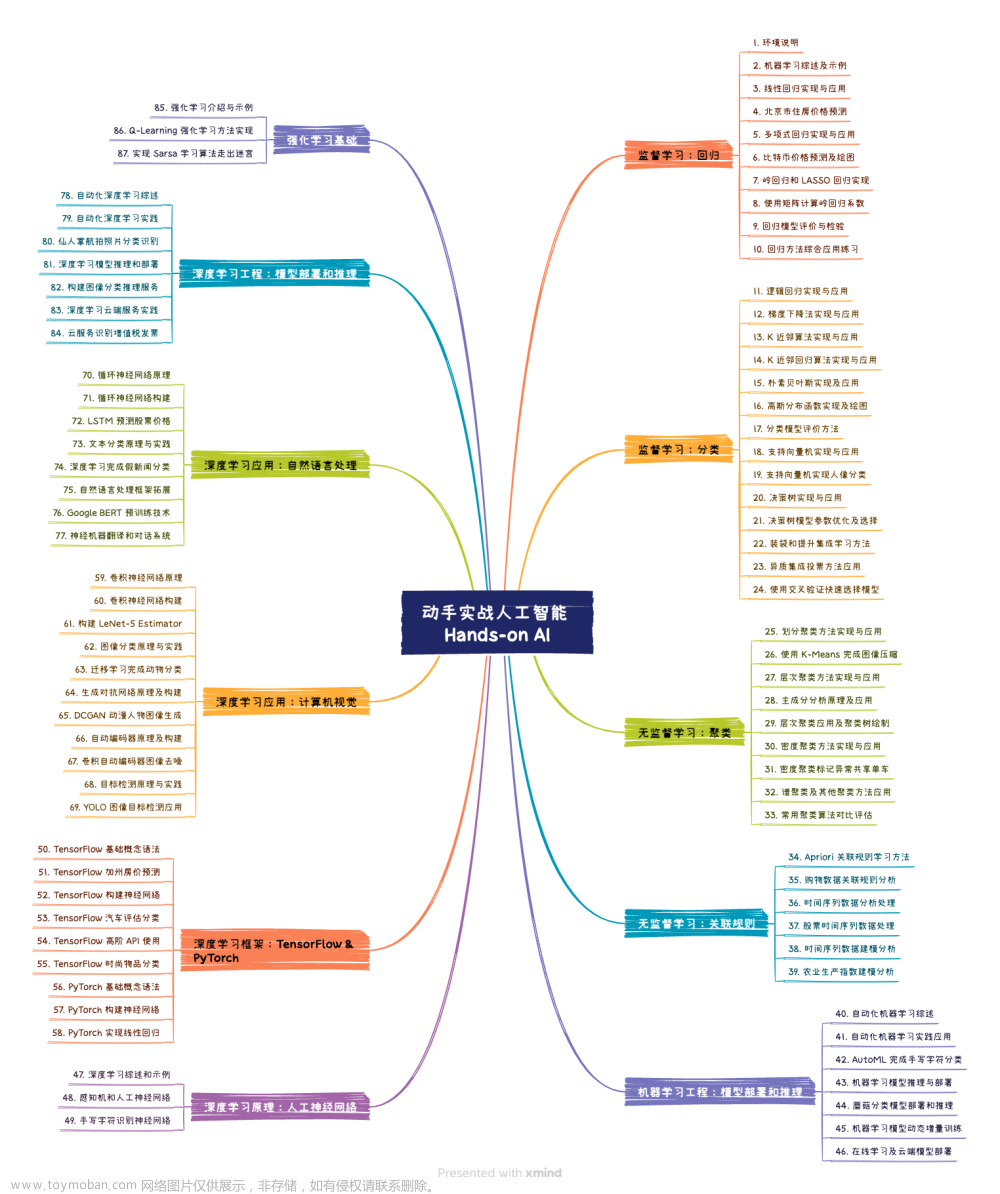
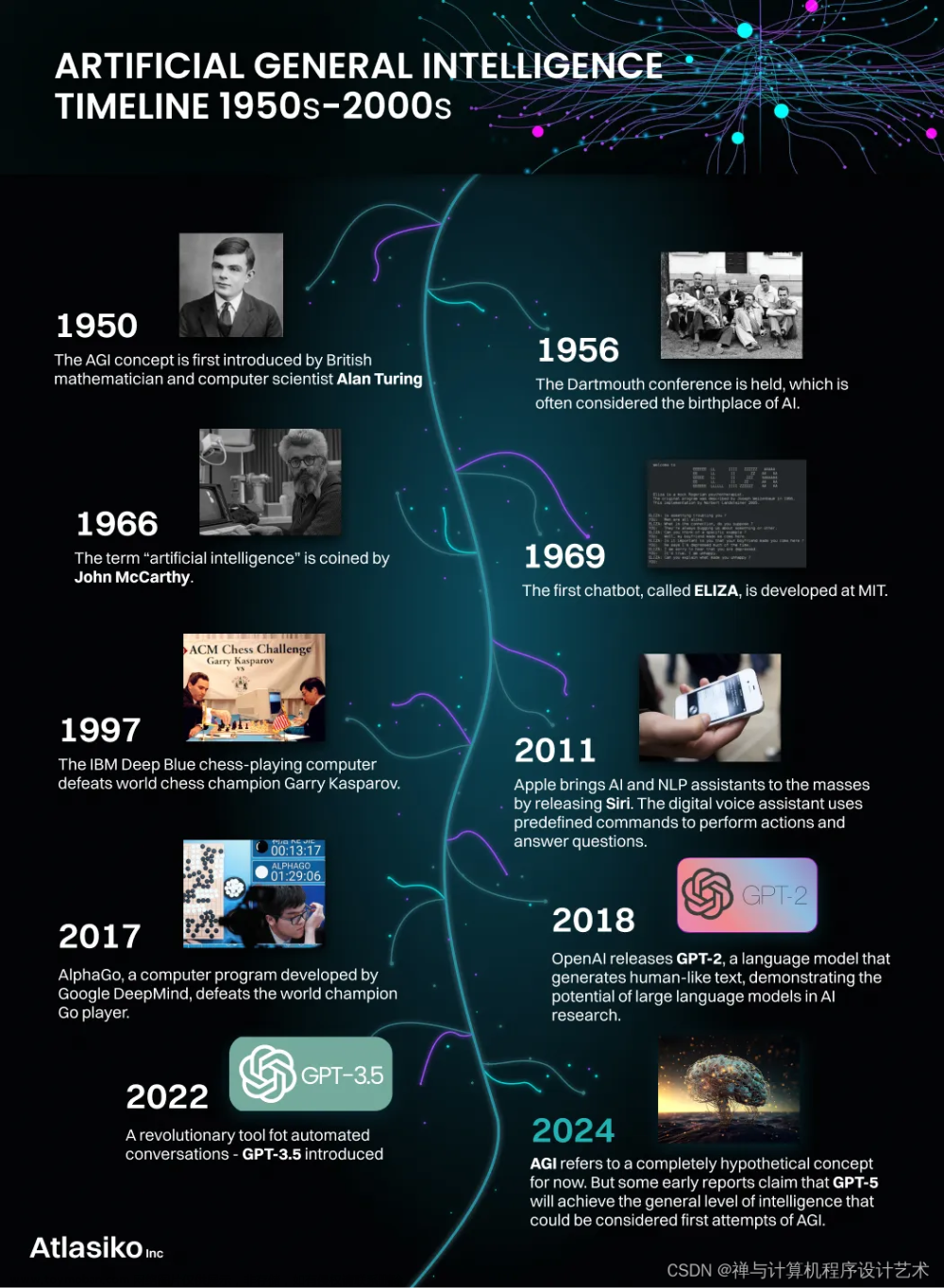
摘要
检索增强生成(RAG)系统通过结合传统的语言模型生成能力和结构化数据检索,为复杂的问题提供精确的答案。本文深入探讨了RAG系统中检索技术的工作原理、实现方式以及面临的挑战,并对未来的发展方向提出了展望。
随着大型预训练语言模型(LLMs)如GPT-3和BERT的出现,自然语言处理(NLP)领域取得了显著进展。然而,这些模型在处理知识密集型任务时仍存在局限性,特别是在需要最新或特定领域知识的情况下。RAG系统通过引入检索机制,增强了模型的知识库,使其能够生成更准确、更丰富的回答。
RAG系统的核心:检索技术
RAG系统的核心在于其检索技术,该技术使模型能够在生成回答之前,从一个大型的、结构化的外部知识库中检索相关信息。这一过程通常包括以下步骤:
1. 索引构建
首先,知识库中的文档被转换成向量形式,这一步骤称为索引构建。文档的向量化通常通过嵌入模型完成,如BERT或GPT,这些模型能够捕捉文本的语义信息。
2. 查询理解
用户的问题或查询首先被转换成一个查询向量。这一步骤通常使用与索引构建相同的嵌入模型来完成,确保查询向量与文档向量在同一向量空间中。
3. 相似度评分
查询向量与索引中的文档向量进行比较,以计算相似度得分。这一步骤通常使用余弦相似度或其他相似度度量方法。
4. 文档检索
根据相似度得分,系统检索出最相关的文档。这些文档将作为生成阶段的上下文信息,辅助模型生成回答。
RAG系统中的检索技术挑战
尽管RAG系统在提高生成文本质量方面取得了成功,但在检索技术方面仍面临一些挑战:
1. 检索质量
检索到的文档质量直接影响生成文本的准确性。如何提高检索结果的相关性和准确性是一个重要问题。
2. 检索效率
随着知识库规模的增长,如何提高检索效率,减少检索时间,成为一个挑战。
3. 上下文整合
如何有效地将检索到的信息整合到生成模型中,以生成连贯且信息丰富的文本,是另一个挑战。
4. 多模态检索
在处理包含图像、音频等非文本数据的任务时,如何实现有效的多模态检索,是RAG系统需要解决的问题。
未来发展方向
未来的RAG系统可能会在以下几个方向进行发展:
1. 高效检索算法
开发更高效的检索算法,如基于图的检索或使用近似最近邻(ANN)搜索,以提高检索速度和准确性。
2. 深度语义理解
利用深度学习技术提高查询和文档的语义理解能力,以实现更精准的检索。
3. 个性化检索
根据用户的历史行为和偏好,实现个性化的检索和生成,提供更符合用户需求的内容。
4. 跨领域知识融合
研究如何将不同领域的知识有效地融合到RAG系统中,以提高模型的泛化能力和适应性。文章来源:https://www.toymoban.com/news/detail-839717.html
总结
RAG系统通过结合检索技术和生成模型,为解决知识密集型任务提供了新的可能性。尽管存在挑战,但随着技术的进步,RAG系统有望在未来的NLP领域发挥更大的作用。文章来源地址https://www.toymoban.com/news/detail-839717.html
到了这里,关于大型语言模型RAG(检索增强生成):检索技术的应用与挑战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!