目录
3.爬虫身份识别
4.用户爬虫的例子
4.1 开源爬虫
网络爬虫的组成
控制器
解析器
资源库
3.爬虫身份识别
网络爬虫通过使用http请求的用户代理(User Agent)字段来向网络服务器表明他们的身份。网络管理员则通过检查网络服务器的日志,使用用户代理字段来辨认哪一个爬虫曾经访问过以及它访问的频率。用户代理字段可能会包含一个可以让管理员获取爬虫更多信息的URL。邮件抓取器和其他怀有恶意的网络爬虫通常不会留任何的用户代理字段内容,或者他们也会将他们的身份伪装成浏览器或者其他的知名爬虫。
对于网路爬虫,留下用户标志信息是十分重要的;这样,网络管理员在需要的时候就可以联系爬虫的主人。有时,爬虫可能会陷入爬虫陷阱或者使一个服务器超负荷,这时,爬虫主人需要使爬虫停止。对那些有兴趣了解特定爬虫访问时间网络管理员来讲,用户标识信息是十分重要的。
4.用户爬虫的例子
以下是一系列已经发布的一般用途的网络爬虫(除了主题检索的爬虫)的体系结构,包括了对不同组件命名和突出特点的简短的描述。
RBSE(Eichmann,1994)是第一个发布的爬虫。它有两个基础程序。第一个是“spider”,抓取队列中的内容到一个关系数据库中,第二个程序是“mite”,是一个修改后的www的ASCII浏览器,负责从网络上下载页面。
WebCrawler(Pinkerton,1994)是第一个公开可用的,用来建立全文索引的一个子程序,他使用库www来下载页面;另外一个程序使用广度优先来解析获取URL并对其排序;它还包括一个根据选定文本和查询相似程度爬行的实时爬虫。
World Wide Web Worm(McBryan,1994)是一个用来为文件建立包括标题和URL简单索引的爬虫。索引可以通过grep式的Unix命令来搜索。
Google Crawler(Brin and Page,1998)用了一些细节来描述,但是这些细节仅仅是关于使用C++和Python编写的、一个早期版本的体系结构。因为文本解析就是全文检索和URL抽取的过程,所以爬虫集成了索引处理。这里拥有一个URL服务器,用来给几个爬虫程序发送要抓取的URL列表。在文本解析的时候,新发现的URL传送给URL服务器并检测这个URL是不是已经存在,如果不存在的话,该URL就加入到URL服务器中。
CobWeb(da Silva et al.,1999)使用了一个中央“调度者”和一系列的“分布式的搜集者”。搜集者解析下载的页面并把找到的URL发送给调度者,然后调度者反过来分配给搜集者。调度者使用深度优先策略,并且使用平衡礼貌策略来避免服务器超载。爬虫是使用Perl语言编写的。
Mercator(Heydon and Najork,1999;Najork and Heydon,2001)是一个分布式的,模块化的使用java编写的网络爬虫。它的模块化源自于使用可互换的的“协议模块”和“处理模块”。协议模块负责怎样获取网页(例如使用HTTP),处理模块负责怎样处理页面。标准处理模块仅仅包括了解析页面和抽取URL,其他处理模块可以用来检索文本页面,或者搜集网络数据。
WebFountain(Edwards et al.,2001)是一个与Mercator类似的分布式的模块化的爬虫,但是使用C++编写的。它的特点是一个管理员机器控制一系列的蚂蚁机器。经过多次下载页面后,页面的变化率可以推测出来,这时,一个非线性的方法必须用于求解方程以获得一个最大的新鲜度的访问策略。作者推荐在早期检索阶段使用这个爬虫,然后用统一策略检索,就是所有的页面都使用相同的频率访问。
PolyBot(Shkapenyuk and Suel,2002)是一个使用C++和Python编写的分布式网络爬虫。它由一个爬虫管理者,一个或多个下载者,一个或多个DNS解析者组成。抽取到的URL被添加到硬盘的一个队列里面,然后使用批处理的模式处理这些URL。平衡礼貌方面考虑到了第二、三级网域,因为第三级网域通常也会保存在同一个网络服务器上。
WebRACE(Zeinalipour-Yazti and Dikaiakos,2002)是一个使用java实现的,拥有检索模块和缓存模块的爬虫,它是一个很通用的称作eRACE的系统的一部分。系统从用户得到下载页面的请求,爬虫的行为有点像一个聪明的代理服务器。系统还监视订阅网页的请求,当网页发生改变的时候,它必须使爬虫下载更新这个页面并且通知订阅者。WebRACE最大的特色是,当大多数的爬虫都从一组URL开始的时候,WebRACE可以连续地的接收抓取开始的URL地址。
Ubicrawer(Boldi et al.,2004)是一个使用java编写的分布式爬虫。它没有中央程序。它由一组完全相同的代理组成,分配功能通过主机前后一致的散列计算进行。这里没有重复的页面,除非爬虫崩溃了(然后,另外一个代理就会接替崩溃的代理重新开始抓取)。爬虫设计为高伸缩性和允许失败的。
FAST Crawler(Risvik and Michelsen,2002)是一个分布式的爬虫,在Fast Search&Transfer中使用,关于其体系结构的一个大致的描述可以在[citation needed]找到。
Labrador,一个工作在开源项目Terrier Search Engine上的非开源的爬虫。
TeezirCrawler是一个非开源的可伸缩的网页抓取器,在Teezir上使用。该程序被设计为一个完整的可以处理各种类型网页的爬虫,包括各种JavaScript和HTML文档。爬虫既支持主题检索也支持非主题检索。
Spinn3r,一个通过博客构建反馈信息的爬虫。Spinn3r是基于java的,它的大部分的体系结构都是开源的。
HotCrawler,一个使用c语言和php编写的爬虫。
ViREL Microformats Crawler,搜索公众信息作为嵌入到网页的一小部分。
除了上面列出的几个特定的爬虫结构以外,还有Cho(Cho and Garcia-Molina,2002)和Chakrabarti(Chakrabarti,2003)发布的一般的爬虫体系结构。
4.1 开源爬虫
DataparkSearch是一个在GNU GPL许可下发布的爬虫搜索引擎。
GNU Wget是一个在GPL许可下,使用C语言编写的命令行式的爬虫。它主要用于网络服务器和FTP服务器的镜像。
Heritrix是一个互联网档案馆级的爬虫,设计的目标为对大型网络的大部分内容的定期存档快照,是使用java编写的。
Ht://Dig在它和索引引擎中包括了一个网页爬虫。
HTTrack用网络爬虫创建网络站点镜像,以便离线观看。它使用C语言编写,在GPL许可下发行。
ICDL Crawler是一个用C++编写,跨平台的网络爬虫。它仅仅使用空闲的CPU资源,在ICDL标准上抓取整个站点。
JSpider是一个在GPL许可下发行的,高度可配置的,可定制的网络爬虫引擎。
LLarbin由Sebastien Ailleret开发;
Webtools4larbin由Andreas Beder开发;
Methabot是一个使用C语言编写的高速优化的,使用命令行方式运行的,在2-clause BSD许可下发布的网页检索器。它的主要的特性是高可配置性,模块化;它检索的目标可以是本地文件系统,HTTP或者FTP。
Nutch是一个使用java编写,在Apache许可下发行的爬虫。它可以用来连接Lucene的全文检索套件;
Pavuk是一个在GPL许可下发行的,使用命令行的WEB站点镜像工具,可以选择使用X11的图形界面。与wget和httprack相比,他有一系列先进的特性,如以正则表达式为基础的文件过滤规则和文件创建规则。
WebVac是斯坦福WebBase项目使用的一个爬虫。
WebSPHINX(Miller and Bharat,1998)是一个由java类库构成的,基于文本的搜索引擎。它使用多线程进行网页检索,html解析,拥有一个图形用户界面用来设置开始的种子URL和抽取下载的数据;
WIRE-网络信息检索环境(Baeza-Yates和Castillo,2002)是一个使用C++编写,在GPL许可下发行的爬虫,内置了几种页面下载安排的策略,还有一个生成报告和统计资料的模块,所以,它主要用于网络特征的描述;
LWP:RobotUA(Langheinrich,2004)是一个在Perl5许可下发行的,可以优异的完成并行任务的Perl类库构成的机器人。
Web Crawler是一个为.net准备的开放源代码的网络检索器(C#编写)。
Sherlock Holmes收集和检索本地和网络上的文本类数据(文本文件,网页),该项目由捷克门户网站中枢(Czech web portal Centrum)赞助并且主用商用于这里;它同时也使用在。
YaCy是一个基于P2P网络的免费的分布式搜索引擎(在GPL许可下发行);
Ruya是一个在广度优先方面表现优秀,基于等级抓取的开放源代码的网络爬虫。在英语和日语页面的抓取表现良好,它在GPL许可下发行,并且完全使用Python编写。按照robots.txt有一个延时的单网域延时爬虫。
Universal Information Crawler快速发展的网络爬虫,用于检索存储和分析数据;
Agent Kernel,当一个爬虫抓取时,用来进行安排,并发和存储的java框架。
是一个使用C#编写,需要SQL Server 2005支持的,在GPL许可下发行的多功能的开源的机器人。它可以用来下载,检索,存储包括电子邮件地址,文件,超链接,图片和网页在内的各种数据。
Dine是一个多线程的java的http客户端。它可以在LGPL许可下进行二次开发。
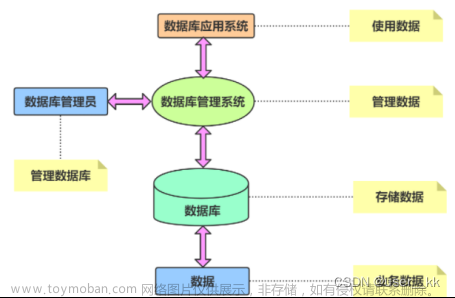
网络爬虫的组成
在网络爬虫的系统框架中,主过程由控制器,解析器,资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行页面的处理,主要是将一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库是用来存放下载到的网页资源,一般都采用大型的数据库存储,如Oracle数据库,并对其建立索引。
控制器
控制器是网络爬虫的中央控制器,它主要是负责根据系统传过来的URL链接,分配一线程,然后启动线程调用爬虫爬取网页的过程。
解析器
解析器是负责网络爬虫的主要部分,其负责的工作主要有:下载网页的功能,对网页的文本进行处理,如过滤功能,抽取特殊HTML标签的功能,分析数据功能。文章来源:https://www.toymoban.com/news/detail-839964.html
资源库
主要是用来存储网页中下载下来的数据记录的容器,并提供生成索引的目标源。中大型的数据库产品有:Oracle、Sql Server等。文章来源地址https://www.toymoban.com/news/detail-839964.html
到了这里,关于数据界的达克摩斯之剑----深入浅出带你理解网络爬虫(Forth)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!