Java的序列化和反序列化机制
问题导入:
在阅读ArrayList源码的时候,注意到,其内部的成员变量动态数组elementData被Java中的关键字transient修饰
transient关键字意味着Java在序列化时会跳过该字段(不序列化该字段)
而Java在默认情况下会序列化类(实现了Java.io.Serializable接口的类)的所有非瞬态(未被transient关键字修饰)和非静态('未被static关键字修饰')字段
为什么ArrayList要给非常重要的动态数组成员变量elementData添加transient关键字?
事实上,ArrayList给elementData添加transient关键字的原因是因为Java默认的序列化方法并不理想
-
空间效率: 由于扩容机制,
elementData数组的容量可能会大于实际存储的元素数量,数组中可能存在未使用的空间,如果直接走Java默认的序列化,直接序列化整个数组,会将这部分未使用的空间也一起序列化,导致空间浪费 -
控制序列化行为: 通过自定义
writeObject()和readObject()方法,ArrayList能够更好地控制序列化和反序列化过程,仅序列化实际包含的元素,并在反序列化时重新创建合适的数组大小
那么,Java的序列化机制,标识接口Java.io.Serializable和关键字transient等是如何运作的?
从两个类说起
Java中实现序列化和反序列化的两个核心类是ObjectInputStream和ObjectOutputStream
-
ObjectOutputStream:将Java对象的原始数据类型以流的方式写出到文件,实现对象的持久化存储 -
ObjectInputStream:将文件中保存的对象,以流的方式取出来使用
一个简单的示例
//1.创建一个类 实现序列化接口(标识该类可被序列化,如果不实现该接口,调用序列化方法会报java.io.NotSerializableException)
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Person implements Serializable {
private String name;
private Integer age;
//标记remark字段 不会被序列化
private transient String remark;
}
//2.序列化和反序列化演示
@Test
public void test(){
//创建对象
Person person = new Person();
person.setName("void");
person.setAge(26);
person.setRemark("hello world");
//指定 目标位置
String target = "F:\\out\\s.txt";
//序列化 演示
try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(Files.newOutputStream(Paths.get(target)))) {
objectOutputStream.writeObject(person);
} catch (IOException e) {
e.printStackTrace();
}
//反序列化 演示
try (ObjectInputStream objectInputStream = new ObjectInputStream(Files.newInputStream(Paths.get(target)))) {
Person person1 = (Person) objectInputStream.readObject();
log.info("person1:{}", person1);
//person1:Person(name=void, age=26, remark=null) 注意这里的remark字段,有transient关键字修饰和没有是两个结果
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
源码解析
前文说到
-
Serializable起标识作用,标识该类可被序列化,如果不实现该接口,调用序列化方法会报java.io.NotSerializableException -
transient关键字标记的字段不会被序列化
从源码来验证:
Serializable起标识作用原理java.io.ObjectOutputStream#writeObject0()方法中的代码片段
可以看到,如果这个类既不是字符串,数组,枚举类,也没有实现Serializable接口,就会报(NotSerializableException)错
private void writeObject0(Object obj, boolean unshared)
throws IOException
{
...
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
...
}
//...
transient关键字标记的字段不会被序列化原理java.io.ObjectStreamClass.getDefaultSerialFields中的代码片段
这里涉及一种关键的数学和计算机科学知识点,即通过位运算,一个整数能够被精确无误地分解为多个具有唯一确定性的二进制子串。换言之,对于任何整数,我们都可以利用位运算技术将其分割成多个独一无二、确定无疑的二进制表示状态
private static ObjectStreamField[] getDefaultSerialFields(Class<?> cl) {
Field[] clFields = cl.getDeclaredFields();
ArrayList<ObjectStreamField> list = new ArrayList<>();
//注意点1: Modifier 是 Java中用来表示修饰符的一个类 一个整数可以通过位运算聚合多种状态
int mask = Modifier.STATIC | Modifier.TRANSIENT;
for (int i = 0; i < clFields.length; i++) {
//注意点2: 通过位运算与(都是1才是1),判断如果该字段 既不是static修饰也不是transient修饰的字段 就需要序列化
if ((clFields[i].getModifiers() & mask) == 0) {
list.add(new ObjectStreamField(clFields[i], false, true));
}
}
int size = list.size();
return (size == 0) ? NO_FIELDS :
list.toArray(new ObjectStreamField[size]);
}
怎么自定义序列化和反序列化方法?
参考ArrayList源码
//ArrayList中的自定义序列化方法
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
int expectedModCount = modCount;
//注意点1:调用 ObjectOutputStream的默认 序列化方法将该序列化的字段序列化
s.defaultWriteObject();
//注意点2:额外写入数组的实际装了多少元素(不是总容量)
//Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
//注意点3:依次写入数组元素
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
//注意点4:调用ObjectInputStream的默认 反序列化方法将该反序列化的字段反序列化
s.defaultReadObject();
//注意点5:这里读取的值是被忽略的
// Read in capacity
s.readInt(); // ignored
//注意点6: 依次反序列化
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
参考源码注释和补充的批注能大概理解整个流程,但是这里有个地方比较让我疑惑
结合注意点2,和注意点5发现ArrayList在自定义序列化方法额外写入了size
但是反序列化时仅仅只做了读取并没有使用,源码注释也是//ignore,序列化写入的时候也提了一下写入size是为了兼容clone()行为
参考文章https://www.zhihu.com/question/359634731 应该是版本兼容问题
新的问题?为什么写了writeObject()方法和readObject()方法,序列化和反序列化就会按照自定义的来?文章来源:https://www.toymoban.com/news/detail-840159.html
序列化反序列化自定义原理
还是结合源码分析文章来源地址https://www.toymoban.com/news/detail-840159.html
//1.以下为java.io.ObjectOutputStream#writeSerialData()的源码
private void writeSerialData(Object obj, ObjectStreamClass desc)
throws IOException
{
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
//注意点1:这里进行了是否有WriteObject方法的判定
if (slotDesc.hasWriteObjectMethod()) {
PutFieldImpl oldPut = curPut;
curPut = null;
SerialCallbackContext oldContext = curContext;
if (extendedDebugInfo) {
debugInfoStack.push(
"custom writeObject data (class \"" +
slotDesc.getName() + "\")");
}
try {
curContext = new SerialCallbackContext(obj, slotDesc);
bout.setBlockDataMode(true);
slotDesc.invokeWriteObject(obj, this);
bout.setBlockDataMode(false);
bout.writeByte(TC_ENDBLOCKDATA);
} finally {
curContext.setUsed();
curContext = oldContext;
if (extendedDebugInfo) {
debugInfoStack.pop();
}
}
curPut = oldPut;
} else {
defaultWriteFields(obj, slotDesc);
}
}
}
//2.进入方法 slotDesc.hasWriteObjectMethod()
boolean hasWriteObjectMethod() {
requireInitialized();
//注意点2:这里对成员变量writeObjectMethod 进行了判断 以此为依据来确定类是否含有writeObject方法 什么时候赋值的?(初始化)
return (writeObjectMethod != null);
}
//3.在java.io.ObjectStreamClass.ObjectStreamClass(java.lang.Class<?>)类构造方法中 进行了初始化
private ObjectStreamClass(final Class<?> cl){
...
if(externalizable){
cons=getExternalizableConstructor(cl);
}else{
cons=getSerializableConstructor(cl);
//注意点3:这里使用了反射机制为成员变量writeObjectMethod是否含有方法writeObject方法进行了赋值判定
writeObjectMethod=getPrivateMethod(cl,"writeObject",
new Class<?>[]{ObjectOutputStream.class },
Void.TYPE);
readObjectMethod=getPrivateMethod(cl,"readObject",
new Class<?>[]{ObjectInputStream.class },
Void.TYPE);
readObjectNoDataMethod=getPrivateMethod(
cl,"readObjectNoData",null,Void.TYPE);
hasWriteObjectData=(writeObjectMethod!=null);
}
...
}
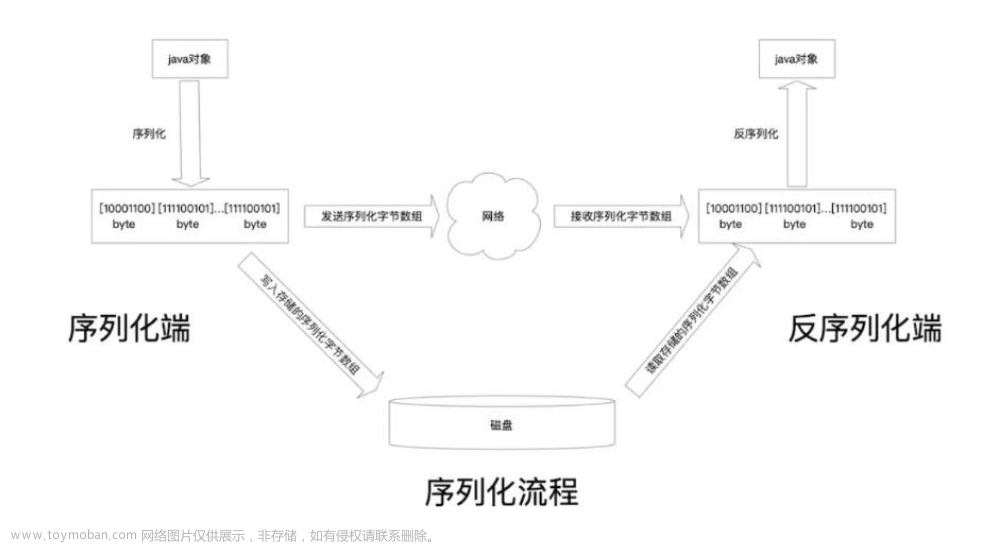
到了这里,关于Java序列化和反序列化机制的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[计算机网络]---序列化和反序列化](https://imgs.yssmx.com/Uploads/2024/02/830228-1.png)