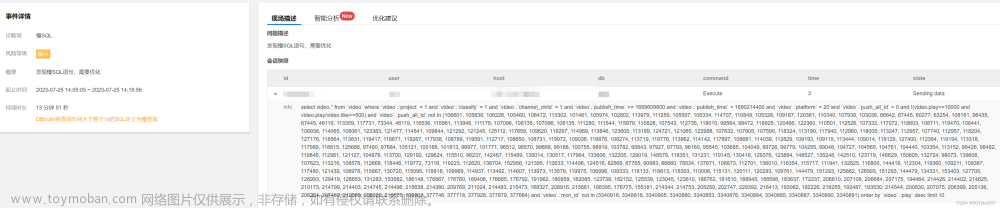
慢查询判定
1.开启慢查询日志记录执行时间超过long_query_time 秒的sql语句
2.通过show processlist命令查看线程执行状态
3.通过explain解析sql了解执行状态
慢查询优化
是否向服务器请求列不必要的数据
查询不需要的记录(limit),多表关联返回全部列,总是取出全部列和重复io等
是否走索引
建立索引的原则:
- 最左前缀匹配原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整
- 等值查询(=和in)可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql查询优化器会优化成索引为可识别的形式
- 模糊匹配like,“%”不能在第一个位置
- 选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大扫描的记录数越少,唯一键的区分度是1
- 索引列不能是表达式的一部分或者是函数的参数
- 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
- 避免在where子句中对字段进行NULL值判断,否则将导致引擎放弃使用索引而进行全表扫描
- or改写成in:or的效率是n级别,in的效率是log(n)级别,in的个数建议控制在200以内
- 尽量避免在where子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描
- 对于连续数值,使用between不用in
查询sql是否合理
切分查询
分解关联查询
将一个大的查询分解为多个小查询是很有必要的。很多高性能的应用都会对关联查询进行分解,就是可以对每一个表进行一次单表查询,然后将查询结果在应用程序中进行关联,很多场景下这样会更高效
表结构优化
- 对于需要经常联合查询的表,可以建立中间表以提高查询效率
-
水平拆分
- 分区表
- 分库分表
- 垂直拆分,将单个表字段分解为多个表字段(根据模块的耦合度,拆分为分布式系统)
查询执行路径
客户端/服务器通信
半双工模式—- 任意时刻数据只能单向传输
查询优化器
mysql查询优化器会通过某种策略自动生成最优的执行计划
重新定义关联表的顺序
数据表的关联顺序并不总是按照在查询中指定的顺序执行
将外连接转化为内连接
并不是所有的OUTER JOIN操作都必须以外连接的方式执行
使用等价变换规则
mysql会使用一些等价变换规则来优化表达式
优化COUNT()
MyISAM维护一个变量存放表的行数, MIN() -- 查询列对应B+树索引最左端记录 ,MAX() -- 查询列对应B+树索引最右端记录
预估并转化为常数表达式
覆盖索引扫描
当索引中的列包含列所有查询需要返回的列时,mysql会自动使用覆盖索引扫描而无需查询对应的数据行
子查询优化
提前终止查询,如Limit
等值传播
列表IN()的比较
在很多数据库系统中,IN()完全等同于多个OR条件的子句,但是mysql会先将IN()列表中的数据进行排序,然后通过二分查找来确定列表中的值是否满足条件,O(log(n))复杂度操作,而如果转换为OR则复杂度为O(n)
SQL执行顺序
FROM—>ON—>JOIN—>WHERE—>GROUP BY—>SUM(聚合函数)—>HAVING—>SELECT—>DISTINCT—>UNION—>ORDER BY—>LIMIT
优化特定类型查询
优化子查询
MySql的子查询实现非常糟糕,特别是where条件中包含IN()的子查询性能通常会比较差,如
select * from film where film_id in (
select film_id from film_actor where film.film_id = 1
);
- MySql查询优化器会将上面的查询通过Exists改写
select * from film where exists(
select * from film_actor where film.film_id = 1
and film.film_id = film_actor.film_id);
IN比较通过在内存中遍历,而exists走数据库索引,所以当子查询中表的数据量比较大时exists效率优于in
- 优化子查询最常见的建议就是尽可能使用关联查询代替
select film.* from film inner join film_actor using (film_id) where actor_id = 1;
优化COUNT()
COUNT函数用于统计某个列值的数量或者行数,统计列值时要求列值非空(不统计NULL)
优化关联查询
- 确保ON或者USING子句的列上有索引。只需在关联顺序的第二个表上建立索引即可,如当表A和表B用列c关联的时候,如果优化器的优化顺序为B,A,那么就不需要在表B上建立索引
- 确保任何的GROUP BY或者ORDER BY中的表达式只涉及到一个表中的列,这样mysql才有可能使用索引来优化这个过程
优化GROUP BY和DISTINCT
当无法使用索引时,GROUP BY会通过临时表或者文件排序做排序
优化limit分页
limit操作在偏移量非常大的情况,mysql会扫描大量不需要的行然后抛弃掉导致效率降低
1.延迟关联:在关联查询中使用覆盖索引扫描,获取关联字段后再根据关联列回表查询需要的所有列
SELECT film_id, description FROM film
INNER JOIN (
SELECT film_id
FROM film ORDER BY title LIMIT 10000, 10
) AS tmp USING (film_id);
2.取上次分页查询操作返回的主键ID作为下一次分页查询起始位置
SELECT film_id, description FROM film WHERE film_id > 10000 ORDER BY title LIMIT 10;
NULL值
空值是不占空间的,NULL是占空间的
聚合函数,如COUNT(),MIN(),SUM()在进行查询时会忽略掉null值
查询列不为NULL应使用IS NOT NULL进行查询
条件查询<>会过滤掉NULL值和空值
Explain
id:执行编号,标识select所属的行。如果在语句中没子查询或关联查询,只有唯一的select,每行都将显示1。否则,内层的select语句一般会顺序编号,对应于其在原始语句中的位置
select_type: 显示本行是简单或复杂select。如果查询有任何复杂的子查询,则最外层标记为PRIMARY(DERIVED、UNION、UNION RESUlT)
table: 访问引用哪个表(引用某个查询,如“derived3”)
type: 数据访问读取操作类型(ALL、index、range、ref、eq_ref、const/system、NULL)
possible_keys: 揭示哪一些索引可能有利于高效的查找
key: 显示mysql决定采用哪个索引来优化查询
key_len: 显示mysql在索引里使用的字节数
ref: 显示了之前的表在key列记录的索引中查找值所用的列或常量
rows: 为了找到所需的行而需要读取的行数,估算值,不精确。通过把所有rows列值相乘,可粗略估算整个查询会检查的行数
Extra: 额外信息,如using index、filesort等
select_type(查询类型)
simple:简单查询,不包含子查询和union
primary:查询包含子查询和union,最外层部分标记为primary
derived:派生表,该临时表是从子查询中派生出来,位于from中的子查询
union:union中第二个及以后的select,第一个union标记为primary
union result:从匿名临时表中检索结果的select操作
dependent union:union中第二个或后面的select语句,取决于外层查询
subquery:子查询中第一个select
dependent subquery:子查询中的第一个select,取决于外层查询
type(访问类型)
all:全表扫描
index:和全表扫描一样,只是扫描表的顺序是按照索引的顺序,优点是避免排序,但是开销仍然非常大
range:范围扫描,key列显示使用哪个索引。当使用如=,<>,>,>=,<,<=,is null,between,in操作符且用常量比较关键字列时,type类型为range
ref:索引访问,返回所有匹配的记录,当使用非唯一索引或者唯一索引非唯一前缀
eq_ref:最多只返回1条符合条件的记录,使用唯一索引或者主键索引时
const/system:mysql能对查询的某部分进行优化并将其转化为一个常量
null:mysql能在优化阶段分解查询语句,在执行时不需访问表或者索引
Extra
Using filesort: mysql会对结果使用外部索引排序,而不是按索引次序从表读取行
Using temporary: mysql在对查询结果排序时使用临时表,常见于排序和分组查询
Using index: 使用覆盖索引扫描,直接从索引中过滤不需要的记录并返回命中结果。这是在mysql服务器层完成的,但无需再回表查询记录
Using index condition:
Using where: mysql服务器将在存储引擎检索行后再进行过滤
distinct: 优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作
复制
主从复制
1.在主库把数据更改记录到二进制文件中(Binary Log)
2.从库将主库上的日志复制到自己的中继日志(Relay Log)上
3.从库读取中继日志的事件,将其重放到从库数据中
作者:Kevin文章来源:https://www.toymoban.com/news/detail-839375.html
原文地址:https://segmentfault.com/a/1190000021289181文章来源地址https://www.toymoban.com/news/detail-839375.html
喜欢 0
到了这里,关于MySql查询性能优化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!