹按钮
我直接打开cmd运行ollama list报错、应该是环境变量有问题
这时可以打开安装路径按住shift+鼠标右键,点击在此处打开Powershell窗口
输入ollama -v查看当前版本,能输出版本则安装成功
修改模型下载路径
默认模型下载路径:C:\Users\wbigo\.ollama\models
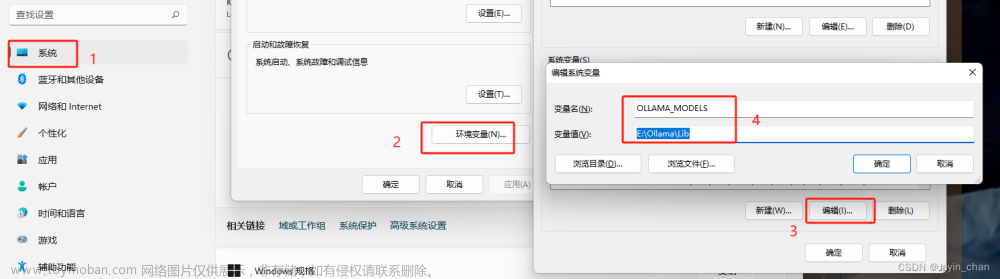
添加系统变量修改模型默认下载路径
变量名:OLLAMA_MODELS
运行模型单行对话
拉取并运行llama2模型ollama run llama2
直接输入该命令会检查目录下是否有该模型,没有会自动下载,下载好后自动运行该模型
其他模型见library (ollama.com)

拉取完成后直接进入单行交流模式

第三方API调用
API调用默认端口11434
第三方应用调用API
翻译效果 文章来源:https://www.toymoban.com/news/detail-839084.html
文章来源:https://www.toymoban.com/news/detail-839084.html
解释代码效果及CPU、内存、GPU占用 文章来源地址https://www.toymoban.com/news/detail-839084.html
文章来源地址https://www.toymoban.com/news/detail-839084.html
到了这里,关于小白Windows下通过Ollama部署使用本地模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!