1. 结构体类型的声明
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
1.1 结构的声明

注意:
- 成员列表可以是不同类型的变量;
- 成员后一定要有分号;
- 花括号后也有一个分号。
例如描述一个学生:
struct Stu
{
char name[20];//姓名
int age;//年龄
char tele[12];//电话
char sex[3];//性别
};//分号不能丢
注意:上述代码没有创建变量,也没有初始化,只是声明了一个结构体类型,就像int,float一样,只是一种类型。
1.2 结构体变量的创建和初始化
接下来我们可以用结构体类型创建变量
方式1:
声明类型的同时创建,这是全局变量
struct Stu
{
char name[20];//姓名
int age;//年龄
char tele[12];//电话
char sex[3];//性别
}s1,s1;
方式2:
我们也可以在函数内部创建局部变量
# include <stdio.h>
struct Stu
{
char name[20];//姓名
int age;//年龄
char tele[12];//电话
char sex[3];//性别
};
int main()
{
struct Stu s3;//s3是局部变量
return 0;
}
我们再对结构体变量进行初始化:
方式1:直接初始化
struct Point
{
int x;
int y;
}p1 = { 2,3 };
struct Stu
{
char name[20];//姓名
int age;//年龄
}s1 = { "zhangsan",27 };
方式2:也可以再函数内部进行初始化
struct Stu
{
char name[20];//姓名
int age;//年龄
};
int main()
{
struct Stu s1 = { "zhangsan",24 };
return 0;
}
当然,也有结构体的嵌套:
struct score
{
int n;
char ch;
};
struct Stu
{
char name[20];//姓名
int age;//年龄
struct score s;//嵌套一个结构体变量
};
int main()
{
struct Stu s1 = { "zhangsan",24 ,{45,'a'} };
return 0;
}
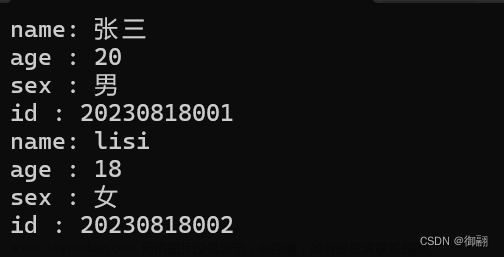
我们也可以将其打印出来:
struct score
{
int n;
char ch;
};
struct Stu
{
char name[20];//姓名
int age;//年龄
struct score s;
};
int main()
{
struct Stu s1 = { "zhangsan",24 ,{45,'a'} };
printf("%s %d %d %c\n", s1.name, s1.age, s1.s.n, s1.s.ch);
return 0;
}
打印结果:
1.3 结构的特殊声明—匿名结构体
在声明结构的时候,可以不完全声明:
struct
{
char name[20];//姓名
int age;//年龄
char tele[12];//电话
char sex[3];//性别
};
上面的结构在声明时省略了结构体标签,我们称为匿名结构体。
注意:匿名结构体只能通过创建全局变量使用一次!!
# include <stdio.h>
struct
{
char name[20];//姓名
int age;//年龄
char tele[12];//电话
char sex[3];//性别
}s1;
int main()
{
return 0;
}
1.4 结构的自引用
在结构体中包含一个类型为该结构体本身的成员是否可以呢?比如,定义一个链表的结点:
struct Node
{
int data;
struct Node next;
};
上述代码正确吗?如果正确,那么sizeof(struct Node)是多少呢?
仔细分析,其实是不行的,因为⼀个结构体中再包含⼀个类型的结构体变量,这样结构体变量的大小就会无穷的大,是不合理的。
正确的自引用方式:
struct Node
{
int data;
struct Node *next;
};
这样我们就把一个结点分成两部分,一部分存放数据,叫数据域,另一部分存放下一个结点的地址,叫指针域。
在结构体自引用使用的过程中,夹杂了 typedef 对匿名结体类型重命名,也容易引入问题,看看下面的代码,可行吗?
typedef struct
{
int data;
Node* next;
}Node;
这种写法语法是不支持的。
因为Node是对前面的匿名结构体类型的重命名产生的,但是在匿名结构体内部提前使用Node类型来创建成员变量,这就产生了"先有鸡还是先有蛋"的问题,这是不行的。
解决方案如下:定义结构体不要使用匿名结构体了。
typedef struct Node
{
int data;
struct Node* next;
}Node;
2.结构体内存对齐(重点!!)
上面我们了解了结构体的基本使用。
接下来我们再讨论一个问题 :计算结构体的大小。
2.1 对齐规则
首先要知道结构体的对齐规则:
第一个成员在结构体变量偏移量为0的地址处。
其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
注意:
(1) 对齐数=编译器默认的对齐数与该成员大小的较小值
(1)VS中默认值为8(注意:其他编译器是没有默认对齐数的,对齐数就是自身大小。)结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐的整数倍处。
结构体的整体大小就是所有最大对齐数的(含嵌套结构体的对齐数)的整数倍。
2.2 例题讲解
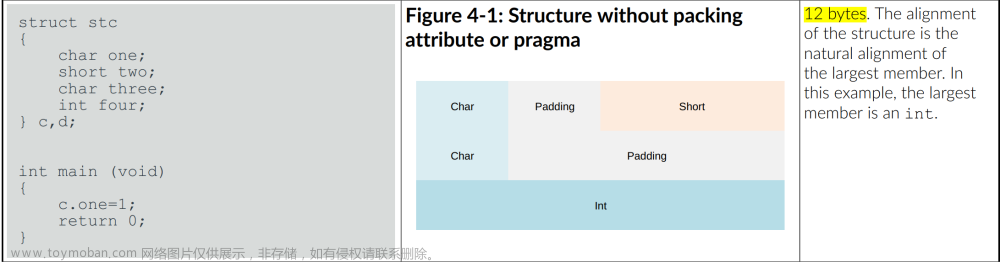
例1:
#include <stdio.h>
struct S1
{
char c1;
int i;
char c2;
};
int main()
{
struct S1 s1;
printf("%d\n", sizeof(struct S1));
return 0;
}
输出结果:
画图解释:
例2:
#include <stdio.h>
struct S2
{
char c1;
char c2;
int i;
};
int main()
{
struct S2 s1;
printf("%d\n", sizeof(struct S2));
return 0;
}
输出结果:
画图解释:
例3:
#include <stdio.h>
struct S3
{
double d;
char c;
int i;
};
int main()
{
struct S3 s3;
printf("%d\n", sizeof(struct S3));
return 0;
}
输出结果:
画图解释:
例4:结构体嵌套问题
#include <stdio.h>
struct S4
{
char c1;
struct S3 s3;
double d;
};
int main()
{
struct S4 s4;
printf("%d\n", sizeof(struct S4));
return 0;
}
输出结果:
画图解释:
2.3 为什么存在内存对齐?
大部分的参考资料都是这样说的:
- 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。 - 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要⼀次访问。假设⼀个处理器总是从内存中取8个字节,则地址必须是8的倍数。如果我们能保证将所有的double类型的数据的地址都对齐成8的倍数,那么就可以用⼀个内存操作来读或者写值了。否则,我们可能需要执行两次内存访问,因为对象可能被分放在两个8字节内存块中。
总体来说:结构体的内存对齐是拿空间来换取时间的做法。
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到:
让占用空间小的成员尽量集中在⼀起。
如例1和例2,s1和s2的成员一模一样,但两者所占空间大小却不同。
2.4 修改默认对齐数
- #pragma : 预处理指令,可以改变编译器的默认对齐数。
- 使用时要引用头文件<stddef.h>
- 注意:一般修改的对齐数都为2的n次方。不会修改为1,3,5……或负数。
例如还是用例1来说明:
#include <stdio.h>
#include <stddef.h>
#pragma pack(1)//设置默认对齐数为1
struct S1
{
char c1;
int i;
char c2;
};
#pragma()//取消设置的对齐数,还原为默认
int main()
{
printf("%d\n", sizeof(struct S1));
}
输出结果:
修改之前大小是12个字节,修改后变成了6字节。
3. 结构体传参
方式1:传值调用。访问结构体时用点(.)操作符。
#include <stdio.h>
struct S
{
int data[1000];
int num;
};
void print1(struct S ss)
{
int i = 0;
for (i = 0; i < 3; i++)
{
printf("%d ", ss.data[i]);
}
printf("%d\n", ss.num);
}
int main()
{
struct S s = { {1,2,3},200 };
print1(s); //传值调用,直接传变量名
return 0;
}
方式2:传址调用。访问结构体时用箭头(->)操作符。
#include <stdio.h>
struct S
{
int data[1000];
int num;
};
void print2(const struct S* ps)
{
int i = 0;
for (i = 0; i < 3; i++)
{
printf("%d ", ps->data[i]);
}
printf("%d\n", ps->num);
}
int main()
{
struct S s = { {1,2,3},200 };
print2(&s); //传址调用,传变量名的地址
return 0;
输出结果都为:
上面的两种方式哪个更好呢?
答案是:传址调用更好。
原因:
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
如果传递⼀个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。文章来源:https://www.toymoban.com/news/detail-839428.html
结论:
结构体传参的时候,要传结构体的地址。文章来源地址https://www.toymoban.com/news/detail-839428.html
到了这里,关于C语言自定义类型:结构体的使用及其内存对齐【超详细建议点赞收藏】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!