目录
一、炸裂函数的知识点
1.1 炸裂函数
explode
posexplode
1.2 lateral view 侧写视图
二、实际案例
2.1 每个学生及其成绩
0 问题描述
1 数据准备
2 数据分析
3 小结
2.2 日期交叉问题
0 问题描述
1 数据准备
2 数据分析
3 小结
2.3 用户消费金额
0 问题描述
1 数据准备
2 数据分析
3 小结
一、炸裂函数的知识点
炸裂函数(一行变多行)本质属于UDTF函数(接收一行数据,输出一行或者多行数据)。
1.1 炸裂函数
-
explode
(1)explode(array<T> a) --> explode针对数组进行炸裂
语法:lateral view explode(split(a,',')) tmp as new_column
返回值:string
说明:按照分隔符切割字符串,并将数组中内容炸裂成多行字符串
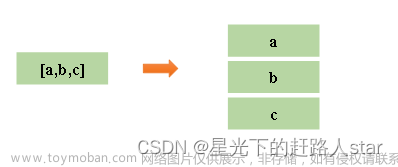
举例:select student_score from test lateral view explode(split(student_score,',')) tmp as item; 输出结果为:
student_score item
[a,b,c] => a
b
c
(2)explode(map<k,v> m) --> explode针对map键值对进行炸裂
举例:select explode(map('a',1,'b',2,'c',3)) as (key,value); 输出结果为:
得到 key value
{a:1,b:2,c:3} => a 1
b 2
c 3-
posexplode
posexplode和explode之间的区别:posexplode除了返回数据,还会返回该值的下角标。
(1)posexplode(array<T> a)
语法:lateral view posexploed(split(a,',')) tmp as pos,item
返回值:string
说明:按照分隔符切割字符串,并将数组中内容炸裂成多行字符串(炸裂具备下角标 0,1,2,3)
举例1:select posexplode (array('a','b','c')) as pos,item; 输出结果为:
pos item
[a,b,c] => 0 a
1 b
2 c
---------------------------------
举例2:对student_name进行炸裂,同时也对student_score进行炸裂,且需要保证炸裂后,学生和成绩一一对应,不能错乱。
lateral view posexplode(split(student_name,',')) tmp1 as student_name_index,student_name
lateral view posexplode(split(student_score,',')) tmp2 as student_score_index,student_score
where student_name_index = student_score_index;1.2 lateral view 侧写视图
官网链接:LanguageManual LateralView - Apache Hive - Apache Software Foundation
- 定义:lateral view 通常与UDTF配合使用,侧视图的原理是将UDTF的结果构建成一个类似于视图的表,再将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。
- 举例:select id, name, hobbies, hobby from person lateral view explode(hobbies) tmp as hobby; 代码分析: 对原表person中的hobbies列进行炸裂(一行变多行),利用侧视图lateral view对该UDTF产生的记录设置字段名称为hobby, 再将原表中person的一每行与hobby进行连接形成一个虚拟表,命名为tmp。
- 注意:使用lateral view时侧写视图时,可以对UDTF产生的记录设置字段名称,上述例子为hobby,产生的hobby字段可以用于group by、order by 、limit等语句中,不需要再单独嵌套一层子查询
二、实际案例
2.1 每个学生及其成绩
0 问题描述
根据学生成绩表,计算学生的成绩。
1 数据准备
create table if not exists table10
(
class string comment '班级名称',
student string comment '学生名称',
score string comment '学生分数'
)
comment '学生成绩表';
INSERT overwrite table table10
VALUES ("1班","小A,小B,小C","80,92,70"),
("2班","小D,小E","88,62"),
("3班","小F,小G,小H","90,97,85");2 数据分析
思路一:lateral view + explode
select
class,
student,
score,
student_name,
student_score
from table10 lateral view explode(split(student, ',')) tmp1 as student_name
lateral view explode(split(score, ',')) tmp2 as student_score;
bug:上面逻辑能跑通,但是学生姓名和学生成绩对应不上,出现错乱,弃用。
正确的代码如下:
思路二: lateral view + posexplode
select
class,
student,
score,
student_name,
student_score
from table10 lateral view posexplode(split(student, ',')) tmp3 as student_index_st, student_name
lateral view posexplode(split(score, ',')) tmp4 as student_index_sc, student_score
where student_index_st = student_index_sc;
说明:student_index_st = student_index_sc 的作用:下角标对齐,实现学生和成绩一一对应
3 小结
上述案例的学生成绩表中,【学生姓名】字段和【学生成绩】都是数组类型的字符串,我们需要对两个字段分别炸裂后,实现每个学生与其成绩一一对应,因此需要借助posexlode函数的pos下角标进行约束。(用explode函数无法实现)
2.2 日期交叉问题
0 问题描述
统计每个品牌的总营销天数(营销日期有重叠的地方需要去重)
1 数据准备
create table promotion_info
(
promotion_id string comment '优惠活动id',
brand string comment '优惠品牌',
start_date string comment '优惠活动开始日期',
end_date string comment '优惠活动结束日期'
) comment '各品牌活动周期表';
insert overwrite table promotion_info
values (1, 'oppo', '2021-06-05', '2021-06-09'),
(2, 'oppo', '2021-06-11', '2021-06-21'),
(3, 'vivo', '2021-06-05', '2021-06-15'),
(4, 'vivo', '2021-06-09', '2021-06-21'),
(5, 'redmi', '2021-06-05', '2021-06-21'),
(6, 'redmi', '2021-06-09', '2021-06-15'),
(7, 'redmi', '2021-06-17', '2021-06-26'),
(8, 'huawei', '2021-06-05', '2021-06-26'),
(9, 'huawei', '2021-06-09', '2021-06-15'),
(10, 'huawei', '2021-06-17', '2021-06-21');2 数据分析
思路一:用带有下标的炸裂函数posexplode将活动区间炸裂成具体的每一天的日期。即:将同一个品牌的所有活动日期都有列出来,再对重叠的日期进行统一去重
select brand,
count(distinct event_date)
from
(
select
promotion_id,
brand,
start_date,
-- 用 start_date + 下角标pos
date_add(start_date,pos) as event_date,
pos
from (
select
promotion_id,
brand,
start_date,
end_date,
split(space(datediff(end_date, start_date)), '') as ar
from promotion_info
) tmp1
lateral view posexplode(ar) tmp2 as pos, item
)tmp2
group by brand;
思路一的代码拆解分析:
以一条数据为例,
promotion_id brand start_date end_date
1 'oppo' '2021-06-05' '2021-06-09'
(1) split(space(datediff(end_date, start_date)), '') as diff 的结果:
根据[9-5]=4,利用space函数生成长度是4的空格字符串,再利用split函数切割
1 (promotion_id) , 'oppo'(brand) , '2021-06-05'(start_date) ,'2021-06-09'(end_date)
, diff ["","","","",""]
(2)用posexplode经过转换增加行(列转行,炸裂),通过下角标pos来获取 event_date,
根据数组["","","","",""],得到pos的取值是0,1,2,3,4
炸裂得出下面五行数据(一行变五行)
1,oppo,2021-06-05(start_date),2021-06-05= date_add(2021-06-05,0) (event_date= start_date+pos)
1,oppo,2021-06-05(start_date),2021-06-06= date_add(2021-06-05,1) (event_date= start_date+pos)
1,oppo,2021-06-05(start_date),2021-06-07 = date_add(2021-06-05,2) (event_date= start_date+pos)
1,oppo,2021-06-05(start_date),2021-06-07 = date_add(2021-06-05,3) (event_date= start_date+pos)
1,oppo,2021-06-05(start_date),2021-06-08 = date_add(2021-06-05,4) (event_date= start_date+pos)
1,oppo,2021-06-05(start_date),2021-06-09 = date_add(2021-06-05,5) (event_date= start_date+pos)
炸裂的目的:活动的优惠时间段[ '2021-06-05' , '2021-06-09' ] 拆分成具体的每一天event_date: '2021-06-05','2021-06-06','2021-06-07','2021-06-08','2021-06-09'
(3)根据品牌brand进行分组,求count(distinct event_date) ,从而得到每品牌的总营销天数(营销日期有重叠的地方已经去重了)思路二:用带有下标的炸裂函数posexplode
select brand,
count(distinct event_date)
from
(
select
promotion_id,
brand,
start_date,
date_add(start_date,pos) as event_date,
pos
from (
select
promotion_id,
brand,
start_date,
end_date,
split(repeat(',',datediff(end_date, start_date)),',') as ar
from promotion_info
) tmp1
lateral view posexplode(ar) tmp2 as pos, item
)tmp2
group by brand;思路二的代码拆解分析:跟思路一的逻辑基本是一样的 ,区别仅在于:用代码 split(repeat(',',datediff(end_date, start_date)),',') as ar 去替换 split(space(datediff(end_date, start_date)), '') as ar
思路三的代码逻辑如下:
select
brand,
--对品牌brand分组求sum的原因:同一个用户可能对应多段不交叉的活动
sum(datediff(end_date, new_start_date) + 1) days
from (
select
brand,
new_start_date,
end_date
from (
select
brand,
--判断逻辑:1.如果max_end_date是null(意味着当前行就是首行,不存在上一行了),直接取start_date
--2.如果max_end_date不是null,进一步判断【当前行】的start_date与max_end_date的大小,如果start_date小,那用max_date+ 1的值作为【当前行】的新new_start_date
if(max_end_date is null, start_date,
if(start_date > max_end_date, start_date, date_add(max_end_date, 1))) new_start_date,
end_date
from (
select
brand,
start_date,
end_date,
-- 开窗范围:同一个品牌内部:上无边界到截止到上一行
-- 开窗的计算逻辑:max(end_date) --> 对【上无边界到上一行】的最大结束时间end_date进行标记,再与当前行的起始时间start_date进行比对
max(end_date)
over (partition by brand order by start_date rows between unbounded preceding and 1 preceding) max_end_date
from promotion_info
) t1
) t2
-- 需要保证每行数据的新的起始时间new_start_date 比 结束时间end_date 小
where new_start_date < end_date
) t3
group by brand;思路三:没有用到炸裂函数,关键思想是:当活动的上一个日期区间A 与 当前的日期区间B出现重叠(日期交叉,有重复数据)时,需要将区间B的起始时间改成区间A的结束时间。(修改之后需要保证B区间的结束时间> 开始时间)
3 小结
上述代码中用到的函数有:
一、字符串函数
1、空格字符串函数:space
语法:space(int n)
返回值:string
说明:返回值是n的空格字符串
举例:select length (space(10)) --> 10
一般space函数和split函数结合使用:select split(space(3),''); --> ["","","",""]
2、split函数(分割字符串)
语法:split(string str,string pat)
返回值:array
说明:按照pat字符串分割str,会返回分割后的字符串数组
举例:select split ('abcdf','c') from test; -> ["ab","df"]
3、repeat:重复字符串
语法:repeat(string A, int n)
返回值:string
说明:将字符串A重复n遍。
举例:select repeat('123', 3); -> 123123123
一般repeat函数和split函数结合使用:select split(repeat(',',4),','); -->
["","","","",""]
二、炸裂函数
explode
语法:lateral view explode(split(a,',')) tmp as new_column
返回值:string
说明:按照分隔符切割字符串,并将数组中内容炸裂成多行字符串
举例:select student_score from test lateral view explode(split(student_score,','))
tmp as student_score
posexplode
语法:lateral view posexploed(split(a,',')) tmp as pos,item
返回值:string
说明:按照分隔符切割字符串,并将数组中内容炸裂成多行字符串(炸裂具备瞎下角标 0,1,2,3)
举例:select student_name, student_score from test
lateral view posexplode(split(student_name,',')) tmp1 as student_name_index,student_name
lateral view posexplode(split(student_score,',')) tmp2 as student_score_index,student_score
where student_score_index = student_name_index
2.3 用户消费金额
0 问题描述
变更需求:table11表的第1,4列不表,第2列需要变更为连续日期,第3列需要变更成当日累积消费额
1 数据准备
create table if not exists table11
(
user_id string comment '用户标识',
dt string comment '消费日期',
price string comment '消费金额',
qs int comment '用户应存期数'
)
comment '用户消费详情表';
INSERT overwrite table table11
VALUES ("A","2018-12-21","9439.30",12),
("A","2019-03-21","9439.30",12),
("A","2019-06-21","9439.30",12),
("A","2019-09-21","9439.30",12),
("B","2018-12-02","9439.30",10),
("B","2019-02-02","9439.30",10),
("B","2019-06-02","9439.30",10);2 数据分析
-- 思路一:利用posexplode函数进行炸裂,同时生成下角标pos,
--将消费区间(一行)炸裂成对应的每天的消费日期(多行)
select
tmp3.user_id,
tmp3.event_dt,
-- sum() over(partition by .. order by .. ) 窗口计算的范围是:上无边界(起始行)到当前行,求消费金额的累积值(order by 后面没有窗口子句的情况下,窗口范围是:上无边界(起始行)到当前行)
cast(sum(tmp4.price) over (partition by tmp3.user_id order by tmp3.event_dt) as decimal(18, 2)) as price,
tmp3.max_qs
from (
select
user_id,
add_months(min_dt, pos) as event_dt,
max_qs,
pos
from (
select
user_id,
min(dt ) as min_dt,
max(price) max_price,
max(qs) max_qs
from table11
group by user_id
) tmp1 lateral view posexplode(split(space(max_qs), '')) tmp2 as pos, item
) tmp3
left join (select
user_id,
ds,
price
from table11) tmp4
on tmp3.user_id = tmp4.user_id and tmp3.new_ds = tmp4.ds;
3 小结
利用posexplode的下角标pos进行填补连续。利用sum(price)over(partition by ..order by)进行消费金额的累积值统计(截止到当日)
(1)lateral view posexplode(split(space(max_qs), '')) tmp2 as pos, item;-->对字段 期数ds进行posexplode炸裂,一行变多行,且生成对应的下角标pos
(2)add_months(min_ds, pos) as new_ds; --> 基于min_dt + pos对消费日期 进行填补,组成连续的消费日期区间。文章来源:https://www.toymoban.com/news/detail-840364.html
待补充:炸裂的弊端是可能会发生数据膨胀,当数据集小的时候,用炸裂方便,当时数据集大时,需慎用。文章来源地址https://www.toymoban.com/news/detail-840364.html
到了这里,关于HiveSQL题——炸裂函数(explode/posexplode)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!