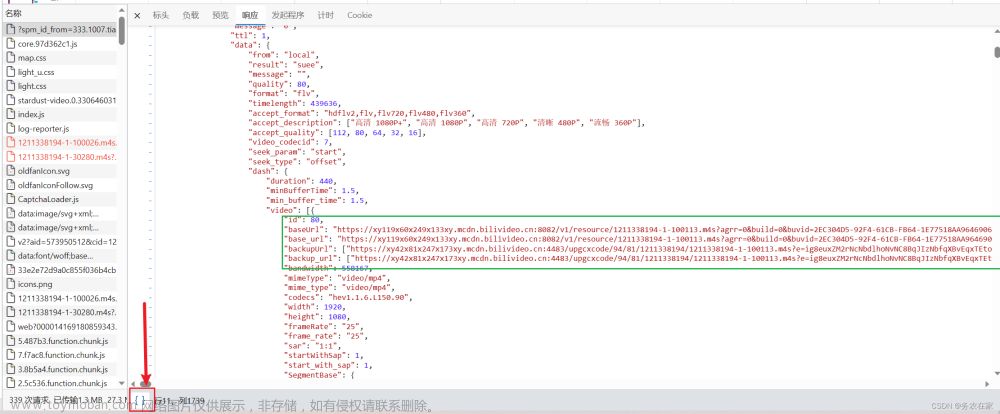
接口分析
获取接口地址
选择自己感兴趣的抖音博主,本次以“经典老歌【车载U盘】”为例
每次请求的页面会有很多接口,需要对接口进行筛选:
第一步筛选XHR筛选
第二步筛选URL中带有post

通过筛选play_add值找到视频的地址


分析请求头
通过对比两次请求发现只有X-Bogus数值会有变化,max_cursor是用翻页,后文再介绍。

JS逆向分析
找入口
先通过简单方式搜索关键字找:

在当前两个位置增加断点,发现并没有断到请求,说明没有走两个位置
通过开发者工具中中的启动器定位:

断第一个,发现这是个ajax请求,不止一个请求会走这里,通过XHR断点的方式指定访问路径



上图就是当前的访问URL。 在控制端输入this或者鼠标悬停方式发现已生成X-Bogus

分析前一步调用的js

这段代码是一个简单的循环语句。它根据 _0x2458f0['y'] 的值来执行不同的逻辑。
在每次循环中,它首先对 _0x2458f0['y'] 进行自增操作(++),然后使用逻辑运算符 ? : 进行条件判断:
如果条件为真,执行 _0xcc6308[++_0x2e1055] = _0x2458f0['apply'](_0xc26b5e, _0x1f1790);
如果条件为假,不执行任何操作。
这段代码的具体意义需要结合上下文来进行分析和理解,无法单独判断出它的功能和目的。
通过日志断点来分析当前_0x2458f0['apply'](_0xc26b5e, _0x1f1790)语句生成的结果。日志断点语句console.log(_0x2458f0['apply'](_0xc26b5e, _0x1f1790))。控制台只允许显示信息类数据,通过日志分析找到了X-Bogus参数:DFSzswVOljJANtOstup5PBt/pL3I

由于输出数据过多需要通过条件断点来继续追踪,因为每次生成的X-Bogus长度是固定28位,通过条件断点语句_0x2458f0['apply'](_0xc26b5e, _0x1f1790).length==28。
查看_0x2458f0调用的函数

定位到加密函数

验证当前加密函数
当前位置打上断点,在控制台输入返回的值生成了X-Bogus

JS实现生成X-Bogus值
新建JS文件,将webmssdk.es5.js中所有代码复制到js文件中,并直接执行,差什么补什么

以下是需要加入的代码
window = global
document = {}
document.addEventListener =function (){}
这时候就会发现不再报错了,那么就可以使用一个全局变量获取X-Bogus值了,找到之前加密的函数_0x5a8f25那里。

再补一次
navigator = {
"userAgent":'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'
}

Python调用js
import execjs
with open("douyin.js") as f:
js_data = f.read()
js_compile =execjs.compile(js_data)
xb_data =js_compile.call("window.xiaoc",)
print(xb_data)

Python获取视频URL
获取页面信息
import execjs,requests
headers = {
# UA 要和JS代码里的UA保持一致
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
"Referer": "https://www.douyin.com/user/MS4wLjABAAAAF0zlK2_5qCr5Lqy6zLNMH8W146aOetdfKSX95jYXwi8",
"Cookie": "xxxxxx"
}
with open("douyin.js") as f:
js_data = f.read()
js_compile =execjs.compile(js_data)
url = "https://www.douyin.com/aweme/v1/web/aweme/post/?"
params =f'device_platform=webapp&aid=6383&channel=channel_pc_web&sec_user_id=MS4wLjABAAAAF0zlK2_5qCr5Lqy6zLNMH8W146aOetdfKSX95jYXwi8&max_cursor=0&locate_query=false&show_live_replay_strategy=1&need_time_list=1&time_list_query=0&whale_cut_token=&cut_version=1&count=18&publish_video_strategy_type=2&pc_client_type=1&version_code=170400&version_name=17.4.0&cookie_enabled=true&screen_width=1707&screen_height=1067&browser_language=zh-CN&browser_platform=Win32&browser_name=Chrome&browser_version=119.0.0.0&browser_online=true&engine_name=Blink&engine_version=119.0.0.0&os_name=Windows&os_version=10&cpu_core_num=16&device_memory=8&platform=PC&downlink=7.9&effective_type=4g&round_trip_time=50&webid=7310230678028846631&msToken=XWdh8ZPfrgSs9QombFXY3DJxXhH3HTyjw7NtYb6tpW9wYpaZqIAuhcZmOtQBu-7qgnSFswVdEZ2cKWsg6A4_WkxwyxIH3CCuMoLOUh4H6iqGBk7-ba8jaBufrmt2jw=='
xb_data =js_compile.call("window.xiaoc",params)
urls = url +params + "&X-Bogus=" + xb_data
print(urls)
response = requests.get(url=urls,headers=headers)
print(response.json())

###数据清洗 获取视频URL ```python douyin_videos = response.json().get("aweme_list") for douyin_video in douyin_videos: print(douyin_video["video"]['play_addr']['url_list'][0]) ```

下载视频
os.makedirs(f"./DouYin/")
douyin_videos = response.json().get("aweme_list")
for douyin_video in douyin_videos:
douyin_video_title =douyin_video['desc']
douyin_video_url = douyin_video["video"]['play_addr']['url_list'][0]
res = requests.get(douyin_video_url, headers=headers)
try:
with open(f"./DouYin/{douyin_video_title}.mp4", "wb") as f:
f.write(res.content)
print(f"视频{douyin_video_title}-----下载完成")
except Exception as e:
print(f"视频{douyin_video_title}+++++++++++++++=下载出错 {e}")
 文章来源:https://www.toymoban.com/news/detail-840227.html
文章来源:https://www.toymoban.com/news/detail-840227.html
 文章来源地址https://www.toymoban.com/news/detail-840227.html
文章来源地址https://www.toymoban.com/news/detail-840227.html
到了这里,关于【Python爬虫案例】抖音下载视频+X-Bogus参数JS逆向分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!