1.项目课程和技术课程的区别
项目课程:实现特殊的项目功能。
技术深度不够。
技术广度可以。
技术课程:trim()不会去掉全角空格。
技术深度够。
技术广度不够。
2.采集项目和数仓项目关系
采集项目和数仓项目就是企业中数据管理两个功能模块。
采集项目:采集和传输数据(用户行为数据,业务数据)。
技术清单:Flume+Maxwell+DataX + Kafka + HDFS。
数据 =>binlog顺序写 => 内存 => file
数仓项目:。对数据进行加工处理(统计分析) 数据,可以临时存储数据。
HDFS + Hive(MR)+ Spark +Flink
数仓分为:离线数仓(Spark) + 实时数仓(Flink)
离线数仓计算延迟以天为单位。
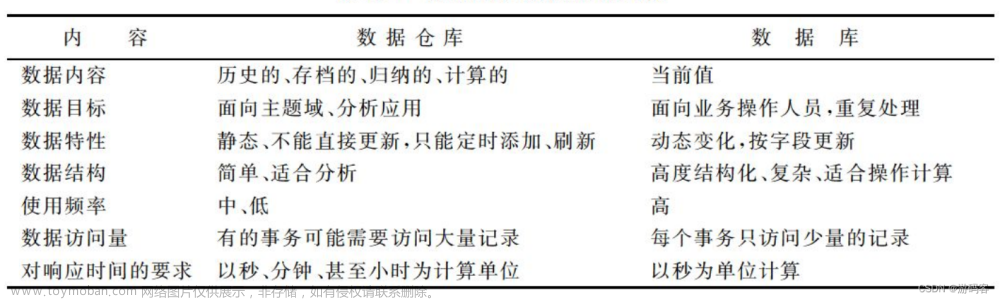
3.数据库和数据仓库的区别
3.1 从名字(英文)上进行区分
数据库:database (完整单词)=> data + base
存储的数据应该为基础核心的业务数据。
数据仓库:data warehose (不是完整的单词)
Warehose:货栈(大商店,小卖部)。
3.2 从数据源的角度
数据库:全企业的所有业务数据。
数据仓库:数据库的数据。
3.3 从数据存储的角度
数据库:主要用于数据的查询处理。
索引提高效率。
不能存储海量数据。
行式存储。
数据仓库:主要用于数据的统计分析
没索引。
可以存储海量数据。
列式存储,有利于压缩。
3.4 从数据价值的角度
数据库:支撑企业中业务系统的执行。
数据仓库:统计结果可以为企业经营决策提供数据依据。
数据仓库并不是数据流转的终点。
数据流转的终点应该是数据可视化平台。
4.数据仓库
数据仓库的核心功能是对数据进行统计分析(Hive on Spark)
Spark的核心功能是对数据进行计算(Spak on Hive : SparkSQL)
二者计算的基本步骤:
数据源 =》 加工数据 =》 统计数据 =》分析数据(排序,取前多少条)
4.1 数据仓库是否可以将业务数据库直接作为数据源使用?
1.业务数据库是为了数据仓库服务的吗?
不是,业务数据库不是为了数据仓库服务,所以数据仓库直接访问数据库
同时会影响业务系统。
栈溢出 :死递归,压栈,小格子不够。Stack
栈内存溢出 :多线程,没有足够的内存空间去开辟栈内存空间,用户太多。
2.数据库能存海量数据?
数据库不能存海量数据,查询效率会慢,不能直接作为数据统计分析的数据源,数据太少。
3.数据库采用行式存储,不利于统计分析。
数据仓库应该采用列式存储,方便统计分析。
4.数据仓库应该有自己的数据源。
数据仓库自己的数据源来自业务数据库的数据,不断汇总业务数据库的数据,
需要周期性将业务数据库的数据同步到数据仓库的数据源中,这个同步的过程叫采集。
4.5 数据仓库和Spark的计算非常类似的
Spark中存在shuffle操作的,所谓的shuffle其实就是将数据落盘,
前一段的任务如果不执行完,那么下阶段的任务无法进行。
数据仓库数据流转过程也存在同样的处理方式
数据仓库计算步骤不称之为阶段(Stage),称之为层。
文章来源地址https://www.toymoban.com/news/detail-839394.html
5.数据仓库建层
5.1 数据源:不断汇总业务数据库的数据以及日志数据。
同步数据效率:尽可能保证数据不变
1)数据格式 (压缩格式,文件格式同一)
2)数据量 (数据量不能减少)
一般这层称之为 Operate Data Store(ODS)(需要操作的数据)
全量数据一般用于分析数据结果。
增量数据一般用于统计数据。
一张表可能是全量和增量。
5.2 加工数据
对数据源中的数据进行加工处理,为了后面的数据统计分析做准备。
加工数据S
数据的有效性,数据的非空校验,敏感数据。
一般这层称之为 Data Warehouse Detail ,简称为DWD。
5.3统计数据
对加工后的数据做统计。
一般这层称之为 Data Warehouse Summary ,简称为DWS。
5.4分析数据
对统计后的结果做进一步的分析。
一般这层称之为Application Data Service,简称为ADS。
Application Data:应用数据。
数据仓库的统计结果数据。
service:对外提供数据服务。
5.5共通层
DIM(共通维度层):dimension(维度)。
所谓的维度,其实就是分析数据的角度。
性别的角度。文章来源:https://www.toymoban.com/news/detail-839394.html
到了这里,关于数据库和数据仓库的区别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!