作者推荐
视频算法专题
本文涉及知识点
广度优先搜索 图论 并集查找
LeetCod2493. 将节点分成尽可能多的组
给你一个正整数 n ,表示一个 无向 图中的节点数目,节点编号从 1 到 n 。
同时给你一个二维整数数组 edges ,其中 edges[i] = [ai, bi] 表示节点 ai 和 bi 之间有一条 双向 边。注意给定的图可能是不连通的。
请你将图划分为 m 个组(编号从 1 开始),满足以下要求:
图中每个节点都只属于一个组。
图中每条边连接的两个点 [ai, bi] ,如果 ai 属于编号为 x 的组,bi 属于编号为 y 的组,那么 |y - x| = 1 。
请你返回最多可以将节点分为多少个组(也就是最大的 m )。如果没办法在给定条件下分组,请你返回 -1 。
示例 1:
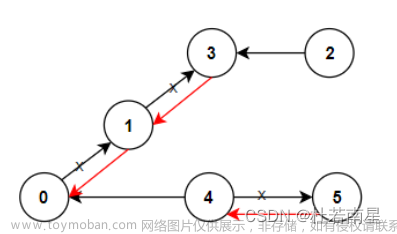
输入:n = 6, edges = [[1,2],[1,4],[1,5],[2,6],[2,3],[4,6]]
输出:4
解释:如上图所示,
- 节点 5 在第一个组。
- 节点 1 在第二个组。
- 节点 2 和节点 4 在第三个组。
- 节点 3 和节点 6 在第四个组。
所有边都满足题目要求。
如果我们创建第五个组,将第三个组或者第四个组中任何一个节点放到第五个组,至少有一条边连接的两个节点所属的组编号不符合题目要求。
示例 2:
输入:n = 3, edges = [[1,2],[2,3],[3,1]]
输出:-1
解释:如果我们将节点 1 放入第一个组,节点 2 放入第二个组,节点 3 放入第三个组,前两条边满足题目要求,但第三条边不满足题目要求。
没有任何符合题目要求的分组方式。
提示:
1 <= n <= 500
1 <= edges.length <= 104
edges[i].length == 2
1 <= ai, bi <= n
ai != bi
两个点之间至多只有一条边。
广度优先搜索
注意:可能有多个连通区域,每个连通区域要分别处理。
如果没有环一定可以分组。如果是偶数环一定可以:{n[0]},{n[1],n[n-1]}…{n[n]}。从任何节点开始都可以访问。如果是奇数环一定不可以,以三个边的环为例: 第一个顶点在x分组,第二顶点和第三个定点在(x-1)或(x+1)。第二个顶点和第三个顶点只能相差0或2,不会相差1。
下面来严格证明:
节点n1在x分组,通过某条长度m1路径,可以到达n2。则n2可以的分组是:s1 = {x+m1,x+m1-2,x+m1-4
⋯
\cdots
⋯ x-m1+2,x-m1}。
同时n1到n2存在长度为m2的路径。则n2可以分组是:s2 = {x+m2,x+m2-2,x+m2-4
⋯
\cdots
⋯ x-m2+2,x-m2}。
性质一
{
无法分组
m
1
,
m
2
奇偶性不同
待证明一
s
1
e
l
s
e
i
f
(
m
1
<
m
2
)
s
2
o
t
h
e
r
\textbf{性质一} \begin{cases} 无法分组 & m1,m2奇偶性不同 & \textbf{待证明一} \\ s1 & else \quad if(m1 < m2) & \\ s2 & other \\ \end{cases}
性质一⎩
⎨
⎧无法分组s1s2m1,m2奇偶性不同elseif(m1<m2)other待证明一
待证明一: 将s1(s2)所有元素减去x后,如果m1(m2)是奇数(偶数),则全部元素都是奇数(偶数)。 如果m1和m2奇偶性不同,两者没有交集。
以任意节点为根,BFS各点是否存在长度奇数和偶数的路径。任意节点同时存在到根节点出度为奇数和偶数的路径则无法分组。淘汰一
如果n1和n2同时存在长度为奇数的路径p1,长度为偶数的路径p2。则任意节点为起点一定存在奇偶路径。
路径一:
r
o
o
t
→
任意路径
n
1
→
p
1
n
2
路径二:
o
o
t
→
任意路径
n
1
→
p
2
n
2
路径一: root^{任意路径}_\rightarrow n1 ^{p1}_\rightarrow n2 路径二:oot^{任意路径}_\rightarrow n1 ^{p2}_\rightarrow n2
路径一:root→任意路径n1→p1n2路径二:oot→任意路径n1→p2n2
根据性质一,根节点编号为1,其它节点cur编号:1 + (cur到根节点最短距离)
最短距离显然是BFS的优势。
按上述分组方法,任意节点n1,n2不会冲突。
令n1 ,n2到 root的距离为m1,m2。则两这个编号为1+m1,1+m2。不失一般性,令m1 > m2。
n1到n2的最短距离m12 >= m1-m2,否则根节点直接通过n2到n1。
n1
→
\rightarrow
→ root
→
\rightarrow
→ n2 是n1到n2的路径,他们的长度是m1+m2,根据淘汰一,它和m12的奇偶性相同。m1+m2和m1-m2的奇偶性相同,故这样分组n1和n2不会矛盾。
BFS
BFS状态:节点 奇数(偶数)长度,每个节点处理2次,但每个节点的边不是O(1),所以时间复杂度是O(m),m是边数。
还要枚举根节点,这样总时间复杂度是:O(nm) 在超时的边缘。
代码
核心代码
class CNeiBo
{
public:
static vector<vector<int>> Two(int n, vector<vector<int>>& edges, bool bDirect, int iBase = 0)
{
vector<vector<int>> vNeiBo(n);
for (const auto& v : edges)
{
vNeiBo[v[0] - iBase].emplace_back(v[1] - iBase);
if (!bDirect)
{
vNeiBo[v[1] - iBase].emplace_back(v[0] - iBase);
}
}
return vNeiBo;
}
};
class CUnionFind
{
public:
CUnionFind(int iSize) :m_vNodeToRegion(iSize)
{
for (int i = 0; i < iSize; i++)
{
m_vNodeToRegion[i] = i;
}
m_iConnetRegionCount = iSize;
}
CUnionFind(vector<vector<int>>& vNeiBo):CUnionFind(vNeiBo.size())
{
for (int i = 0; i < vNeiBo.size(); i++) {
for (const auto& n : vNeiBo[i]) {
Union(i, n);
}
}
}
int GetConnectRegionIndex(int iNode)
{
int& iConnectNO = m_vNodeToRegion[iNode];
if (iNode == iConnectNO)
{
return iNode;
}
return iConnectNO = GetConnectRegionIndex(iConnectNO);
}
void Union(int iNode1, int iNode2)
{
const int iConnectNO1 = GetConnectRegionIndex(iNode1);
const int iConnectNO2 = GetConnectRegionIndex(iNode2);
if (iConnectNO1 == iConnectNO2)
{
return;
}
m_iConnetRegionCount--;
if (iConnectNO1 > iConnectNO2)
{
UnionConnect(iConnectNO1, iConnectNO2);
}
else
{
UnionConnect(iConnectNO2, iConnectNO1);
}
}
bool IsConnect(int iNode1, int iNode2)
{
return GetConnectRegionIndex(iNode1) == GetConnectRegionIndex(iNode2);
}
int GetConnetRegionCount()const
{
return m_iConnetRegionCount;
}
vector<int> GetNodeCountOfRegion()//各联通区域的节点数量
{
const int iNodeSize = m_vNodeToRegion.size();
vector<int> vRet(iNodeSize);
for (int i = 0; i < iNodeSize; i++)
{
vRet[GetConnectRegionIndex(i)]++;
}
return vRet;
}
std::unordered_map<int, vector<int>> GetNodeOfRegion()
{
std::unordered_map<int, vector<int>> ret;
const int iNodeSize = m_vNodeToRegion.size();
for (int i = 0; i < iNodeSize; i++)
{
ret[GetConnectRegionIndex(i)].emplace_back(i);
}
return ret;
}
private:
void UnionConnect(int iFrom, int iTo)
{
m_vNodeToRegion[iFrom] = iTo;
}
vector<int> m_vNodeToRegion;//各点所在联通区域的索引,本联通区域任意一点的索引,为了增加可理解性,用最小索引
int m_iConnetRegionCount;
};
class CBFS
{
public:
CBFS(int iStatuCount, int iInit = -1) :m_iStatuCount(iStatuCount), m_iInit(iInit)
{
m_res.assign(iStatuCount, iInit);
}
bool Peek(int& statu)
{
if (m_que.empty())
{
return false;
}
statu = m_que.front();
m_que.pop_front();
return true;
}
void PushBack(int statu, int value)
{
if (m_iInit != m_res[statu])
{
return;
}
m_res[statu] = value;
m_que.push_back(statu);
}
void PushFront(int statu, int value)
{
if (m_iInit != m_res[statu])
{
return;
}
m_res[statu] = value;
m_que.push_front(statu);
}
int Get(int statu)
{
return m_res[statu];
}
private:
const int m_iStatuCount;
const int m_iInit;
deque<int> m_que;
vector<int> m_res;
};
class CBFS2 : protected CBFS
{
public:
CBFS2(int iStatuCount1, int iStatuCount2, int iInit = -1) :CBFS(iStatuCount1* iStatuCount2, iInit), m_iStatuCount2(iStatuCount2)
{
}
bool Peek(int& statu1, int& statu2)
{
int statu;
if (!CBFS::Peek(statu))
{
return false;
}
statu1 = statu / m_iStatuCount2;
statu2 = statu % m_iStatuCount2;
return true;
}
void PushBack(int statu1, int statu2, int value)
{
CBFS::PushBack(statu1 * m_iStatuCount2 + statu2, value);
}
void PushFront(int statu1, int statu2, int value)
{
CBFS::PushFront(statu1 * m_iStatuCount2 + statu2, value);
}
int Get(int statu1, int statu2)
{
return CBFS::Get(statu1 * m_iStatuCount2 + statu2);
}
private:
const int m_iStatuCount2;
};
class Solution {
public:
int magnificentSets(int n, vector<vector<int>>& edges) {
auto neiBo = CNeiBo::Two(n, edges, false, 1);
CUnionFind uf(neiBo);
auto m = uf.GetNodeOfRegion();
int iRet = 0;
for (const auto& [tmp, v] : m)
{
int iMax = 0;
for(const int& root : v )
{
CBFS2 bfs(n, 2);
bfs.PushBack(root, 0, 1);
int cur, iOne;
while (bfs.Peek(cur, iOne))
{
const int iDis = bfs.Get(cur, iOne);
for (const auto& next : neiBo[cur])
{
bfs.PushBack(next, (iOne + 1) % 2, iDis + 1);
}
}
for (const int& node : v)
{
if ((-1 != bfs.Get(node, 0)) && (-1 != bfs.Get(node, 1)))
{
return -1;
}
iMax = max(iMax, bfs.Get(node, 0));
iMax = max(iMax, bfs.Get(node, 1));
}
};
iRet += iMax;
}
return iRet;
}
};
测试用例
template<class T,class T2>
void Assert(const T& t1, const T2& t2)
{
assert(t1 == t2);
}
template<class T>
void Assert(const vector<T>& v1, const vector<T>& v2)
{
if (v1.size() != v2.size())
{
assert(false);
return;
}
for (int i = 0; i < v1.size(); i++)
{
Assert(v1[i], v2[i]);
}
}
int main()
{
int n;
vector<vector<int>> edges;
{
Solution sln;
n = 6, edges = { {1,2},{1,4},{1,5},{2,6},{2,3},{4,6} };
auto res = sln.magnificentSets(n, edges);
Assert(4, res);
}
{
Solution sln;
n = 3, edges = { {1,2},{2,3},{3,1} };
auto res = sln.magnificentSets(n, edges);
Assert(-1, res);
}
}
2023年4月
//并集查找
class CUnionFind
{
public:
CUnionFind(int iSize)
{
for (int i = 0; i < iSize; i++)
{
m_vTop.emplace_back(i);
}
m_iSize = m_vTop.size();
}
void Add(int iFrom, int iTo)
{
int iRoot1 = GetTop(iFrom);
int iRoot2 = GetTop(iTo);
if (iRoot1 == iRoot2)
{
return;
}
//增强可理解性
if (iRoot1 < iRoot2)
{
std::swap(iRoot1, iRoot2);
std::swap(iFrom, iTo);
}
m_vTop[iRoot1] = iRoot2;
GetTop(iFrom);
m_iSize–;
}
int GetTop(int iNode)
{
if (iNode == m_vTop[iNode])
{
return iNode;
}
return m_vTop[iNode] = GetTop(m_vTop[iNode]);
}
int Size()const
{
return m_iSize;
}
const vector& Top()
{
for (int i = 0; i < m_vTop.size(); i++)
{
GetTop(i);
}
return m_vTop;
}
std::unordered_map<int, vector> TopNums()
{
Top();
std::unordered_map<int, vector> mRet;
for (int i = 0; i < m_vTop.size(); i++)
{
mRet[m_vTop[i]].emplace_back(i);
}
return mRet;
}
private:
vector m_vTop;
int m_iSize;
};
class Solution {
public:
int magnificentSets(int n, vector<vector>& edges) {
m_vNeiB.resize(n);
m_iN = n;
CUnionFind uf(n);
for (const auto& v : edges)
{
m_vNeiB[v[0] - 1].emplace_back(v[1] - 1);
m_vNeiB[v[1] - 1].emplace_back(v[0] - 1);
uf.Add(v[0] - 1, v[1] - 1);
}
auto tmp = uf.TopNums();
int iRet = 0;
for (auto& it : tmp)
{
int iCur = 0;
for (const int iRoot : it.second)
{
iCur = max(iCur, bfs(iRoot));
}
iRet += iCur;
}
if (m_bCycle3)
{
return -1;
}
return iRet;
}
int bfs(int iRoot)
{
vector vDis(m_iN,-1);
queue que;
vDis[iRoot] = 1;
que.emplace(iRoot);
while (que.size())
{
const int iCur = que.front();
que.pop();
for (const auto& next : m_vNeiB[iCur])
{
if (-1 != vDis[next])
{
if (( vDis[next] >= 2 ) && (vDis[next] == vDis[iCur]))
{
m_bCycle3 = true;
}
continue;
}
vDis[next] = vDis[iCur] + 1;
que.emplace(next);
}
}
return *std::max_element(vDis.begin(), vDis.end());
}
vector<vector> m_vNeiB;
int m_iN;
bool m_bCycle3 = false;//环的节点为奇数无法完成
};
2023年8月
class Solution {
public:
int magnificentSets(int n, vector<vector>& edges) {
m_iN = n;
CNeiBo2 neiBo2(n, edges, false,1);
vector vRootToMaxLeve(n);
for (int i = 0; i < n; i++)
{
vRootToMaxLeve[i] = bfs(i, neiBo2.m_vNeiB);
}
CUnionFind uf(n);
for (const auto& v : edges)
{
uf.Union(v[0] - 1, v[1] - 1);
}
vector vRegionToMaxLeve(n);
for (int i = 0; i < n; i++)
{
const int iRegion = uf.GetConnectRegionIndex(i);
vRegionToMaxLeve[iRegion] = max(vRegionToMaxLeve[iRegion], vRootToMaxLeve[i]);
}
for (int i = 0; i < n; i++)
{
const int iRegion = uf.GetConnectRegionIndex(i);
if (0 == vRegionToMaxLeve[iRegion])
{
return -1;
}
}
return std::accumulate(vRegionToMaxLeve.begin(), vRegionToMaxLeve.end(),0);
}
int bfs(int root, const vector<vector<int>>& neiBo)
{
vector<int> m_vLeve(m_iN,-1);
std::queue<int> que;
que.emplace(root);
m_vLeve[root] = 1;
while (que.size())
{
const auto cur = que.front();
que.pop();
const int curLeve = m_vLeve[cur];
for (const auto& next : neiBo[cur])
{
if (-1 == m_vLeve[next])
{
m_vLeve[next] = curLeve + 1;
que.emplace(next);
}
else
{
if ((curLeve - 1 != m_vLeve[next]) && (curLeve + 1 != m_vLeve[next]))
{
return -1;
}
}
}
}
return *std::max_element(m_vLeve.begin(),m_vLeve.end());
}
int m_iN;
};
2023年9月版
class Solution {
public:
int magnificentSets(int n, vector<vector>& edges) {
CNeiBo2 neiBo(n, edges, false, 1);
CUnionFind uf(n);
for (const auto& v : edges)
{
uf.Union(v[0] - 1, v[1] - 1);
}
auto m = uf.GetNodeOfRegion();
m_vLeve.assign(n, m_iNotMay);
int iRet = 0;
for (const auto& it : m)
{
const int iRegionLeve = Do(it.second, neiBo);
if (iRegionLeve < 0 )
{
return -1;
}
iRet += iRegionLeve;
}
return iRet;
}
int Do(const vector& vNodeOfARegion, const CNeiBo2& neiBo)
{
int iRet = -1;
for (const auto& node : vNodeOfARegion)
{
for (const auto& node1 : vNodeOfARegion)
{
m_vLeve[node1] = m_iNotMay;
}
iRet = max(iRet,bfs(node, neiBo));
}
return iRet;
}
int bfs(int root,const CNeiBo2& neiBo)
{
m_vLeve[root] = 1;
std::queue que;
que.emplace(root);
int iMax = 0;
while (que.size())
{
const auto cur = que.front();
que.pop();
const int leve = m_vLeve[cur] + 1;
iMax = max(iMax, m_vLeve[cur]);
for (const auto next : neiBo.m_vNeiB[cur])
{
if (m_iNotMay == m_vLeve[next])
{
m_vLeve[next] = leve;
que.emplace(next);
}
else if ((leve - 2 != m_vLeve[next]) && (leve != m_vLeve[next]))
{
return -1;
}
}
}
return iMax;
}
vector m_vLeve;
const int m_iNotMay = 1000 * 1000;
};

扩展阅读
视频课程
有效学习:明确的目标 及时的反馈 拉伸区(难度合适),可以先学简单的课程,请移步CSDN学院,听白银讲师(也就是鄙人)的讲解。
https://edu.csdn.net/course/detail/38771
如何你想快速形成战斗了,为老板分忧,请学习C#入职培训、C++入职培训等课程
https://edu.csdn.net/lecturer/6176
相关下载
想高屋建瓴的学习算法,请下载《喜缺全书算法册》doc版
https://download.csdn.net/download/he_zhidan/88348653
| 我想对大家说的话 |
|---|
| 闻缺陷则喜是一个美好的愿望,早发现问题,早修改问题,给老板节约钱。 |
| 子墨子言之:事无终始,无务多业。也就是我们常说的专业的人做专业的事。 |
| 如果程序是一条龙,那算法就是他的是睛 |
测试环境
操作系统:win7 开发环境: VS2019 C++17
或者 操作系统:win10 开发环境: VS2022 C++17
如无特殊说明,本算法用**C++**实现。文章来源:https://www.toymoban.com/news/detail-839654.html
 文章来源地址https://www.toymoban.com/news/detail-839654.html
文章来源地址https://www.toymoban.com/news/detail-839654.html
到了这里,关于【广度优先搜索】【图论】【并集查找】2493. 将节点分成尽可能多的组的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!