有一个开源的、商业上可用的机器学习工具包,叫做scikit-learn。这个工具包包含了你将在本课程中使用的许多算法的实现。
实验一
目标
在本实验中,你将:利用scikit-learn实现使用梯度下降的线性回归
工具
您将使用scikit-learn中的函数以及matplotlib和NumPy。
import numpy as np
np.set_printoptions(precision=2)
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.preprocessing import StandardScaler
from lab_utils_multi import load_house_data
import matplotlib.pyplot as plt
dlblue = '#0096ff'; dlorange = '#FF9300'; dldarkred='#C00000'; dlmagenta='#FF40FF'; dlpurple='#7030A0';
plt.style.use('./deeplearning.mplstyle')
np.set_printoptions(precision=2) 的作用是告诉 NumPy 在打印数组时只保留浮点数的两位小数。
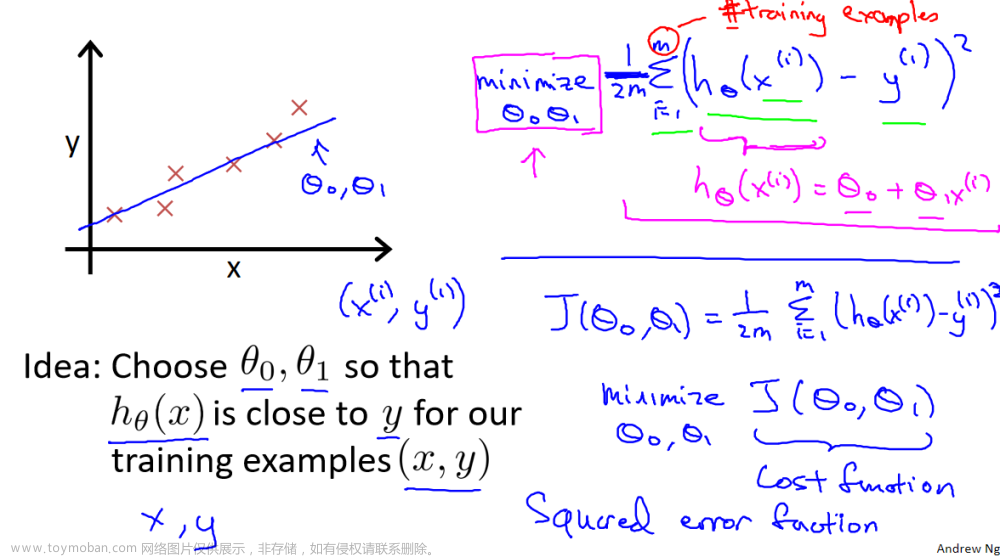
梯度下降
Scikit-learn有一个梯度下降回归模型sklearn.linear_model.SGDRegressor。与之前的梯度下降实现一样,该模型在规范化输入时表现最好。sklearn预处理。StandardScaler将执行z-score归一化在以前的实验室。这里它被称为“标准分数”。
加载数据集
X_train, y_train = load_house_data()
X_features = ['size(sqft)','bedrooms','floors','age']
缩放/规范化训练数据
scaler = StandardScaler()
X_norm = scaler.fit_transform(X_train)
print(f"Peak to Peak range by column in Raw X:{np.ptp(X_train,axis=0)}")
print(f"Peak to Peak range by column in Normalized X:{np.ptp(X_norm,axis=0)}")

创建并拟合回归模型
sgdr = SGDRegressor(max_iter=1000)
sgdr.fit(X_norm, y_train)
print(sgdr)
print(f"number of iterations completed: {sgdr.n_iter_}, number of weight updates: {sgdr.t_}")
这段代码使用了 SGDRegressor 类来进行线性回归模型的训练和预测。
首先,通过SGDRegressor(max_iter=1000)创建了一个随机梯度下降(SGD)回归器对象sgdr,并设置最大迭代次数为 1000。
然后,使用sgdr.fit(X_norm, y_train)对模型进行拟合,其中X_norm是经过标准化处理后的特征数据,y_train是对应的目标变量。
接着,通过print(sgdr)打印出sgdr对象的相关信息,包括模型参数和超参数等。
最后,使用 f-string 格式化字符串,打印出训练完成的迭代次数sgdr.n_iter_和权重更新次数sgdr.t_。
查看参数
注意,参数与规范化的输入数据相关联。拟合参数与之前使用该数据的实验室中发现的非常接近。
b_norm = sgdr.intercept_
w_norm = sgdr.coef_
print(f"model parameters: w: {w_norm}, b:{b_norm}")
print(f"model parameters from previous lab: w: [110.56 -21.27 -32.71 -37.97], b: 363.16")

作出预测
预测训练数据的目标。同时使用预测例程并使用w和b进行计算。
# make a prediction using sgdr.predict()
y_pred_sgd = sgdr.predict(X_norm)
# make a prediction using w,b.
y_pred = np.dot(X_norm, w_norm) + b_norm
print(f"prediction using np.dot() and sgdr.predict match: {(y_pred == y_pred_sgd).all()}")
print(f"Prediction on training set:\n{y_pred[:4]}" )
print(f"Target values \n{y_train[:4]}")

绘制结果
让我们绘制预测值与目标值的对比图。
# plot predictions and targets vs original features
fig,ax=plt.subplots(1,4,figsize=(12,3),sharey=True)
for i in range(len(ax)):
ax[i].scatter(X_train[:,i],y_train, label = 'target')
ax[i].set_xlabel(X_features[i])
ax[i].scatter(X_train[:,i],y_pred,color=dlorange, label = 'predict')
ax[0].set_ylabel("Price"); ax[0].legend();
fig.suptitle("target versus prediction using z-score normalized model")
plt.show()

恭喜
在这个实验中,你:利用开源机器学习工具包scikit-learn使用该工具包中的梯度下降和特征归一化实现线性回归
实验二
目标
在本实验中,你将:利用scikit-learn实现基于正态方程的近似解线性回归
工具
您将使用scikit-learn中的函数以及matplotlib和NumPy
import numpy as np
np.set_printoptions(precision=2)
from sklearn.linear_model import LinearRegression, SGDRegressor
from sklearn.preprocessing import StandardScaler
from lab_utils_multi import load_house_data
import matplotlib.pyplot as plt
dlblue = '#0096ff'; dlorange = '#FF9300'; dldarkred='#C00000'; dlmagenta='#FF40FF'; dlpurple='#7030A0';
plt.style.use('./deeplearning.mplstyle')
线性回归,闭式解
Scikit-learn具有线性回归模型,实现了封闭形式的线性回归。让我们使用早期实验室的数据——一个1000平方英尺的房子卖了30万美元,一个2000平方英尺的房子卖了50万美元。
加载数据集
X_train = np.array([1.0, 2.0]) #features
y_train = np.array([300, 500]) #target value
创建并拟合模型
下面的代码使用scikit-learn执行回归。第一步创建一个回归对象。第二步使用与对象相关的方法之一fit。这将执行回归,将参数拟合到输入数据。该工具包需要一个二维X矩阵。
linear_model = LinearRegression()
#X must be a 2-D Matrix
linear_model.fit(X_train.reshape(-1, 1), y_train)

查看参数
在scikit-learn中,w和b参数被称为“系数”和“截距”
b = linear_model.intercept_
w = linear_model.coef_
print(f"w = {w:}, b = {b:0.2f}")
print(f"'manual' prediction: f_wb = wx+b : {1200*w + b}")

作出预测
调用predict函数生成预测。
y_pred = linear_model.predict(X_train.reshape(-1, 1))
print("Prediction on training set:", y_pred)
X_test = np.array([[1200]])
print(f"Prediction for 1200 sqft house: ${linear_model.predict(X_test)[0]:0.2f}")

第二个例子
第二个例子来自早期的一个具有多个特征的实验。最终的参数值和预测非常接近该实验室非标准化“长期”的结果。这种不正常的运行需要几个小时才能产生结果,而这几乎是瞬间的。封闭形式的解决方案在诸如此类的较小数据集上工作得很好,但在较大的数据集上可能需要计算。
封闭形式的解不需要规范化
# load the dataset
X_train, y_train = load_house_data()
X_features = ['size(sqft)','bedrooms','floors','age']
linear_model = LinearRegression()
linear_model.fit(X_train, y_train)

b = linear_model.intercept_
w = linear_model.coef_
print(f"w = {w:}, b = {b:0.2f}")

这里的权重1和权重4,相对于权重2和权重3太小,不知道为什么这里不舍去
print(f"Prediction on training set:\n {linear_model.predict(X_train)[:4]}" )
print(f"prediction using w,b:\n {(X_train @ w + b)[:4]}")
print(f"Target values \n {y_train[:4]}")
x_house = np.array([1200, 3,1, 40]).reshape(-1,4)
x_house_predict = linear_model.predict(x_house)[0]
print(f" predicted price of a house with 1200 sqft, 3 bedrooms, 1 floor, 40 years old = ${x_house_predict*1000:0.2f}")
 文章来源:https://www.toymoban.com/news/detail-839797.html
文章来源:https://www.toymoban.com/news/detail-839797.html
恭喜
在这个实验中,你:利用开源机器学习工具包scikit-learn使用该工具包中的接近形式的解决方案实现线性回归文章来源地址https://www.toymoban.com/news/detail-839797.html
到了这里,关于吴恩达机器学习-可选实验:使用ScikitLearn进行线性回归(Linear Regression using Scikit-Learn)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!