学习建议
- 现在很多网站、小程序、应用软件、博客、电商购物平台等,都有很多的用户评论数据,这些数据包含了用户对产品的认知、看法和一些立场;
- 那么我们可以对这些数据进行情感分析,可以得到一些有价值的信息,帮助我们进一步提升产品价值或用户体验;
- 本文主要针对某个博客的评论数据进行分析,分析用户的情感变化,包括正面的、负面的情绪变化等;
- 学习本文建议对Python的SnowNLP第三库有一定的了解,另外对Python的excel数据处理相关库有一些基础认知,比如pandas库、matplotlib库等等。
SnowNLP基础
什么是SnowNLP?
在学习前,我们先了解下什么是SnowNLP?
- SnowNLP是Python的第三方模块或者库;
- SnowNLP主要作用是可实现对评论内容的情感预测。
SnowNLP情感分析
- SnowNLP可友好的处理中文内容,包括中文分词、文本分类、提取文本关键词、文本相似度计算、情感分析等;
- 而针对情感分析,分析完成后可得到概率,从概率我们可以得出哪些是正面评论,哪些是负面评论;
- 情感分析中,概率大于0.5视为正面评价(积极情感),概率小于0.5视为负面评价(消极情感)。
SnowNLP使用
在进行实战之前,我们了解一些SnowNLP的简单使用,可对后续我们数据分析有一定的帮助。下边简单举几个例子,帮助大家理解SnowNLP的作用。
SnowNLP安装
直接使用pip安装即可:
pip install snownlp
情感分析
- 情感分析会对评价的正面和负面评价进行分析,大于0.5为正面,否则为负面;
# -*- coding:utf-8 -*-
# 作者:虫无涯
# 日期:2024/3/12
# 文件名称:test_snlp.py
# 作用:snownlp使用-情感分析
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "snownlp"])
from snownlp import SnowNLP
text = "我篇文章内容丰富、条理清晰,让我学到了很多~~~"
s = SnowNLP(text)
# 情感分析
sentiment = s.sentiments
if sentiment > 0.5:
print('正面评价')
else:
print('负面评价')
# 输出为:正面评价
中文分词
- 中文分析主要是对一句话进行分解,把整个语句分割成单个词语和汉字;
# -*- coding:utf-8 -*-
# 作者:虫无涯
# 日期:2024/3/12
# 文件名称:test_snlp.py
# 作用:snownlp使用-中文分词
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "snownlp"])
from snownlp import SnowNLP
data = "如果我有一个亿,我会不会飘?"
s = SnowNLP(data)
print(s.words)
# 输出:
# ['如果', '我', '有', '一个', '亿', ',', '我', '会', '不', '会', '飘', '?']
关键词提取
- 可以设置需要提取的关键词个数,然后输出对应的药提取的关键词;
# -*- coding:utf-8 -*-
# 作者:虫无涯
# 日期:2024/3/12
# 文件名称:test_snlp.py
# 作用:snownlp使用-关键词提取
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "snownlp"])
from snownlp import SnowNLP
text = "这是一篇关于Python数据处理的博客文章,主要介绍Python中SnowNLP库的使用方法以及实战。"
s = SnowNLP(text)
keywords = s.keywords(3) # 提取前3个关键词
print('关键词:', keywords)
# 输出为:关键词: ['Python', '库', 'SnowNLP']
拼音、词性标准
- 这个就不多介绍了,详细可以去看看SnowNLP的使用。
SnowNLP实战-博客评论数据的情感分析
数据准备
- 我们需要提供一组博客评论数据,然后进行分析;
- 数据建议可以放入excel中,方便分析,本文为了代码运行方面,后续会放置在变量中;
- 数据如下:
| 类别 | 博客名称 | 时间 | 评价内容 |
|---|---|---|---|
| 实用性 | Python字典和元组 | 2024/1/8 20:16 | 文章内容充实,对实际项目使用有很好的帮助 |
| 易学性 | 一篇文章看懂Python从0到放弃 | 2024/1/9 8:13 | 内容通俗易懂,可以快速入门Python的学习 |
| 完整性 | Python画图 | 2024/2/3 12:20 | 内容过于简单,不太完整,有点缺少重要内容,建议补充 |
| 实用性 | 我的Python学习成长记 | 2023/11/12 23:12 | 大佬这篇博文对我很有启发,感谢分享 |
| 易学性 | Python画图 | 2023/11/13 20:12 | 内容不太能理解,没学会,哈哈 |
| 完整性 | 一篇文章看懂Python从0到放弃 | 2023/12/30 20:15 | 内容很多,也很全,学习了 |
| 易学性 | 我的Python学习成长记 | 2023/12/20 21:15 | 可能我基础薄弱,感觉看不懂啊 |
| 易学性 | 如何在职场中呼风唤雨? | 2023/12/19 13:13 | 标题党,一看就是水文 |
| 完整性 | 如何在职场中呼风唤雨? | 2023/12/21 15:15 | 内容过于浮夸,不够完整,建议从实际中多讲讲 |
| 实用性 | 一篇文章看懂Python从0到放弃 | 2023/12/17 18:18 | 比较比较实用,学习了 |
| 完整性 | 我的Python学习成长记 | 2023/12/24 5:37 | 内容充实完整,值得推荐给小伙伴 |
| 实用性 | Python画图 | 2023/12/11 3:16 | 实用性还不错 |
| 易学性 | Python+selenium如何实现自动化测试? | 2023/12/9 16:48 | 内容不错,容易上手,感谢分享 |
| 完整性 | Python+selenium如何实现自动化测试? | 2023/12/8 11:33 | 内我很全啊,支持大佬 |
数据获取
- 有两种方式,第一种是把以上数据存入data.xls文件中,然后使用pandas读取即可,比如:
data = ‘data.xls’
df = pd.read_excel(data ) # 读取文本数据
df1=df.iloc[:,3] # 提取所有数据
print(type(df1))
values=[SnowNLP(i).sentiments for i in df1] # 遍历每条评论进行预测
- 第二种方式是,我们直接把需要的数据放入变量,便于后续直接运行代码,如下:
data = ["文章内容充实,对实际项目使用有很好的帮助",
"内容通俗易懂,可以快速入门Python的学习",
"内容过于简单,不太完整,有点缺少重要内容,建议补充",
"大佬这篇博文对我很有启发,感谢分享",
"内容不太能理解,没学会,哈哈",
"内容很多,也很全,学习了",
"可能我基础薄弱,感觉看不懂啊",
"标题党,一看就是水文",
"内容过于浮夸,不够完整,建议从实际中多讲讲",
"比较比较实用,学习了",
"内容充实完整,值得推荐给小伙伴",
"实用性还不错",
"内容不错,容易上手,感谢分享",
"内我很全啊,支持大佬",
]
print(data)
数据分析
大致过程分如下几个步骤:
- 导入需要的模块或者库;
- 将需要的数据存入列表;
- 循环遍历所有数据;
- 输出积极和消极情绪的概率;
- 计算概率并根据结果生成图标的横纵坐标;
- 结果显示。
# -*- coding:utf-8 -*-
# 作者:虫无涯
# 日期:2024/3/12
# 文件名称:test_snlp.py
# 作用:Python实现博客评论数据的情感分析
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "snownlp"])
subprocess.check_call([sys.executable, "-m", "pip", "install", "matplotlib"])
from snownlp import SnowNLP
import matplotlib.pyplot as plt
data = ["文章内容充实,对实际项目使用有很好的帮助",
"内容通俗易懂,可以快速入门Python的学习",
"内容过于简单,不太完整,有点缺少重要内容,建议补充",
"大佬这篇博文对我很有启发,感谢分享",
"内容不太能理解,没学会,哈哈",
"内容很多,也很全,学习了",
"可能我基础薄弱,感觉看不懂啊",
"标题党,一看就是水文",
"内容过于浮夸,不够完整,建议从实际中多讲讲",
"比较比较实用,学习了",
"内容充实完整,值得推荐给小伙伴",
"实用性还不错",
"内容不错,容易上手,感谢分享",
"内我很全啊,支持大佬",
]
# 遍历数据并进行预测
values = [SnowNLP(i).sentiments for i in data]
print(values)
# 输出积极的概率,大于0.5积极的,小于0.5消极的
# 保存预测值
text = []
positive = 0
negative = 0
for i in values:
if(i>=0.5):
text.append("正面")
positive = positive + 1
else:
text.append("负面")
negative = negative + 1
# 计算好评率
rate = positive / (positive + negative)
print('好评率为:','%.f%%' % (rate * 100)) # 格式化为百分比
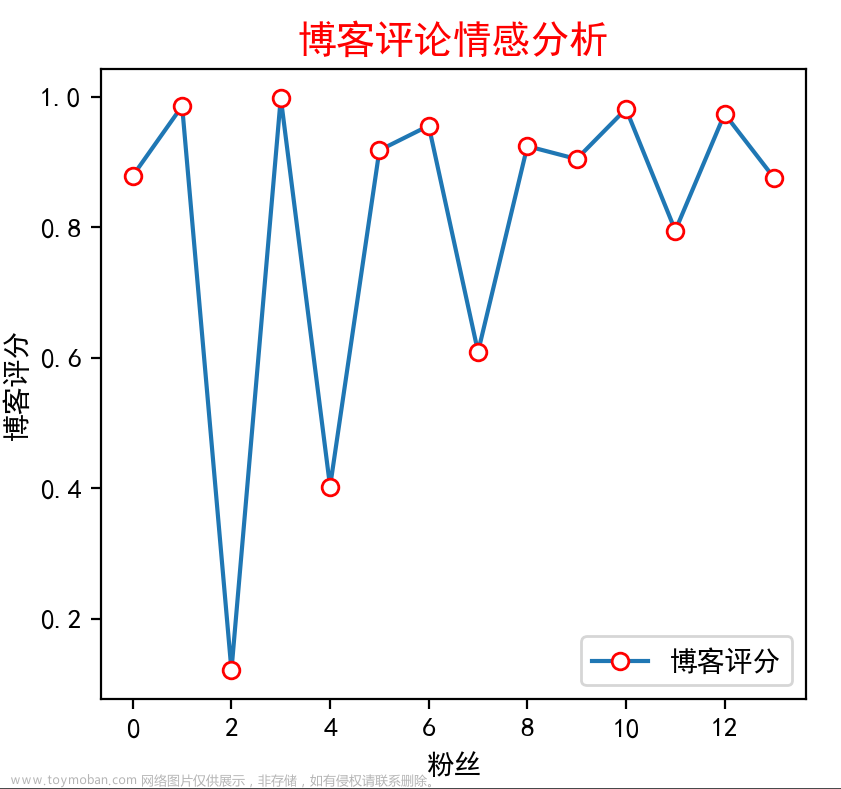
# 图例的横纵坐标
y = values
plt.rc('font', family='SimHei', size=10)
plt.plot(y, marker='o', mec='r', mfc='w', label=u'博客评分')
plt.xlabel('粉丝')
plt.ylabel('博客评分')
# 结果显示
plt.legend() # 让图例生效
plt.title('博客评论情感分析', family='SimHei', size=14, color='red')
plt.savefig('plot.jpg')
- 显示效果如下:
文章来源地址https://www.toymoban.com/news/detail-839202.html
总结
Python实现博客评论数据的情感分析实际是使用了SnowNLP库的功能,SnowNLP不仅可以对评论数据进行情感分析,还能进行文本分类、中文分词、词性标注、提取关键词、文本相似度计算等操作。这样做数据分析其实为了帮助我们更好的了解我们的目标客户对于产品的使用反馈,可以很好帮助我们进一步提升产品质量。文章来源:https://www.toymoban.com/news/detail-839202.html
到了这里,关于数据分析实战-Python实现博客评论数据的情感分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!