1、介绍下YARN?
YARN是Apache Hadoop生态系统中的一个集群资源管理器。它的主要目的是管理和分配集群中的资源,并为运行在Hadoop集群上的应用程序提供资源。
YARN的架构基于两个主要组件:ResourceManager(资源管理器)和NodeManager(节点管理器)。
- ResourceManager:ResourceManager负责整个集群的资源管理和调度。它接收来自客户端的应用程序提交请求,并根据可用资源进行分配。ResourceManager也负责监控集群中的资源使用情况,并在需要时进行重新分配。
- NodeManager:每个集群节点上运行一个NodeManager,它负责管理该节点上的资源。NodeManager通过与ResourceManager通信,报告节点上的资源使用情况,并接收来自ResourceManager的指令,如分配任务或释放资源。NodeManager还负责监控已分配该节点的任务,并在需要时重新启动失败的任务。
YARN的工作流程如下:
- 应用程序提交:用户通过客户端向ResourceManager提交应用程序。应用程序可以是MapReduce作业,也可以是其它基于YARN的应用程序。
- 资源分配:ResourceManager根据可用资源和调度策略,为应用程序分配所需的资源。资源可以是CPU、内存或其它可用的集群资源。
- 任务执行:每个节点上的NodeManager接收来自ResourceManager的任务分配,并在该节点上启动和管理任务的执行。
- 监控和容错:ResourceManager和NodeManager定期报告资源使用情况和任务状态,以确保集群的稳定运行。如果某个任务失败,NodeManager会重新启动它,以保证应用程序的容错性。失败,NodeManager会重新启动它==,以保证应用程序的容错性。
2、YARN有几个模块?
YARN有三个主要的模块:
- ResourceManager:ResourceManager负责整个集群的资源管理和调度。它接收来自客户端的应用程序提交请求,并根据可用资源进行分配。ResourceManager也负责监控集群中的资源使用情况,并在需要时进行重新分配。
- NodeManager:每个集群节点上运行一个NodeManager,它负责管理该节点上的资源。NodeManager通过与ResourceManager通信,报告节点上的资源使用情况,并接收来自ResourceManager的指令,如分配任务或释放资源。NodeManager还负责监控已分配该节点的任务,并在需要时重新启动失败的任务。
- ApplicationMaster(应用程序管理器):每个应用程序都有一个ApplicationMaster,它是应用程序内部的主管。ApplicationMaster与ResourceManager通信,协调应用程序的资源请求和任务执行。它还监控应用程序的进度,并在必要时向ResourceManager请求更多的资源。
-
容器(Container):是一种封装了资源(如CPU、内存)的概念,它是YARN中任务运行的基本单位。ResourceManager将资源分配给应用程序管理器时,会创建容器来运行应用程序的任务。
除了这三个核心模块之外,YARN还包括一些其它的组件,如Application Timeline Server(应用程序时间线服务器)。
3、YARN工作机制?
YARN的工作机制是通过ResourceManager和NodeManager的配合,实现集群资源的管理、分配和调度,以及应用程序的执行和监控。ApplicationMaster在每个应用程序中起到协调和管理的作用,而容器则是任务执行的基本单位。
4、YARN高可用?
YARN是Hadoop生态系统中的一个资源管理器,负责管理和分配集群中的资源。YARN的高可用性指的是在出现故障或节点失效时,YARN能够自动切换到备用节点,保证集群的稳定运行。
为了实现YARN的高可用性,可用采用以下措施:
- 启用ZooKeeper:YARN使用ZooKeeper来协调和管理集群的状态。通过在YARN配置中指定ZooKeeper的地址,YARN可以与ZooKeeper进行通信,并在主节点故障时自动切换到备用节点。
- 配置主备节点:YARN的高可用性需要配置一个主节点和一个备用节点。主节点负责处理请求和资源分配,而备用节点在主节点失效时接管其职责。配置主备节点需要在YARN的配置文件中指定相关的参数。
- 启用自动故障转移:YARN支持自动故障转移,即在主节点失效时自动将其职责转移到备用节点。这需要在YARN的配置文件中启用自动故障转移的参数,并指定备用节点的地址。
- 监控和警报:为了实现YARN的高可用性,需要对集群进行监控,并在主节点失效时及时发出警报。可以使用监控工具如Ambari、Nagios等来监控YARN集群的状态,并配置警报规则,以便在出现故障时及时采取措施。
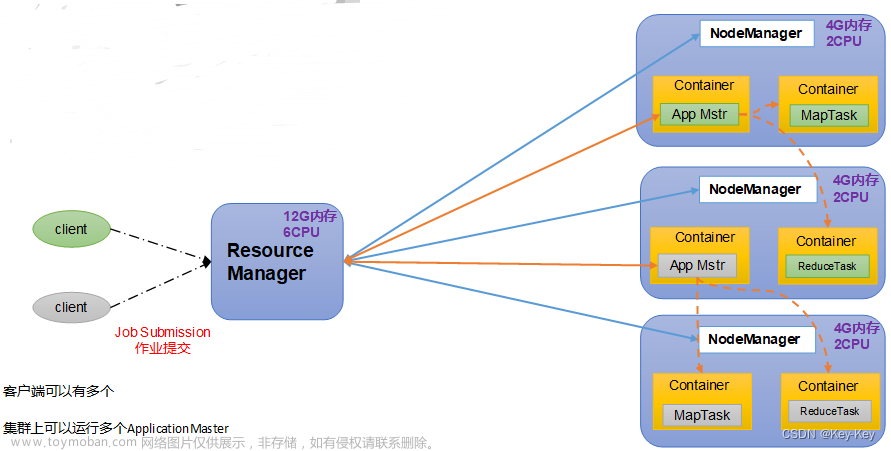
5、YARN中Container是如何启动的?
在YARN中,Container是由NodeManager启动的。当ResourceManager接收到一个应用程序的提交请求后,它会为该应用程序分配一个ApplicationMaster。然后,ApplicationMaster会向ResourceManager请求资源,并且ResourceManager会为其分配一个或多个Container。
一旦ResourceManager分配了Container,NodeManager会根据ResourceManager提供的资源和配置信息启动Container。NodeManager会在一个可用的节点上创建一个进程来运行Container,并且在Container中启动应用程序的执行环境。这个执行环境可能是一个Java虚拟机(JVM)或者其它编程语言的运行时环境,取决于应用程序的要求。
Container启动后,ApplicationMaster将与其进行通信,并在Container中运行应用程序的任务。任务的执行将在Container中进行,知道任务完成或者遇到错误。
6、YARN的改进之处,Hadoop3.x相对于Hadoop2.x?
Hadoop3.x相对于Hadoop2.x在YARN方面有以下改进之处:
- 资源管理器(ResourceManager)的高可用性:Hadoop3.x引入了ResourceManager的高可用性特性,通过在集群中运行多个ResourceManager实例,并使用ZooKeeper进行故障转移和状态同步,提供了更可靠的资源管理。
- 资源调度的改进:Hadoop3.x引入了容器级别的资源调度,可以更精确地管理任务地资源需求。它还引入了资源类型,可以根据任务的需求分配不同类型的资源,如CPU、内存、磁盘等。
- 路由器(Router)的引入:Hadoop3.x引入了YARN Router,它可以在不同的YARN集群之间进行路由,使得不同集群之间的资源可以互相访问和共享。
- 容器级别的本地化:Hadoop3.x引入了容器级别的本地化特性,可以在容器级别上进行数据本地化,提高数据访问的效率。
- 资源隔离的改进:Hadoop3.x引入了分级队列的概念,可以更细粒度地对任务进行资源隔离和优先级管理。
7、Hive中如何调整Mapper和Reducer的数目?
在Hive中,我们可以通过设置以下两个参数来调整Mapper和Reducer的数目:
- mapreduce.jop.maps:这个参数用于设置Mapper的数目。你可以通过设置一个具体的数值来指定Mapper的数量,或者使用一个百分比来根据输入数据的大小动态确定Mapper的数量。
例如,设置为具体的数值:
SET mapreduce.job.maps=10;
或者设置为百分比:
SET mapreduce.job.maps=0.25;
- mapreduce.job.reduces:这个参数用于设置Reducer的数目。同样,你可以设置一个具体的数值或者使用一个百分比来确定Reducer的数量。
例如,设置为具体的数值:
SET mapreduce.job.reduces=5;
或者设置为百分比:
SET mapreduce.job.reduces=0.5;
8、Hive的mapjoin?
Hive的mapjoin是一种优化技术,用于加快Hive查询的速度。它通过将小表加载到内存中,然后再Map阶段将大表的数据与小表的数据进行连接,从而减少了磁盘读写操作和网络传输开销。
Hive的mapjoin分为两种类型:
- Map端的mapjoin(Map-side Join):当一个表的数据量足够小,可以将其全部加载到内存中时,Hive会将这个表的数据复制到所有的Map任务中,然后在Map任务中直接进行连接操作。这样可以避免Shuffle阶段的数据传输和磁盘I/O,大大提高了查询速度。
- Bucket Map端的mapjoin(Bucket Map-side Join):当两个表都被分桶(Bucketing)时,Hive可以使用Bucket Map端的mapjoin。两个表都根据某种方式被划分成多个桶(Bucket),通常是基于某个列的哈希值。Hive会将相同编号的桶从两个表中分配到同一个Map任务中。因为数据已经预先分桶,所以这样做可以确保所有必须连接的数据都已经在同一个Map任务中,不需要额外的Shuffle过程将数据从一个节点传输到另一个节点。
需要注意的是,使用mapjoin的前提是小表可以完全加载到内存中,否则可能会导致内存不足的问题。此外,mapjoin也只使用于等值连接(Equi-Join),不支持其它类型的连接操作。
9、Hive使用的时候会将数据同步到HDFS,小文件问题怎么解决的?
在Hive中,解决小文件问题有以下几种方式:
- 合并小文件:使用Hive的合并小文件命令(如’ALTER TABLE <table_name> CONCATENATE’)将多个小文件合并为一个较大的文件。这样可以减少HDFS上的小文件数量,提高查询性能。
- 动态分区:使用Hive的动态分区功能,可以根据数据的某些列值自动创建分区,将数据按照分区存储,减少小文件的数量。可以使用’INSERT OVERWRITE TABLE <table_name>’ PARTITION (<partition_column>) SELECT * FROM …'语句来实现。
- 压缩数据:使用Hive支持的压缩算法(如Snappy、Gzip等)对数据进行压缩,减小存储空间占用,同时减少小文件数量。
- 合理设置参数:通过调整Hive的相关参数,如’hive.merge.mapfiles’、'hive.merge.mapredfiles’等,来控制Hive在写入数据时自动合并小文件的行为。
- 使用分桶(Bucketing):将表按照指定的列进行分桶,将数据分散存储在不同的桶中,减少小文件的数量。
10、Hive的SQL转换为MapReduce的过程?
Hive的SQL查询语句会被转换为MapReduce的过程如下:文章来源:https://www.toymoban.com/news/detail-840037.html
- 解析器(Parser):Hive首先使用解析器将SQL查询语句解析为抽象语法树。AST表示查询的结构和语法,以便后续的处理。
- 语义分析器:在这一步,Hive的语义分析器会对AST进行处理。它会检查查询中的表、列、函数等是否存在,以及它们之间的关系是否正确。还会检查查询中是否包含合法的语义和操作符。
- 查询优化器:一旦语义分析完成,Hive会使用查询优化器对查询进行优化。优化器会尝试重新组织查询计划,以提高查询的性能。它可能通过选择最佳的连接顺序、选择合适的索引和分区等方式来改进查询执行效率。
- 查询计划生成器:在查询优化完成后,Hive会生成一个查询计划。查询计划是一个逻辑计划,它描述了如何从输入数据中获取所需的结果。查询计划通常以操作符树的形式表示,每个操作符代表一个转换或操作步骤。
- 物理计划生成器:在生成了逻辑查询计划后,Hive会使用物理计划生成器将逻辑计划转换为物理计划。物理计划描述了如何在MapReduce框架中执行查询。它会将查找转换为一系列的Map和Reduce任务,并定义它们之间的数据流和依赖关系。
- MapReduce作业提交:最后,Hive将生成的物理计划转换为MapReduce作业,并提交给底层的MapReduce框架执行。MapReduce框架会根据物理计划的指示,在集群中的节点上执行Map和Reduce任务,并将最终的查询结果返回给Hive。
总结起来,Hive将SQL查询语句转换为MapReduce的过程包括解析查询语句、语句分析、查询优化、生成逻辑查询计划、生成物理查询计划以及提交MapReduce作业执行。文章来源地址https://www.toymoban.com/news/detail-840037.html
到了这里,关于大数据开发(Hadoop面试真题-卷八)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!